Clear Sky Science · tr
NeuroAction: otonom araçlar için pekiştirmeli öğrenmede nöroevolüsyoner bir yaklaşım
Neden daha akıllı sürüş tarzları önemli
Çoğumuz kendi kendine giden arabaları sakin, kusursuz derecede rasyonel sürücüler olarak hayal ederiz. Ancak bugünün sistemleri genellikle çarpmamaya ve sizi çabuk bir şekilde varış noktasına ulaştırmaya benzer tek bir amaç bileşimini takip etme eğilimindedir ve bu bileşim mühendisler tarafından sabitlenir. Bu makalede açıklanan NeuroAction, otonom arabalara insan esnekliğine daha yakın bir şey sağlamayı hedefliyor: her seferinde yeniden eğitim yapmadan, dikkatli "bebek var" tarzından hızlı otoyol sürüşüne kadar birçok güvenli sürüş tarzı arasından seçim yapabilme yeteneği.
Tek beden herkese uyar anlayışından çok sayıda güvenli seçeneğe
Günümüzde sürüş için kullanılan derin pekiştirmeli öğrenme sistemleri deneme-yanılma ile öğrenir: yolu gözlemler, direksiyon ve hızlanma gibi eylemler yapar ve hız, güvenlik ve şerit konumu gibi farklı amaçları bir arada karıştıran tek bir sayısal ödül alır. Sistemi ayarlamak için mühendisler o tek ödülü çok dikkatli bir şekilde tasarlamak zorundadır. Hızı fazla önemserlerse araç agresif sürüş yapabilir; güvenliğe aşırı ağırlık verirlerse sürüş sürüncemede kalabilir. Tercihleri sonradan değiştirmek genellikle büyük bir sinir ağını baştan eğitmek anlamına gelir; bu yavaş, bellek-yoğun ve teknik ayarlara duyarlıdır.
Sürüşü basit hedeflere bölmek
NeuroAction bunu, sürüş görevini tek bir hedef yerine birkaç açık amaca bölerek çözer. Çalışmada, aracın sanal sürücüsü üç ayrı ölçüt üzerinden bağımsız şekilde değerlendirilir: güvenli aralık içinde ne kadar hızlı gittiği, sağa (genellikle daha güvenli olan) şeride ne kadar sadık kaldığı ve çarpışmalardan ne kadar kaçındığı. Bunları tek bir skor halinde birleştirmek yerine yöntem bunları ayrı cetveller olarak ele alır. Sahne arkasında, sensör girişini direksiyon ve hız kararlarına çeviren her olası sürüş politikası eşzamanlı olarak bu üç eksen boyunca değerlendirilir.
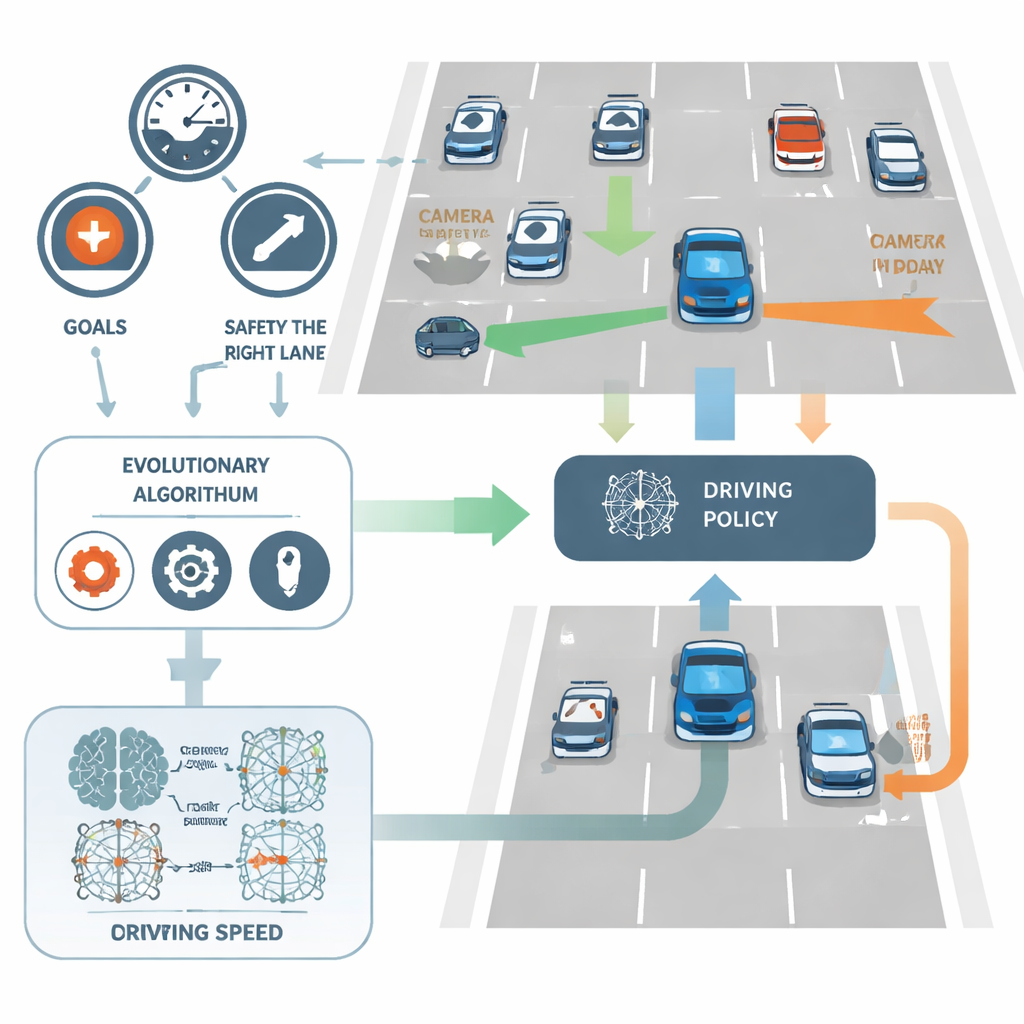
Daha iyi sürücüleri evrimle aramak
Standart geri yayılım tekniğiyle ağ ağırlıklarını ince ayar yapmak yerine NeuroAction biyolojik evrimden ödünç alınan fikirleri kullanır. Farklı sürüş politikalarından oluşan bir popülasyon oluşturulur ve simüle edilmiş bir otoyol ortamında test edilir. Hız, şerit disiplini ve güvenlik arasında iyi takaslar yapan politikalar korunup yeniden birleştirilirken, zayıf olanlar elenir. Nesiller boyunca bu evrimsel süreç güçlü çözümlerin bütünü—Pareto sınırı olarak bilinen—keşfeder; burada hiçbir politika bir hedefte iyileştirilemezken diğerlerinden en az birinden ödün verilmeksizin geliştirilemez.
Evrimsel ve gradyan tabanlı öğrenmeyi karşılaştırmak
Araştırmacılar NeuroAction’u yaygın kullanılan 2B bir otoyol simülatörüne uyguladılar ve standart bir sinir-ağı tabanlı sürüş ajanı kullandılar. Ardından ajanın parametrelerini birkaç yerleşik çok amaçlı evrimsel algoritma ile optimize edip her birinin arzu edilen takasları ne kadar kapsayabildiğini karşılaştırdılar. Keşfedilen sınırın "hipervolüm"ü gibi önemli bir performans ölçüsü, çözümlerin hem ne kadar iyi hem de ne kadar çeşitli olduğunu yakalar. NSGA-II adlı bir algoritma en iyi genel kapsama ulaştı, yakın bir akrabası olan NSGA-III ise yinelemeli çalışmalarda özellikle tutarlı sonuçlar üretti.
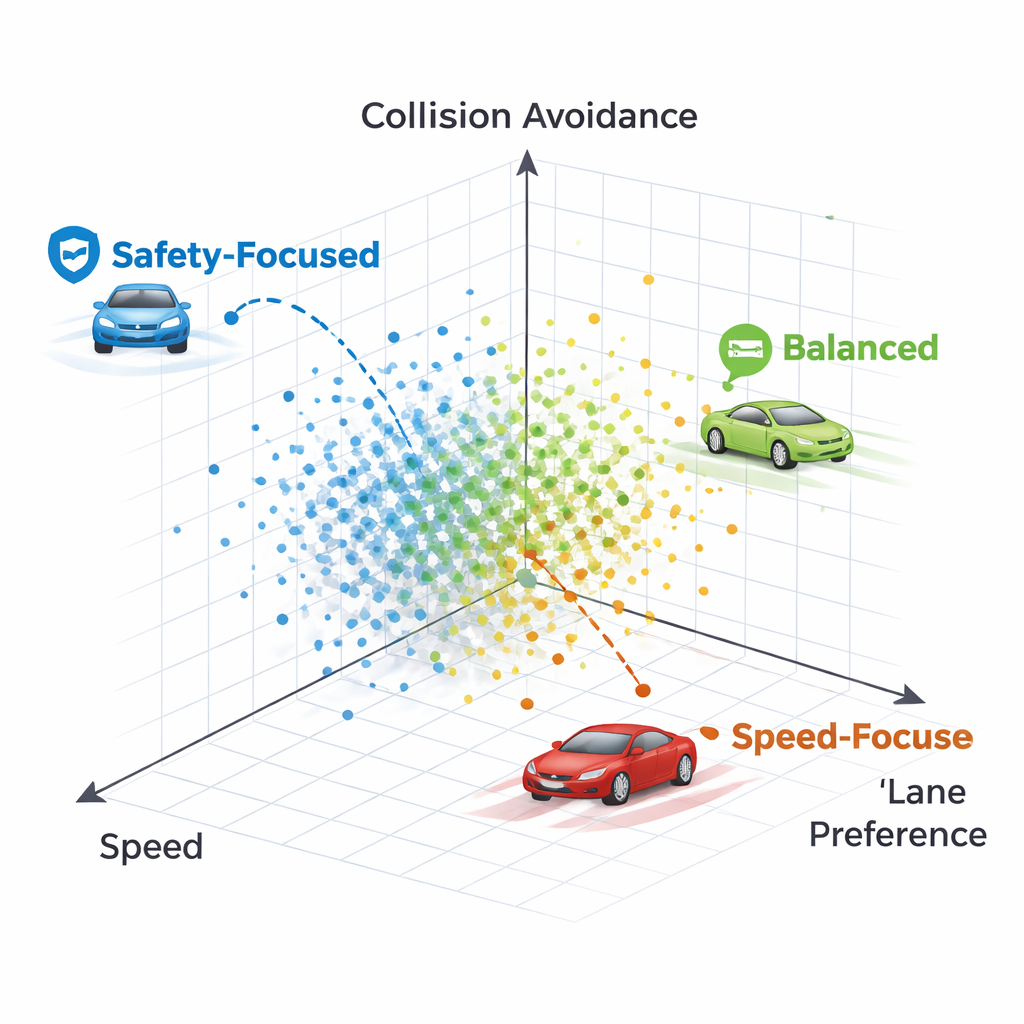
Farklı sürüş stilleri nasıl görünüyor
Pareto sınırı üzerindeki bireysel politikaları inceleyerek yazarlar her noktanın tanınabilir şekilde farklı bir sürüş stiline karşılık geldiğini gösteriyor. Bir politika neredeyse her koşulda sağ şeride sıkı sıkıya bağlı kalarak hızdan ödün veriyor ve sonunda önündeki çok yavaş bir araca çarparak aşırı dikkatli bir strateji sergiliyor—şerit tercihine aşırı önem veren bir yaklaşım. Başka bir politika başlangıçta şerit değiştiriyor ama sonra temiz bir sağ şeride dönerek çarpışmalardan kaçınırken daha yüksek hız koruyor. Genel olarak yöntemler, muhafazakar şerit tutuculardan daha atılgan ama hâlâ güvenli seyredenlere kadar uzanan bir strateji spektrumu üretiyor ve bunların hepsi yeniden eğitim gerektirmeden eşzamanlı olarak kullanılabiliyor.
Bu, geleceğin kendi kendine giden araçları için ne anlama geliyor
Uzman olmayan biri için temel mesaj şudur: NeuroAction kendi kendine giden araçların eğitimini tek bir sabit davranış yerine çok sayıda iyi seçenek arayışına dönüştürüyor. Bu, duruma uygun bir sürüş politikası seçmeyi mümkün kılar—çocuk taşırken yavaş ve son derece güvenli, acele halindeyken daha hızlı—ve yine de güvenlik kısıtlarını gözetir. Mevcut deneyler simülasyon ortamında ve basitleştirilmiş hedefler kullanılarak yapılmış olsa da, bu çerçeve daha uyumlu, tercih-bilinçli otonom araçlara işaret ediyor; kişiselleştirilmiş ama güvenilir sürüş stillerini sağlam temellere dayandırıyor.
Atıf: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Anahtar kelimeler: otonom sürüş, pekiştirmeli öğrenme, evrimsel algoritmalar, çok amaçlı optimizasyon, kendi kendine giden arabalar