Clear Sky Science · tr
Karmaşık bulut‑uç‑son senaryolarda generatif adversaryal taklit öğrenmesi ile DT destekli kaynak tahsisi
Nesnelerin İnterneti için Daha Akıllı Veri Otoyolları
Şehirler, fabrikalar ve evler bağlı sensörler ve cihazlarla doldukça, hızlı ve güvenilir şekilde işlenmesi gereken büyük veri akışları ortaya çıkıyor. Her şeyi uzak bulut sunucularına göndermek yavaş kalabilir; öte yandan “uç”taki küçük cihazlar genellikle yeterli hesaplama gücünden yoksun. Bu makale, akıllı uygulamaların gerçek dünya koşulları karışık ve öngörülemez olsa bile hızlı ve sağlam kalmasını sağlayacak şekilde cihazlar, yakın uç sunucuları ve bulut arasında hesaplama, depolama ve ağ kaynaklarını otomatik olarak yönlendirme ve tahsis etmenin yeni bir yolunu araştırıyor.
Bugünün Yöntemlerinin Neden Zorluk Yaşadığı
Modern sistemler sıklıkla ödül sinyalleriyle çevreden deneme-yanılma yoluyla öğrenen derin pekiştirmeli öğrenmeye dayanır. Ancak karmaşık, gürültülü ağlarda bu ödülleri tanımlamak ve ölçmek zordur. Ödül fonksiyonu yanlış veya parazit nedeniyle bozulmuşsa, sistem güvensiz veya israfcı davranışlar öğrenebilir. Birçok mevcut yöntem ayrıca trafik kalıpları ve cihaz davranışı hakkında zengin önbilgilere dayanmayı varsayar; canlı endüstriyel ağlarda bu nadiren mevcuttur. Buna ek olarak, çoğu çözüm aynı anda yalnızca bir tür kaynağı—örneğin hesaplama gücünü—optimize eder; depolama veya ağ bant genişliği genellikle göz ardı edilir, oysa bu üçü gerçek dünya performansını birlikte belirler.
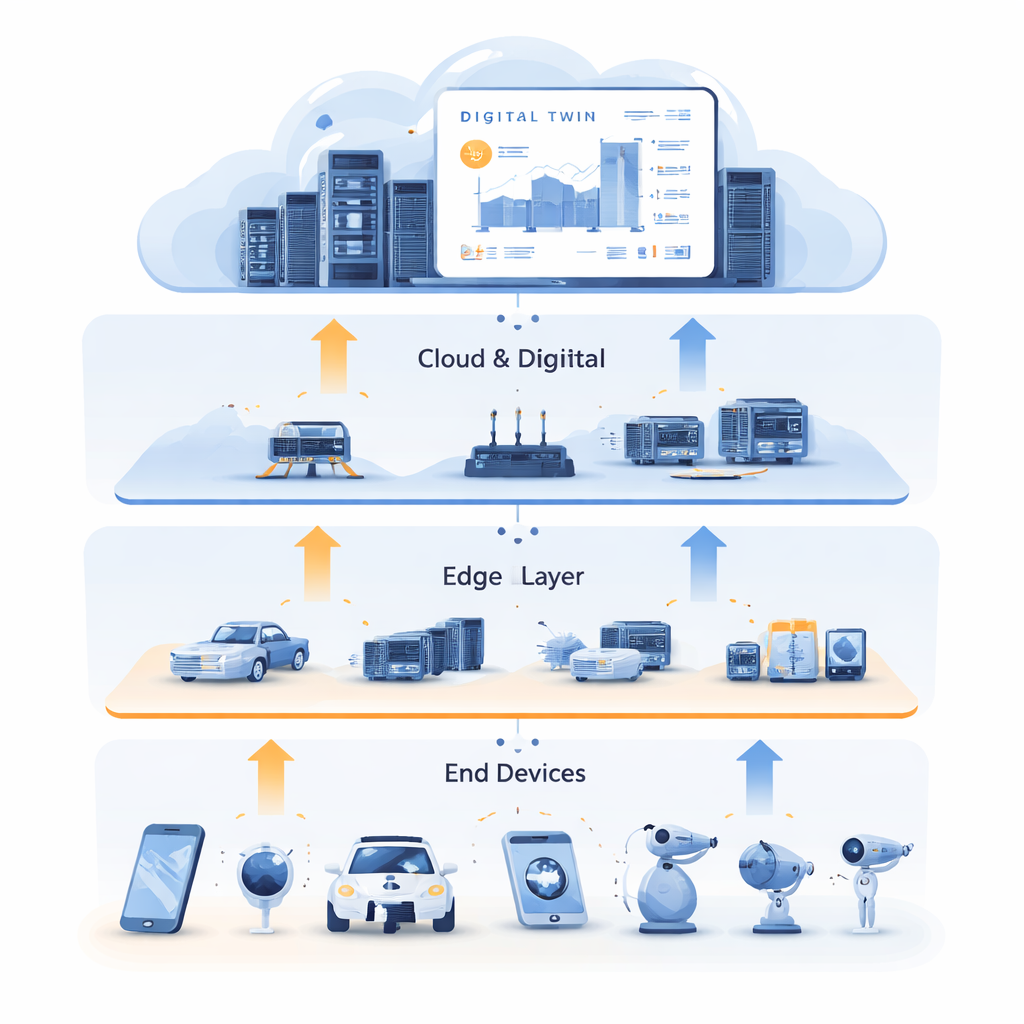
Bir Dijital Çiftten Öğrenme
Bu çıkmazı kırmak için yazarlar kaynak tahsisini Dijital İkiz teknolojisiyle birleştiriyor. Dijital İkiz, fiziksel ağın bulutta tutulan ayrıntılı sanal bir kopyasıdır. Sensörler ve kayıtlar tarafından sağlanan zengin tarihsel verileri kullanarak uç sunucuların, bağlantıların ve görevlerin durumunu zaman içinde yansıtır. Bu çalışmada Dijital İkiz yalnızca bir gösterge panosu değil; eğitim için bir saha haline gelir. Sistem geçmiş verileri kullanarak iyi kararların “uzman” örneklerini üretir; görevlerin hesaplama ve önbellekleme arasında nasıl bölünmesi gerektiğini ve düşük gecikme için nerede işlenmeleri gerektiğini yakalar. Bu eğitim çevrimiçi hizmetleri rahatsız etmeden çevrimdışı olarak gerçekleşir ve bulutun bol hesaplama kaynaklarını pek çok olası durumu keşfetmek için kullanır.
Deneme‑Yanılma Yerine Taklit
Ödüllerden doğrudan öğrenmek yerine, önerilen E‑GAIL modeli taklit öğrenmeyi benimser: ajan bir uzman gibi davranmaya çalışır. İlk olarak yazarlar NoisyNet katmanı ile geliştirilmiş bir Aktör–Kritik çerçevesi kullanarak birden çok uzman politikası oluşturur. Karar ağlarına dikkatle kontrollü gürültü enjekte etmek bu uzmanların gerçek kablosuz paraziti ve dalgalanan iş yüklerini taklit eden bozulmalar da dahil olmak üzere çeşitli koşulları deneyimlemesini sağlar; böylece yolları daha gerçekçi olur. Sonra sistem oyun teorisinden araçlar kullanarak birkaç tek‑uzman yolunu tek bir “çoklu‑uzman” referansında birleştirir. Uzmanlar arasında Nash dengesi arayarak çatışmalardan kaçınır ve olası senaryoların daha geniş kapsamını sağlayan bir fikir birliği stratejisi üretir.
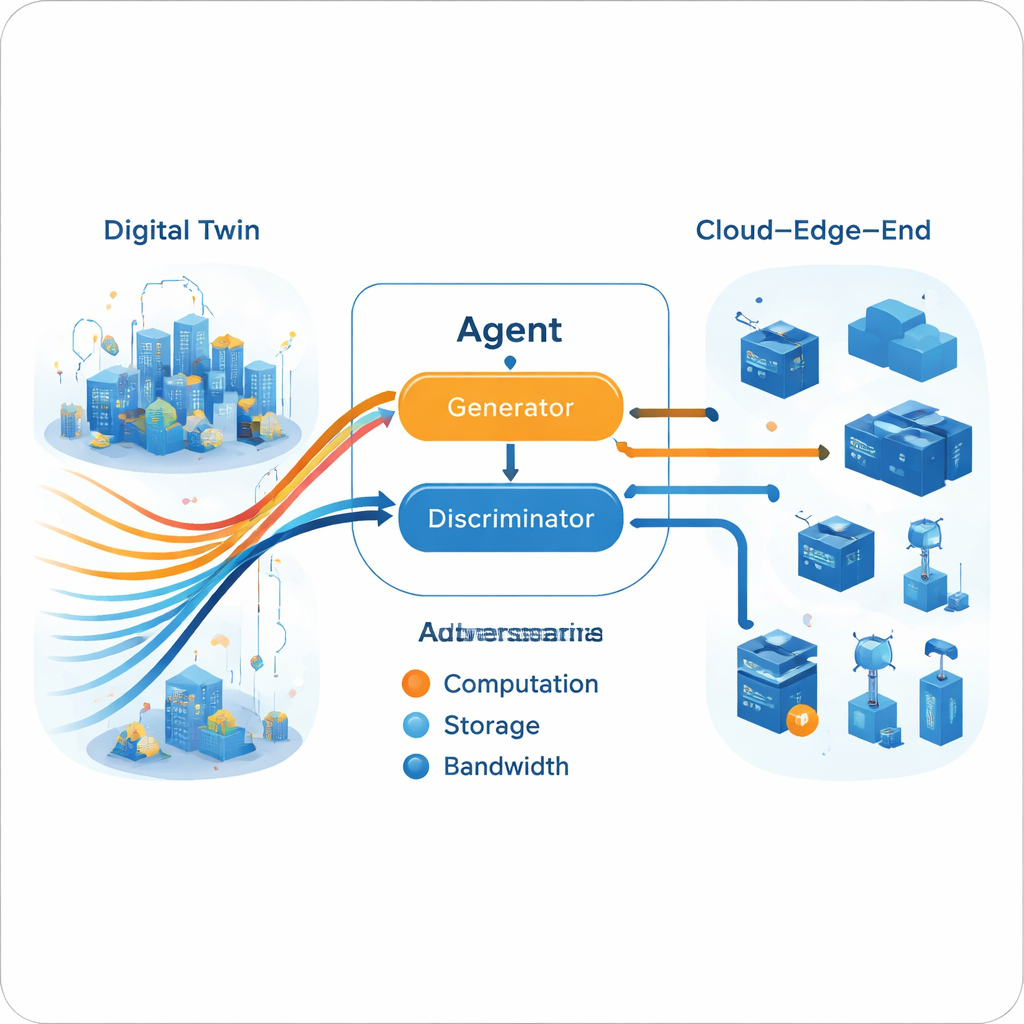
Kararlar için Generatif Adversaryal Bir Motor
Çoklu‑uzman yol oluşturulduktan sonra canlı ajan, görüntü üreten sinir ağlarına benzer bir generatif adversaryal düzenekte bunu taklit etmeyi öğrenir. Bir jeneratör mevcut ağ durumuna göre kaynak tahsis eylemleri önerirken, bir ayrıştırıcı (discriminator) bir eylem dizisinin ajandan mı yoksa uzman yollarından mı geldiğini ayırt etmeye çalışır. Zamanla bu adversaryal oyun jeneratörü ayrıştırıcının uzman davranışından ayırt edemeyeceği kararlar üretmeye zorlar. Önemli olarak, bu süreç gerçek ortamdan açık bir ödül fonksiyonu gerektirmez. Eğitim ikiye ayrılır: çevrimdışı yoğun öğrenme (bulutta) uzmanları ve jeneratörü inceltirken, daha hafif çevrimiçi güncellemeler (uçta) modeli mevcut koşullarla uyumlu tutar ve uç donanımının pratik sınırlarına uyar.
Ne Kadar İyi Çalışıyor?
Yazarlar E‑GAIL’i derin Q‑öğrenme, oyun‑teorik offloading, açgözlü sezgiler, yalnızca bulut işleme ve rastgele tahsis gibi birkaç popüler temel yöntemle karşılaştırır. Uç cihaz sayısı, kanallar, görev karışımları, iş yükleri, veri boyutları, mesafeler ve gürültü desenleri gibi faktörleri değiştirerek yapılan birçok deneyde E‑GAIL, uçtan uca gecikmeleri uzman politikasına çok yakın ve diğer otomatik yöntemlerden belirgin şekilde daha iyi şekilde tutarlı olarak elde eder. Görevler hesaplama‑ağırlıklıdan depolama‑ağırlığına kaydığında, ağ büyüdüğünde veya parazit arttığında iyi adapte olur. Dijital İkiz uzman yollarının üretilmesini hızlandırır ve kalitelerini artırır; çoklu‑uzman füzyonu ise ajanın yeniden baştan eğitmeden ele alabileceği senaryoların kapsamını genişletir.
Günlük Sistemler İçin Anlamı
Uzman olmayan bir kişi için ana mesaj, bu yaklaşımın belirsizlik karşısında ağların kendilerini daha akıllıca yönetmesine izin verdiğidir. Elle yazılmış kurallara veya kırılgan deneme‑yanılma öğrenmesine güvenmek yerine, E‑GAIL Dijital İkiz tarafından sağlanan zengin, simüle edilmiş deneyimlerden ve matematiksel olarak uzlaştırılan birden çok deneyimli “uzmandan” öğrenir. Sonuç, görevleri nerede çalıştıracağına ve verileri nerede depolayacağına hızla karar verebilen bir kaynak tahsis edicidir; koşullar değişse bile tepki sürelerini düşük tutar. Gelecekteki endüstriyel ve akıllı şehir sistemlerinde, böyle kendi kendine öğrenen koordinatörler arka planda hesaplama, depolama ve bant genişliğini sessizce düzenleyerek bağlı dünyamızı daha hızlı, daha güvenilir ve daha enerji verimli hale getirebilir.
Atıf: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Anahtar kelimeler: dijital ikiz, uç bilişim, taklit öğrenmesi, kaynak tahsisi, Endüstriyel Nesnelerin İnterneti