Clear Sky Science · tr
Açıklanabilir hibrit CNN–transformer modeli: uyarlamalı birleştirme ve bilgi damıtma kullanarak uç cihazlarda işaret dili tanıma
Neden küçük işaret dili araçları önemli
Milyarlarca günlük iletişim, konuşulan kelimelerden ziyade el hareketleri, yüz ifadeleri ve beden diline dayanır. Yine de çoğu telefon, tablet ve kamusal cihaz hâlâ işaret dillerini anlayamaz, özellikle İngilizce konuşulan ülkelerin dışında. Bu makale, düşük güçlü küçük cihazlarda gerçek zamanlı çalışacak şekilde tasarlanmış, kompakt ve açıklanabilir bir işaret dili tanıma sistemi olan TinyMSLR’yi tanıtıyor. Amaç, sıradan donanımı dünyanın dört bir yanındaki İşitme engelli ve işitme güçlüğü çeken insanlar için uygun fiyatlı, güvenilir iletişim yardımcısına dönüştürmek.
Sohbete daha çok dil katmak
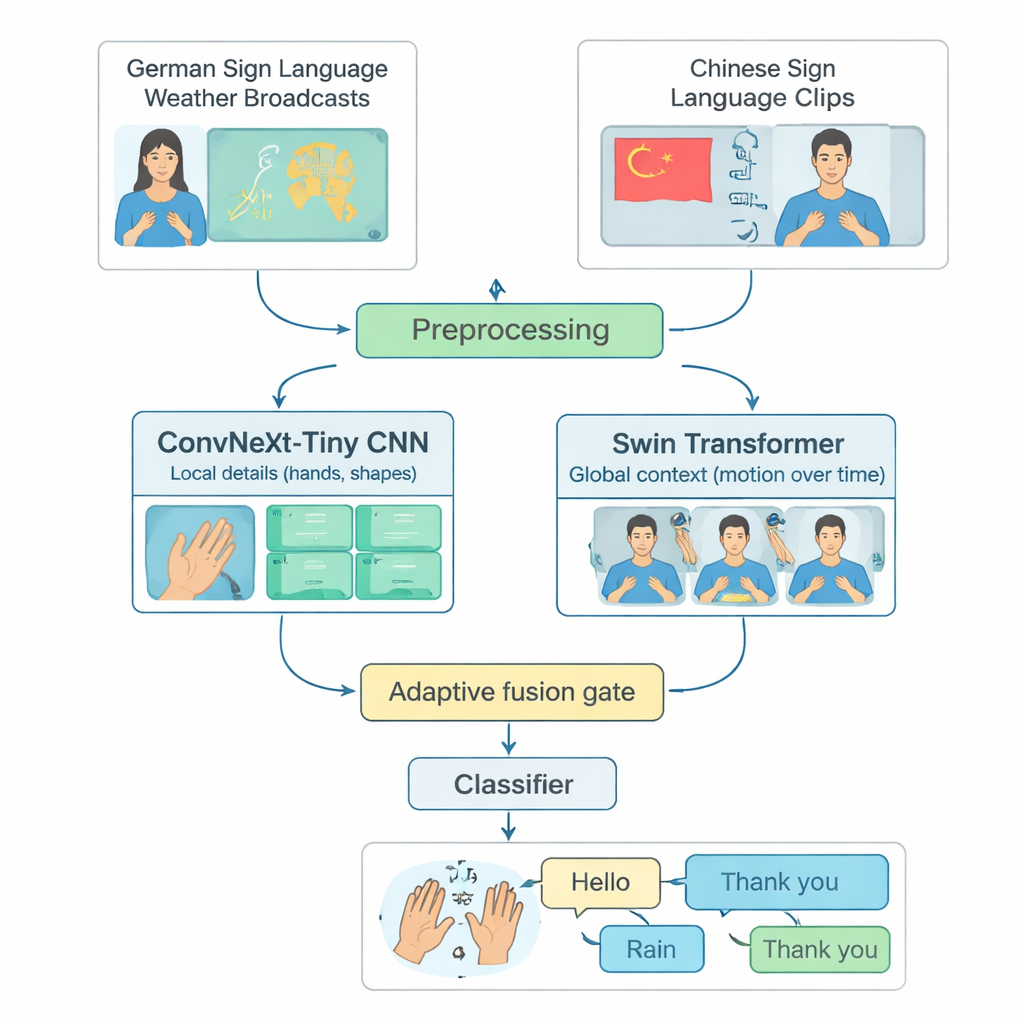
Birçok gelişmiş işaret dili tanıma sistemi tek bir dile, çoğunlukla Amerikan İşaret Diline odaklanır ve yalnızca güçlü bilgisayarlarda çalışır. Bu, diğer işaret dillerini kullanan veya sınırlı hesaplama kaynakları olan bölgelerde yaşayan insanları dışlar. Yazarlar, bu boşluğu iki farklı dilden oluşan paylaşılan bir test yatağı kurarak ele alıyor: Almanca İşaret Dili hava durumu yayınları ve geniş bir Çin İşaret Dili koleksiyonu. Her iki dilde de bulunan Merhaba, Hava, Yağmur, Mutlu, Evet ve Teşekkür ederim gibi 20 yaygın günlük işareti dikkatle seçiyorlar. Uzun videoları tek bir işaret içeren kısa kliplere kırparak ve sınıf başına ve imzalayan başına örnek sayısını dengeleyerek, bir modelin diller arası izole işaretleri ne kadar iyi tanıyabildiğini adil ve yeniden üretilebilir bir biçimde değerlendirecek bir yöntem oluşturuyorlar.
Hibrit model elleri ve hareketi nasıl görüyor
TinyMSLR videoya bakmanın birbirini tamamlayan iki yolunu birleştirir. Bir dalga ince ayrıntıları—parmak şekilleri ve ince doku gibi—saptamada üstün olan güncel bir evrişimli ağ (ConvNeXt‑Tiny) kullanılır. İkinci dalga ise birkaç kare boyunca ellerin, yüzün ve üst bedenin nasıl hareket ettiğini izlemekte güçlü olan daha yeni bir model ailesi olan Swin Transformer’ı kullanır. Her kısa video klip 32 kareye ve 224×224 piksele standartlaştırılır, hafifçe artırılır (örneğin küçük döndürmeler veya parlaklık değişiklikleri) ve ardından her iki dala paralel olarak beslenir. Her dal gördüklerini 768 elemanlı bir özet olarak üretir; bu iki özet birlikte hem net yerel ayrıntıları hem de daha geniş hareket ve bağlamı yakalar.
Modelin neyin daha önemli olduğuna karar vermesine izin vermek
Bazı işaretler esasen el şekliyle ayırt edilirken diğerleri daha geniş kol hareketlerine veya yüz ipuçlarına dayanabildiğinden TinyMSLR iki görünümünü birleştirmek için tek bir sabit reçete kullanmaz. Bunun yerine, her bir giriş klibi için detay odaklı dala ne kadar, bağlam odaklı dala ne kadar güvenileceğini öğrenen küçük bir “birleştirme kapısı” kullanır. Kapı her iki özellik özetine bakar ve her zaman toplamı bir olan iki ağırlık çıkarır; nihai temsil bu iki ağırlıklı karışım olarak elde edilir. Eğitimde her dal ayrıca kendi küçük sınıflandırıcısını alır, böylece kendi başına faydalı olmayı öğrenir; ve bir CNN ile bir Transformer’dan oluşan çift daha büyük “öğretmen” ağ, yalnızca doğru etiketi göstermeyip hangi alternatif etiketlerin benzer göründüğünü de göstererek küçük modelin yolunu nazikçe gösterir. Bilgi damıtma (knowledge distillation) olarak adlandırılan bu teknik, kompakt sistemin daha büyük modellerin doğruluğuna yaklaşmasına yardımcı olurken boyut ve hızını uç cihazlar için uygun tutar.
Sistemin her kararı neden verdiğini görmek
Ham doğruluğun ötesinde, yazarlar kullanıcıların ve geliştiricilerin modelin neye dikkat ettiğini inceleyebilmesi gerektiğini vurguluyor. Bu amaçla girişin her parçasına bir önem değeri atayan SHAP adlı araç ailesini benimserler. Pratikte, açıklamaları ara özellikler üzerinde hesaplar ve bunları karelere ısı haritaları ve zamansal grafikler olarak geri eşlerler. Bu, örneğin Yağmur ile Kar veya Soğuk ile Kötü gibi görsel olarak benzer işaretler arasındaki kararı hangi karelerin ve bölgelerin yönlendirdiğini açığa çıkarır. Birçok açıklamayı toplulaştırmak daha geniş örüntüleri gösterir: yüz ifadesi ve baş hareketi gibi manuel olmayan ipuçları ile bilek yönelimi ve el şekli özellikle etkili olarak ortaya çıkar. Bu bulgular, sistemin işaretlemenin anlamlı yönlerine dayanıp arka plan artefaktlarına güvenmediğini doğrulamaya yardımcı olur.

Hız, tutumluluk ve gelişme alanı
20 işaretlik iki dilli kıyaslamada TinyMSLR yaklaşık %99 eğitim ve doğrulama doğruluğuna ve yaklaşık %99 F1 skoruna ulaşırken 2,7 milyondan az parametre ve klip başına yaklaşık 1,9 milyar işlem kullanır. Modern bir GPU’da bir işareti yaklaşık 13,5 milisaniyede işler ve 30 milijoulden daha az enerji harcar; saklanan model sadece yaklaşık 7,2 megabayttır. Bu sayılar gerçek zamanlı, cihaz üzerinde işaret tanımanın düşük maliyetli kartlar ve gömülü sistemlerde mümkün olduğunu düşündürür. Yazarlar dikkatle not eder ki çalışmaları yalnızca kısa, izole işaretleri ve iki dili kapsar ve yüz ifadelerini ayrı bir sinyal olarak değil örtük biçimde ele alır. Yaklaşımın daha zengin sözcük dağarcıklarına, sürekli cümlelere, daha fazla dile ve yüz ile baş hareketlerinin açık modellenmesine genişletilmesi gelecekteki çalışmalar için bırakılmıştır. Yine de TinyMSLR ikna edici bir kavram kanıtı sunar: işaret dillerini anlamaya yönelik doğru, verimli ve yorumlanabilir araçların bulutta sınırlı kalması gerekmez—günlük cihazlarda doğrudan çalışabilirler.
Atıf: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Anahtar kelimeler: işaret dili tanıma, küçük makine öğrenimi, uç yapay zeka, açıklanabilir yapay zeka, çokdilli modeller