Clear Sky Science · tr
Sürü tabanlı derin sinir ağları ve topluluk modellerinin özgül iletkenlik verilerinin yeniden oluşturulmasına uygulanması
Veri boşluklarını doldurmanın önemi
Kıyı suları, insan faaliyetinin okyanusla buluştuğu ön saftır. Bilim insanları bu suların tuzluluğunu özgül iletkenlik adı verilen bir ölçüyle takip eder; bu ölçü kirlilik sızıntılarını, tatlı su akışlarındaki değişimleri ve uzun vadeli çevresel eğilimleri açığa çıkarır. Ancak sensörler arızalanır, fırtınalar elektriği keser ve cihazların sınırlamaları vardır. Sonuç, tam da yöneticiler ve araştırmacıların sürekli veriye en çok ihtiyaç duyduğu anda ortaya çıkan can sıkıcı boşluklar halindeki önemli kayıtlar olur. Bu çalışma pratik bir soruyu gündeme getiriyor: modern yapay zeka bu kırık kayıtları güvenilir şekilde “onarabilir” ve böylece kıyı yönetimi eksiksiz, güvenilir bilgilere dayanabilir mi?
Gulf’un nefesini izlemek
Araştırmacılar, dünyanın en büyük deniz ekosistemlerinden biri olan ve yoğun sanayi ile tarım baskısı altında bulunan Meksika Körfezi’ne odaklandı. Pascagoula Nehri ve Mullet Gölü yakınlarındaki beş ABD Jeolojik Araştırma İstasyonu’ndan alınan verileri kullandılar; her istasyon özgül iletkenlik (su tuzluluğu), sıcaklık ve su seviyesini her 15 dakikada bir kaydediyordu. E adlı bir istasyonun özgül iletkenlik verilerinin yaklaşık %5’i eksikti—gerçek dünyadaki izleme ağlarının sıklıkla karşılaştığı tam da bu tür bir sorun. Dört komşu istasyondan gelen veriler çevresel bir emniyet ağı gibi davrandı: E istasyonu görünmez olduğunda bile diğerleri izlemeye devam etti. Temel fikir, bilgisayar modellerine beş istasyonun birlikte nasıl “nefes aldığını” öğretmek ve böylece bir sitedeki boşlukların diğerlerinin eksiksiz kayıtlarından türetilebilmesiydi.
Akıllı algoritmaları teste sokmak
Bunu ele almak için ekip on farklı modelleme yaklaşımından oluşan bir kadro kurdu. Bir uçta, girişler ile çıktılar arasında doğrusal ilişkiler kurmaya çalışan çoklu doğrusal regresyon gibi tanıdık araçlar vardı. Ortada, klasik sinir ağları, bulanık mantık sistemleri ve zaman serileri verileri için sıklıkla kullanılan özel bir uzun-kısa vadeli bellek (LSTM) ağı gibi daha esnek modeller yer aldı. Ayrıca kendi kendini örgütleyen bir yöntem olan veri işleme grup yöntemi (GMDH) ve çok katmanlı formüller oluşturabilen doğrusal olmayan bir varyantı (NGMDH) kullanıldı. Son olarak, tek bir karar ağacı modeli (CART) ve birçok ağacı birleştirerek nihai kararı oluşturan iki “topluluk” yaklaşımı—Random Forest ve XGBoost—getirildi; bunlar, soruya oy veren bir uzman paneli gibi çalışır.
Sürü destekli derin öğrenme
Derin sinir ağlarını eğitmek ünlü şekilde zordur: çok sayıda ayarları ve parametreleri kolayca kötü konfigürasyonlarda takılabilir. Bunları iyileştirmek için yazarlar LSTM ve NGMDH’yi, çalkalanan su hareketlerinden ilham alan ve türbülanslı su tabanlı optimizasyon (TFWO) adı verilen yeni bir optimizasyon yöntemiyle eşleştirdiler. Bu düzenekte, model parametrelerinin her olası kümesi çözüm uzayında girdap benzeri bir şekilde hareket eden bir “parçacık” olarak hayal edilir. Birçok döngü boyunca parçacıklar, daha küçük tahmin hataları veren bölgelere doğru yönlendirilir. Bu sürü tarzı arama, her iki sinir ağı türünü de standart sürümlerinden belirgin şekilde daha doğru hale getirerek ortalama hatalarını yaklaşık %6–11 oranında düşürdü. Yine de, bu geliştirilmiş derin modeller nihai olarak ağaç tabanlı yaklaşımlar tarafından geride bırakıldı.
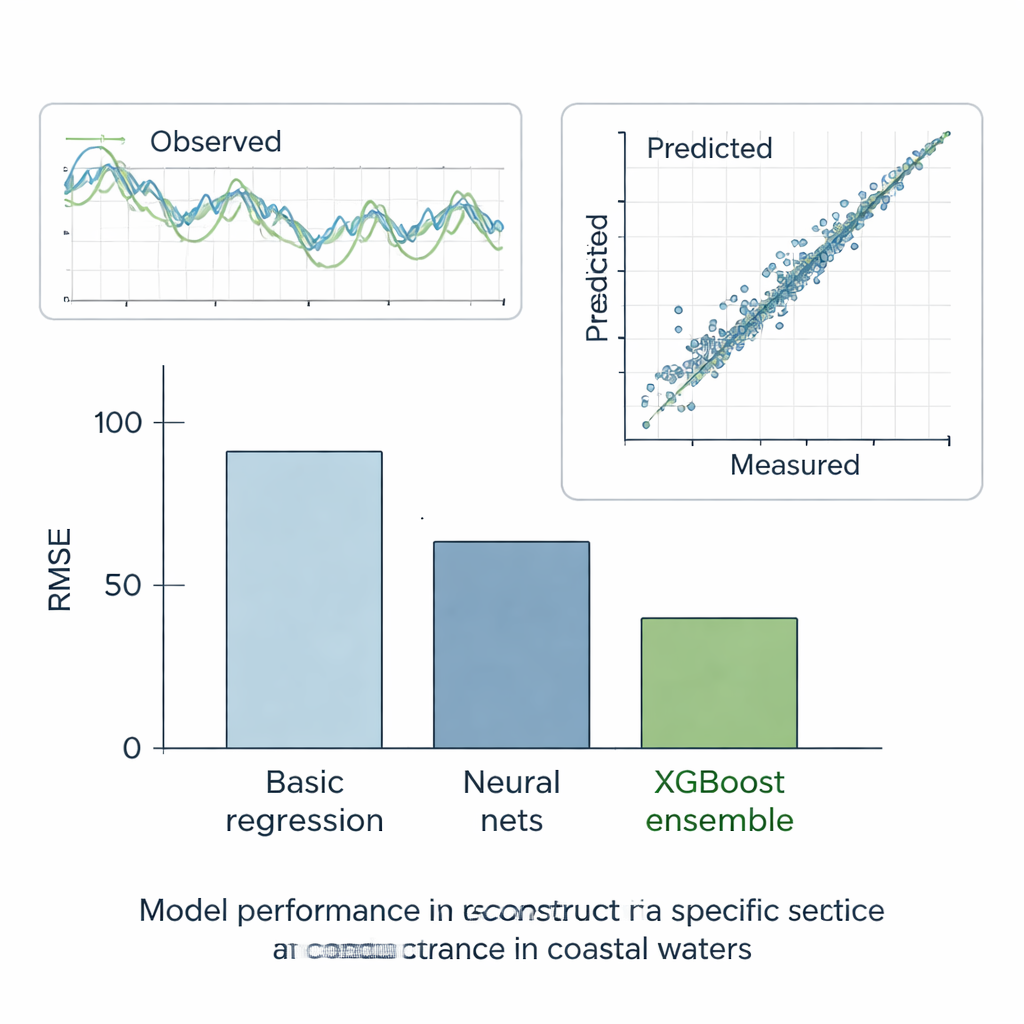
Topluluklar öne çıkıyor
Yazarlar tüm yöntemleri altı senaryoda titizlikle test ettiler. Beş “ya-ne-olursa” vakasında, aksi takdirde eksiksiz kayıtların parçalarını gizleyip her bir modelin eksik değerleri ne kadar iyi yeniden oluşturabildiğini kontrol ettiler. Son, gerçek dünya vakasında ise modellerden, komşu istasyonların verilerini kullanarak E istasyonundaki gerçek boşlukları doldurmalarını istediler. Bu testlerde en basit doğrusal yöntem en kötü performansı gösterirken, standart makine öğrenimi modelleri çok daha iyi oldu ve hatayı kabaca yarıya indirdi. Veriyi daha homojen gruplara otomatik olarak bölen karar ağaçları daha da iyileşti. Ancak açık kazanan XGBoost topluluğuydu: önceki ağaçların hatalarını düzelten yüzlerce ağaç kurarak son derece düşük hata elde etti ve tahmin edilen ile ölçülen özgül iletkenlik arasında neredeyse mükemmel bir uyum sağladı. Yeniden oluşturdukları veriler gözlemlenen zaman serilerini yakından izledi ve su kalitesi kayıtlarının genel istatistiksel davranışını yeniden üretti.
Kıyılar ve ötesi için bunun anlamı
Uzman olmayanlar için çıkarılacak basit mesaj şudur: dikkatle tasarlanmış yapay zeka, özellikle çevreleyen istasyonlar bağlam sağladığında, kıyı suyu kalitesi kayıtlarındaki eksik parçaları güvenilir şekilde doldurabilir. Gelişmiş sinir ağları güçlü olmakla birlikte bu çalışma ağaç tabanlı topluluk yöntemleri—özellikle XGBoost’un—daha da doğru olduğunu ve pratikte çevresel veri setlerini onarmada en iyi seçenek olabileceğini gösteriyor. Dayanıklı boşluk doldurma araçlarıyla, bilim insanları kıyı tuzluluğundaki hassas değişimleri daha iyi izleyebilir, kirlilik olaylarını tespit edebilir ve kaçınılmaz sensör arızalarından etkilenmeden yönetim kararlarını destekleyebilir. Aynı stratejiler, veri akışlarının zengin, gürültülü ve zaman zaman eksik olduğu birçok başka mühendislik ve çevre problemine de uyarlanabilir.
Atıf: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Anahtar kelimeler: kıyı suyu kalitesi, özgül iletkenlik, makine öğrenimi, eksik veri yeniden oluşturma, XGBoost