Clear Sky Science · tr
Yüksek hızlı çift hassasiyetli Vedic çarpan mimarisinin verimli hesaplanması ve tasarımı
Daha hızlı sayı işlemenin önemi
Her video akışı yaptığınızda, telefondaki navigasyonu kullandığınızda veya bir yapay zeka sisteminin tıbbi görüntüleri analiz etmesine izin verdiğinizde, özel donanım sessizce saniyede milyarlarca küçük hesaplama gerçekleştirir. Bu işlemlerin büyük bir bölümü, bilgisayarların 3,14159 gibi gerçek değerleri temsil etmek için kullandığı standart biçim olan "kayan nokta" sayıları üzerinde çarpma işlemleridir. Bu makale, bu temel bileşenlerden birini daha akıllıca kurmanın yolunu inceliyor: modern dijital donanımı güçlendirmek için eski Vedic matematiğinden yararlanan, yüksek hızlı ve enerji verimli bir çarpan.
Eski matematik hilelerinden modern çiplere
Kayan nokta aritmetiği, dijital sinyal işleme, görüntü işleme, iletişim ve derin öğrenme hızlandırıcılarının temelini oluşturur. Standart çarpanlar geniş ikili kelimelerle—çift hassasiyet için 64 bit—başa çıkmak zorundadır ve bunu hızlı, çip alanı veya güç israf etmeden yapmalıdır. Booth, Karatsuba ve dizi çarpanları gibi geleneksel yaklaşımlar hız, donanım boyutu ve tasarım karmaşıklığı arasında uzlaşmalar yapmak zorundadır. Hindistan’da geliştirilen 16 klasik aritmetik kuraldan oluşan Vedic matematiği, "dikey ve çapraz" anlamına gelen Urdhva Tiryakbhyam adlı bir çarpma yöntemi içerir. Bu yöntem kısmi ürünleri son derece paralel bir şekilde oluşturur; bu da ara adımların ve gereken donanımın sayısını azaltabilir. Araştırmacılar son zamanlarda bu fikirleri dijital devrelere uyarladı, ancak mevcut tasarımlar çift hassasiyetli kayan nokta işlemleri için kullanıldığında hâlâ ek yükler taşıyor.
Bu yeni çarpanı özel kılan nedir
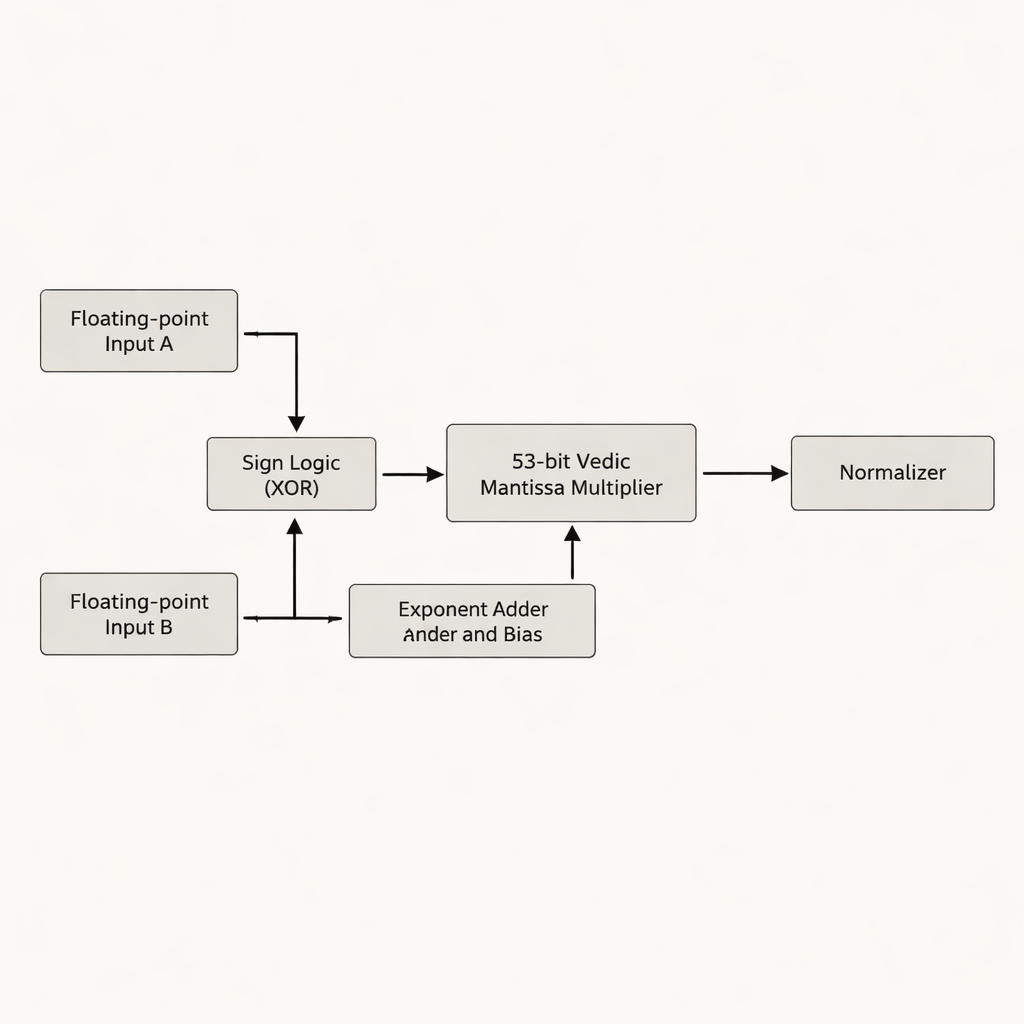
Yazarlar, kayan nokta sayısının en önemli kısmını tutan mantissa (kesir kısmı) üzerine odaklanan bir çift hassasiyetli kayan nokta çarpanı öneriyor. Birçok önceki tasarımın yaptığı gibi 52 bitlik mantissayı 54 bite doldurmak yerine, gerçek 53 bitlik etkili mantissa ile çalışıyorlar; böylece çipte ekstra depolama ve kablolama tüketen gereksiz "boş" bitlerden kaçınılıyor. Tasarımın kalbi, Urdhva Tiryakbhyam tabanlı 53 bitlik bir Vedic çarpandır ve daha küçük yapı taşlarının hiyerarşisinde düzenlenmiştir: 3 bitlik birimler 6 bitlikleri, bunlar 12 bitlik, 13 bitlik, 26 bitlik ve 52 bitlik birimleri oluşturur ve hepsi nihai 53 bitlik aşamaya birleştirilir. Mimari işi üç ana aşamaya ayırır—işaret hesaplama, üs toplama ve önyarglama, ve normalizasyonu takip eden mantissa çarpımı—IEEE-754 kayan nokta standardına uyarak gereksiz devreleri kırpar.
Daha temiz donanım için asal boyutlu yapı taşları
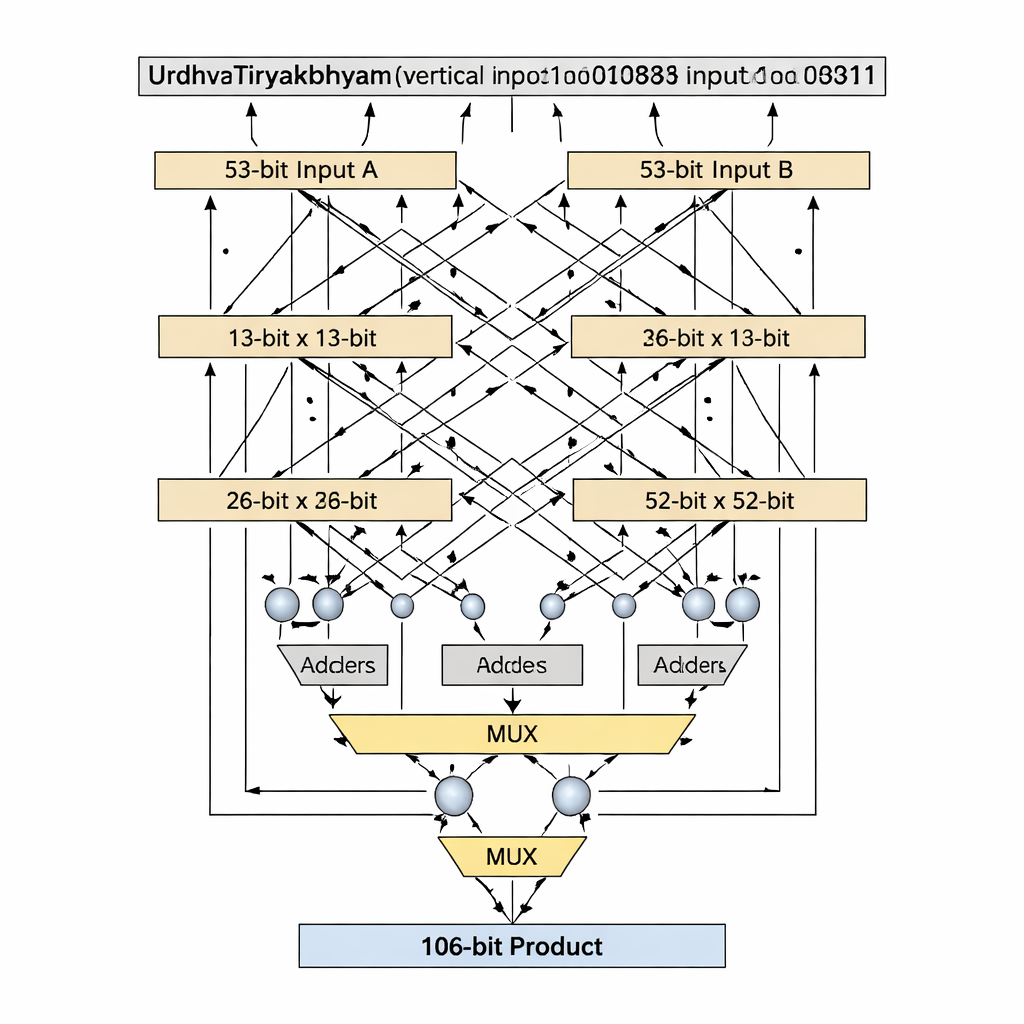
Ana yenilik, 13 ve 53 gibi asal sayı olan bit genişliklerinin nasıl ele alındığıdır; bu boyutlar eşit parçalara rahatça bölünmez. Standart Vedic ayrıştırmaları girdilerin eşit olarak bölünmesini varsayar, ancak bu asal uzunluklar için uygunsuz veya israflı olur. Yazarlar, (n−1) bitlik daha küçük bir Vedic çarpanı, toplayıcılar, çoklayıcılar ve tek bir ekstra mantık kapısı kullanarak n bitlik bir çarpanı dolgu yapmadan taklit eden "asal-bit" algoritmasını tanıtır. 13 bitlik aşama için girdiler 1 bitlik ve 12 bitlik bölümlere ayrılır; kısmi ürünler 12 bitlik bir Vedic çarpan kullanılarak, en anlamlı bitlere göre koşullu seçim (multiplexer’lar aracılığıyla) ve az sayıda toplayıcı ile oluşturulur. Aynı desen 52 bitlik bir çekirdekle 53 bite ölçeklenir. Bu amaçlı ayrıştırma kritik yolu—bir sinyalin kat etmesi gereken en uzun mantık zinciri—kısaltırken mantık elemanı sayısını düşük tutar.
Hız, boyut ve güçte ölçülen kazançlar
Tasarım Verilog donanım tanımlama dilinde tanımlandı ve Vivado araçları kullanılarak bir Xilinx Zynq alan programlanabilir kapı dizisi (FPGA) üzerinde uygulandı. 13-, 26-, 52-, 53- ve 64-bit Vedic çarpanlar genelinde, önerilen 53 bitlik birim gecikme, mantık kullanımı (lookup tabloları ve G/Ç pinleri) ve tahmini güç açısından elverişli bir denge gösteriyor. Booth, Karatsuba ve diğer Vedic düzenlemelerine dayanan önceki çift hassasiyetli çarpanlarla karşılaştırıldığında, yeni mimari en kötü durum gecikmesini ve gereken FPGA kaynak miktarını önemli ölçüde azaltırken çevresindeki kayan nokta devrelerine ek karmaşıklık getirmiyor. Çünkü mantissa çarpımı daha hızlı ve mantık derinliği daha sığ, anahtarlama aktivitesi azalıyor; bu da doğrudan teknoloji karşılaştırmaları yapmak zor olsa da daha iyi bir güç–gecikme ürünü işaret ediyor.
Yapay zeka ve sinyal işleme üzerindeki etkileri
Tasarımları gerçek bir iş yükünde test etmek için yazarlar Vedic çift hassasiyetli çarpanlarını Evrişimsel Sinir Ağı’nın evrişim motoruna entegre ettiler; burada çarp ve topla (multiply-and-accumulate) işlemleri çalışma süresinin çoğunluğunu oluşturur. Geleneksel IEEE-754 ve önceki Vedic çarpanların yerine yeni tasarımın kullanılması, evrişim gecikmesini kısalttı, güç tüketimini azalttı ve çıkarım süresini düşürdü; tüm bunlar sınıflandırma doğruluğu korunurken gerçekleşti. Dijital filtreleme, kenar tespiti ve tıbbi görüntüleme boru hatları gibi hesaplama ağırlıklı diğer görevlerde de benzer avantajlar beklenir; daha hızlı çarpanlar doğrudan verimi artırır ve cihazların daha serin çalışmasına veya daha küçük pillerle çalışmasına izin verebilir.
Günlük teknoloji için anlamı
Basitçe söylemek gerekirse, makale Vedic matematiğinden alınmış zekice bir çarpma fikrini modern ikili formatlarla dikkatlice eşleştirmenin, standart tasarımlardan daha küçük, daha hızlı ve daha enerji verimli bir çarpan ortaya çıkarabileceğini gösteriyor. Bu geliştirilmiş yapı taşı işlemcilere, sinyal işleme çiplerine ve yapay zeka hızlandırıcılarına yerleştirilebilir; bunun sonucunda daha hızlı veri analizi, daha duyarlı cihazlar ve akıllı telefonlardan tıbbi tarayıcılara kadar sistemlerde potansiyel olarak daha düşük güç kullanımı sağlanabilir. Yazarlar ayrıca daha da düşük enerji kullanımı için tersinir mantık ve daha büyük işlem birimlerine entegrasyon gibi gelecekteki yönlerden bahsediyor; bu da eski aritmetik ile modern donanım evliliğinin daha yeni başladığını öne sürüyor.
Atıf: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Anahtar kelimeler: Vedic çarpanı, kayan nokta aritmetiği, FPGA tasarımı, dijital sinyal işleme, evrişimsel sinir ağları