Clear Sky Science · tr
Ağaç budama ormanı ve sınıf dengesizliği için yeniden örnekleme
Akıllı tahminlerde nadir vakalar neden önemli
Yapay zekâ destekli birçok karar, nadir olayı tespit etmeye dayanır: sahte kredi kartı işlemi, hastalığın erken işareti veya bir makinedeki tehlikeli arıza. Bu durumlarda önemli vakalar sıradan olanlara kıyasla çok azdır ve çoğu öğrenme algoritması bunları göz ardı etmeye meyillidir. Bu makale, popüler bir yöntem olan Rastgele Ormanları bu nadir ama kritik vakalara çok daha duyarlı hâle getirmenin —aynı zamanda modeli daha ince ve daha hızlı yapmanın— bir yolunu sunuyor.
Düzensiz örneklerin sorunu
Standart makine öğrenmesi, veriler iyi dengelendiğinde—her sonuç için yaklaşık olarak benzer sayıda örnek olduğunda—en iyi şekilde çalışır. Gerçekte ise birçok görevde nadir olaylar baskındır. Örneğin, tıbbi taramaların yalnızca küçük bir kısmında bir tümör görülür ve işlemlerin yalnızca çok küçük bir payı sahteciliktir. Bu dengesizlik, bir algoritmanın çoğunlukla ortak sonucu tahmin ederek kağıt üstünde iyi görünmesini kolaylaştırır; oysa nadir olanı sıkça kaçırır. Yaygın ve nadir vakalar arasındaki fark büyüdükçe modelin karar sınırı çoğunluğa kayar ve nadir sınıfı tanımak zorlaşır.
Akıllı örneklemeyle dengeleri kurmak
Araştırmacılar bu tür verileri model eğitmeden önce dengelemeye sıklıkla çalışırlar. Bir seçenek çoğunluk sınıfını budamak (alt örnekleme), bazı yaygın vakaları atarak nadir olanlarla sayıyı eşitlemektir. Diğer bir seçenek ise ekstra nadir örnekler kopyalamak veya üretmek (üst örnekleme), böylece orijinal veriyi kaybetmeden bunların varlığını artırmaktır. Üçüncü, hibrit yaklaşım her iki fikri karıştırır; bazı çoğunluk örneklerini keserken azınlığı da güçlendirir. Her taktiğin ödünleri vardır: budamak faydalı bilgileri atma riski taşır, çok sayıda örneği çoğaltmak ise eğitimi yavaşlatabilir ve aşırı uyuma neden olabilir. Yazarlar, eldeki veriye göre daha dengeli eğitim setleri oluşturmak için bu üç stratejinin tümünden faydalanıyorlar.
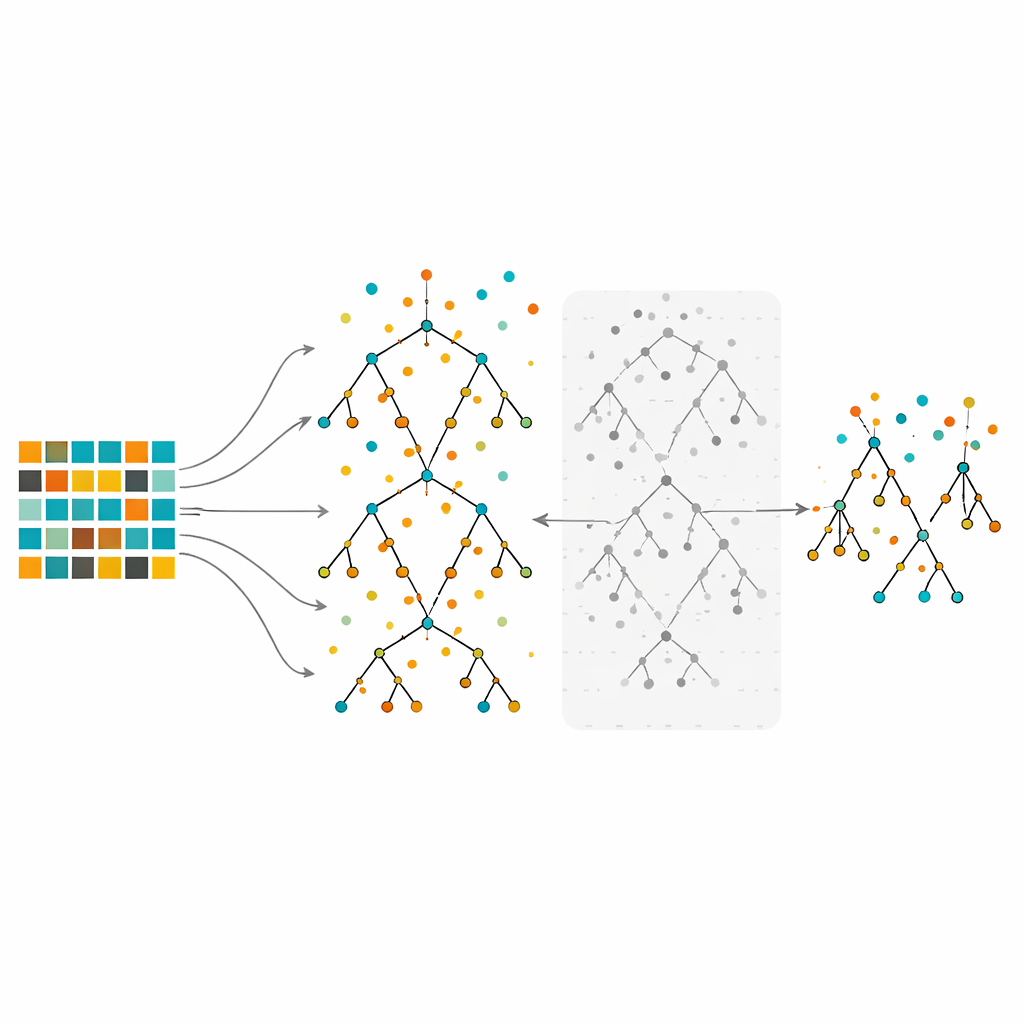
Bir karar ağacı ormanını eğitmek ve budamak
Çalışma, verinin hafifçe farklı dilimleri üzerinde çok sayıda karar ağacı kurup bunların oylarını birleştiren bir topluluk yöntemi olan Rastgele Ormanlara odaklanıyor. Rastgele Ormanlar karmaşık verilerle başa çıkma ve hangi özelliklerin daha önemli olduğunu vurgulama konusunda bilinir. Ancak güçlü biçimde dengesiz verilerle eğitildiğinde, büyük ormanlar bile çoğunluk sınıfına eğilimli olabilir. Önerilen yöntemde yazarlar önce veriyi alt örnekleme, üst örnekleme veya hibrit ile dengeliyor. Ardından sıradan Rastgele Orman prosedürüyle çok sayıda ağaç büyütüyorlar, fakat önemli bir farkla: her ağacı tutmak yerine, her birini o ağacı büyütmek için kullanılmayan gözlemler olan out-of-bag verileriyle değerlendiriyor ve hata oranı en kötü olan yarısını eliyorlar. Bu budama adımı en güvenilir ağaçlardan oluşan daha küçük, daha seçici bir orman veriyor.
Birçok gerçek dünya veri setinde test
Bu budanmış ormanın ne kadar iyi performans gösterdiğini görmek için yazarlar, tıbbi ve biyolojik ölçümlerden e-posta istenmeyen posta filtrelemesine ve ses sınıflandırmaya kadar geniş bir uygulama yelpazesini yansıtan on kamuya açık veri seti üzerinde test ediyorlar. Her veri setinin iki sınıfı var; biri diğerinden açıkça daha nadir ve boyut, özellik sayısı ile dengesizlik derecesi değişiyor. Yeni yöntem, k-en yakın komşu, tek bir karar ağacı, standart bir Rastgele Orman, Balanced Random Forest varyantı ve destek vektör makineleri gibi yaygın kullanılan birkaç yaklaşımla karşılaştırılıyor. Farklı örnekleme stratejileri boyunca, budanmış orman çoğu veri setinde alternatiflere kıyasla tutarlı şekilde daha düşük sınıflandırma hatası elde ediyor. Hibrit örnekleme artı budama kombinasyonu, hem doğruluk açısından hem de on görevin tamamında istikrarlı performans bakımından en iyi genel sonuçları veriyor.
Daha az çabayla daha keskin modeller
Doğruluğun ötesinde, yaklaşım aynı zamanda verimliliği de artırıyor. Daha az etkili ağaçları keserek, nihai topluluk daha küçük oluyor ve tahmin yapmak ile eğitmek için daha az hesaplama gerektiriyor; bu durum nadir vakaları tespit etme yeteneğinden ödün vermeden—çoğunlukla da geliştirerek—sağlanıyor. İstatistiksel testler, rakip yöntemlere kıyasla elde edilen kazançların tesadüfe dayanmadığını doğruluyor. Dengesiz verilerle karşılaşan uygulayıcılar için bu çalışma, eğitim setini dikkatle dengeleyip ardından out-of-bag performansa göre bir Rastgele Ormanı budamanın hem daha doğru hem de daha verimli modeller sağlayabileceğini gösteriyor. Günlük ifadeyle, yöntem algoritmalarımızın sıradan örnek denizinde saklı olan nadir ama önemli sinyallere hak ettiği dikkati vermesine yardımcı oluyor.
Atıf: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Anahtar kelimeler: sınıf dengesizliği, rastgele orman, yeniden örnekleme, makine öğrenmesi, topluluk yöntemleri