Clear Sky Science · tr
Çok etiketli metin duygu tespiti için melez yığılı ansambl öğrenme çerçevesi
Metindeki duyguları okumak neden önemli
Her gün insanlar duygularını sosyal medya gönderilerine, incelemelere ve mesajlara döküyor. Bu sözcük denizinin içinde zihinsel sağlık sorunlarına dair erken uyarılar, artan nefret söylemi ve krizlere ya da felaketlere verilen kamu tepkileri gizlidir. Ancak bilgisayarlar genellikle yalnızca “pozitif” veya “negatif” duygu görür; gerçek insanların sıklıkla aynı anda ifade ettiği duyguların karışımını kaçırırlar. Bu yazı, makinelerin tek bir metinde birden çok duyguyu tanımayı öğrenmesini sağlayan yeni bir yaklaşımı inceliyor ve bunu yalnızca İngilizce’de değil, gelişmiş yapay zekâdan nadiren yararlanan dillerde de yapmayı amaçlıyor.
Basit pozitif/negatif ayrımının ötesine geçmek
Geleneksel duygu analizi araçları kör bir termometre gibidir: ruh halinin iyi mi kötü mü olduğunu söyleyebilirler, ancak aynı anda birinin öfke, korku, umut veya rahatlama hissedip hissetmediğini ayırt edemezler. Yazarlar, bu daha zengin duygusal paletin afet müdahalesi, terapi desteği ve müşteri hizmetleri gibi uygulamalar için kritik olduğunu savunuyor. Örneğin korku ve aciliyet karışımı bir mesaj derhal müdahale gerektirebilirken, üzüntü ve iyimserlik harmanı farklı türde bir desteği gerektirebilir. Paralel olarak birden fazla duyguyu yakalamak—"çok etiketli" duygu tespiti olarak bilinir—daha hassas, insan odaklı sistemlere doğru atılmış önemli bir adımdır.
Göz ardı edilen dillere ses vermek
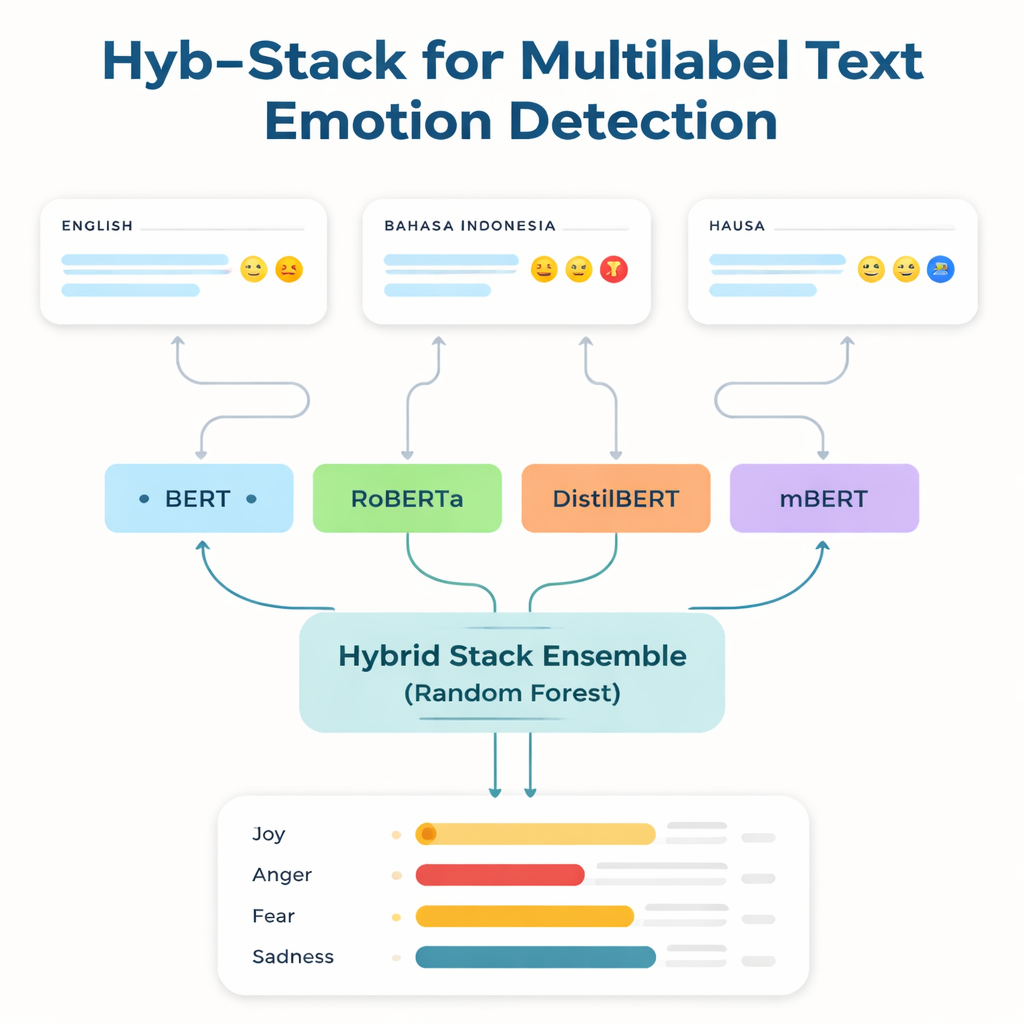
En güçlü dil teknolojilerinin çoğu İngilizce ve birkaç yaygın dil üzerinde eğitilir ve ayarlanır. Etiketlenmiş verisi az ve dijital araçları sınırlı olan az kaynaklı dillerin konuşurları genellikle geride kalır. Bu boşluğu ele almak için araştırmacılar üç veri kümesine odaklanıyor: iyi bilinen bir İngilizce duygu ölçütü; istismar ve nefret diline odaklanan bir Bahasa Indonesia koleksiyonu; ve HaEmoC_V1 adını verdikleri, kendilerinin oluşturduğu yepyeni bir Hausa Twitter derlemesi. Hausa veri seti, öfke, sevinç, güven, kötümserlik ve beklenti gibi on bir duygudan bir veya daha fazlasıyla etiketlenmiş, dikkatle temizlenmiş ve açıklanmış on iki binden fazla tweet içeriyor. Uzman değerlendiriciler etiketleri kontrol etti ve uyuşma skorları açıklamaların hem tutarlı hem de güvenilir olduğunu gösterdi.
Birkaç akıllı okuyucuyu bir araya getirmek
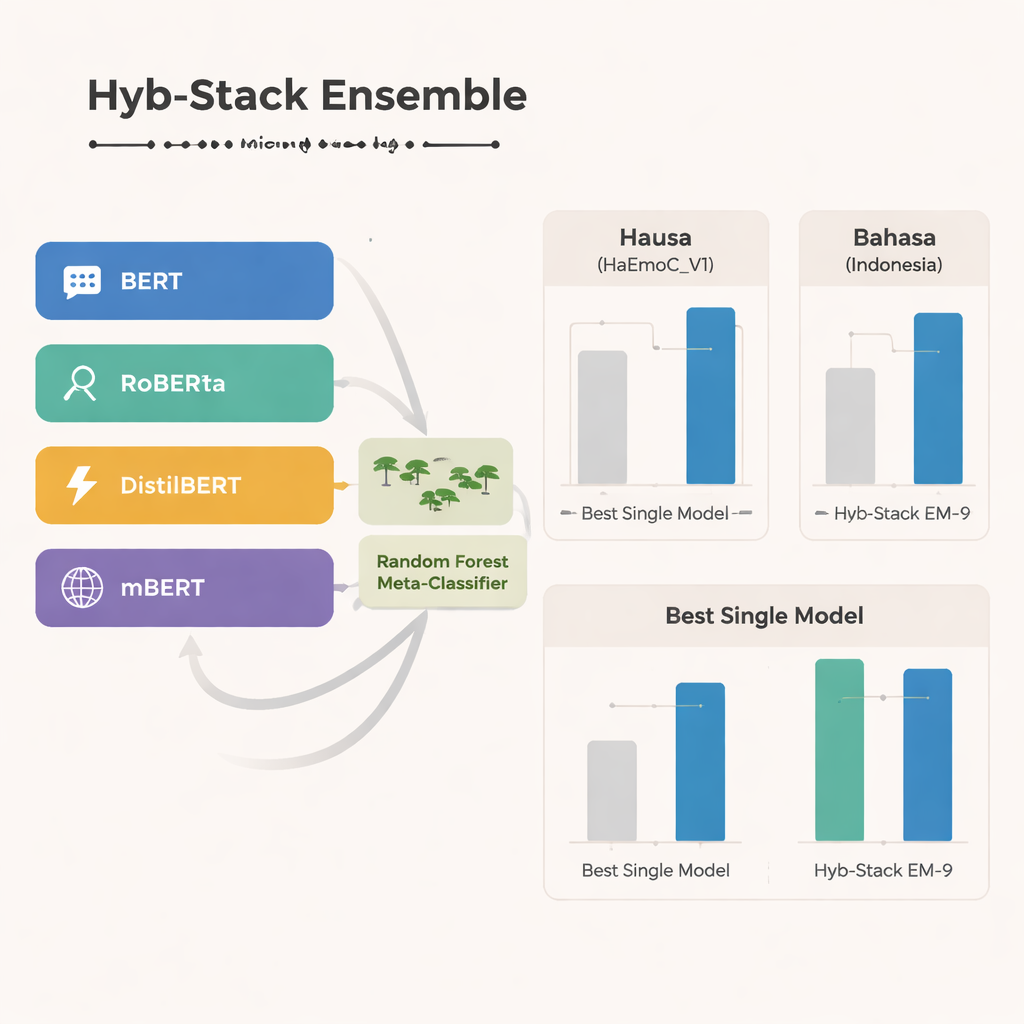
Çalışmanın merkezinde Hyb-Stack adında melez yığılı bir ansambl—dil için bir tür “uzmanlar komitesi”—yer alıyor. Dört gelişmiş dönüştürücü temelli model (BERT, RoBERTa, DistilBERT ve çok dilli mBERT) her biri metindeki duygusal sinyalleri okumak üzere ince ayarlanıyor. Sadece bir modele güvenmek yerine Hyb-Stack hepsinin tahmin yapmasına izin veriyor ve sonra iç puanlarını ikinci seviyede bir karar vericiye, bir Random Forest sınıflandırıcısına besliyor. Bu meta-sınıflandırıcı, her modelin farklı güçlü yönlerini nasıl ağırlıklandıracağını öğrenerek duyguların bir arada nasıl ortaya çıktığına dair karmaşık desenleri yakalıyor. Ekip ayrıca daha basit ansambl yöntemlerini—sadece tahminleri ortalamak, önceki performansa göre ağırlıklandırma ile veya olmadan—test ederek daha karmaşık yığmanın gerçekten avantaj sağlayıp sağlamadığını inceliyor.
Melez yaklaşım ne kadar iyi performans gösteriyor
Üç dilin tümünde, çok dilli mBERT tek başına en güçlü model olarak öne çıkıyor; özellikle yeni oluşturulan Hausa verisi ve Bahasa Indonesia nefret söylemi setinde iyi performans gösteriyor. Yine de melez ansambl daha da ileri gidiyor. Hyb-Stack çerçevesi içinde BERT, DistilBERT ve mBERT’i birleştiren EM-9 adlı belirli bir kombinasyon özellikle tutarlı şekilde en iyi sonuçları veriyor. Bu yöntem, herhangi bir tek modelden veya basit ortalama yaklaşımdan daha yüksek F1 skorları elde ediyor; en büyük kazançlar az kaynaklı Hausa ve Bahasa Indonesia veri kümelerinde görülüyor. Ayrıntılı hata analizleri, kalan hataların genellikle sevinç ile sürpriz ya da üzüntü ile korku gibi yakın ilişkili duygular arasında gerçekleştiğini gösteriyor; bu da sistem hatasından çok insan duygularının doğal belirsizliğini yansıtıyor.
Gerçek dünya sistemleri için bunun anlamı
Genel okuyucu için temel çıkarım, birkaç yapay zekâ modelinin akıllıca bir şekilde birleştirilmesinin metindeki duyguları daha doğru okumaya yardımcı olabileceği; özellikle uzun süredir teknolojide ihmal edilmiş dillerde. Yüksek kaliteli bir Hausa duygu korpusu oluşturarak ve melez ansambların tek modelleri ve basit oy çokluğu şemalarını geride bıraktığını göstererek yazarlar, daha kapsayıcı ve duygusal açıdan daha duyarlı araçlara doğru pratik bir yol sergiliyor. Gelecek çalışmalar, yaklaşıma daha ince duygusal tonları, karışık dil kullanımını, emojileri ve ek olarak temsil edilmeyen dilleri de ekleyerek insanların ne kadar ve neden böyle hissettiklerini—hangi dili konuşurlarsa konuşsunlar—saptayabilen sistemler yaratmayı hedefleyecek.
Atıf: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Anahtar kelimeler: duygu tespiti, çok dilli NLP, ansambl öğrenme, dönüştürücü modeller, az kaynaklı diller