Clear Sky Science · tr
Akıllı optimizasyon ve evrimsel algoritmalarla rastgelelik test cihazları için sınırda kalan test örnekleri üretme
Neredeyse rastgele olmanın günlük güvenlik için önemi
Her çevrimiçi alışveriş yaptığınızda, telefonun kilidini açtığınızda veya özel bir mesaj gönderdiğinizde, verilerinizi güvende tutmak için görünmeyen matematiksel zarlar atılıyor. Bu zarlar, kriptografik anahtarlar olarak kullanılan uzun, sözde rastgele bit dizileri biçimini alır. Eğer bu bitler gerektiği kadar rastgele değilse, kararlı saldırganlar zaman zaman istismar edilebilecek örüntüler bulabilir. Bu makale, mühendislerin dijital yaşamımızı koruyan aygıtları ciddi şekilde stres test edebilmesi için son derece rastgele görünen ama içinde küçük kusurlar saklayan “neredeyse rastgele” test dizileri üretmenin yeni bir yolunu araştırıyor.
Rastgele sayılar yeterince rastgele olmadığında
Modern güvenlik sistemleri iki tür rastgele sayı üretecine dayanır. Gerçek rastgele sayı üreteçleri elektronik gürültü veya kuantum dalgalanmaları gibi tahmin edilemez fiziksel etkilere dayanırken, sözde rastgele üreteçler kısa, rastgele tohumları uzun dizilere dönüştüren algoritmalar kullanır. Pratikte her iki türün kalitesi nihayetinde entropi kaynağı olarak adlandırılan fiziksel belirsizlik kaynağına bağlıdır. Ne yazık ki, gerçek dünya entropi kaynakları kırılgandır: sıcaklık değişiklikleri, donanımın yaşlanması veya tasarım hataları rastgeleliklerini sessizce azaltabilir. Bu tür sorunları yakalamak için NIST gibi standart kuruluşlar çıktı bitlerinin yeterince rastgele görünüp görünmediğini kontrol eden bir dizi istatistiksel test tanımlar. Aygıtlar giderek kendi çıktılarını çalışırken izleyen “gerçek zamanlı rastgelelik test cihazları” barındırıyor. Yine de, bu gömülü denetleyicilerin gerçekten çalışıp çalışmadığını test etmek için gerçekçi ve tespit edilmesi zor hata durumları üretmenin iyi bir yolu yoktu.
Rastgelelik testlerini zar zor geçemeyen diziler tasarlamak
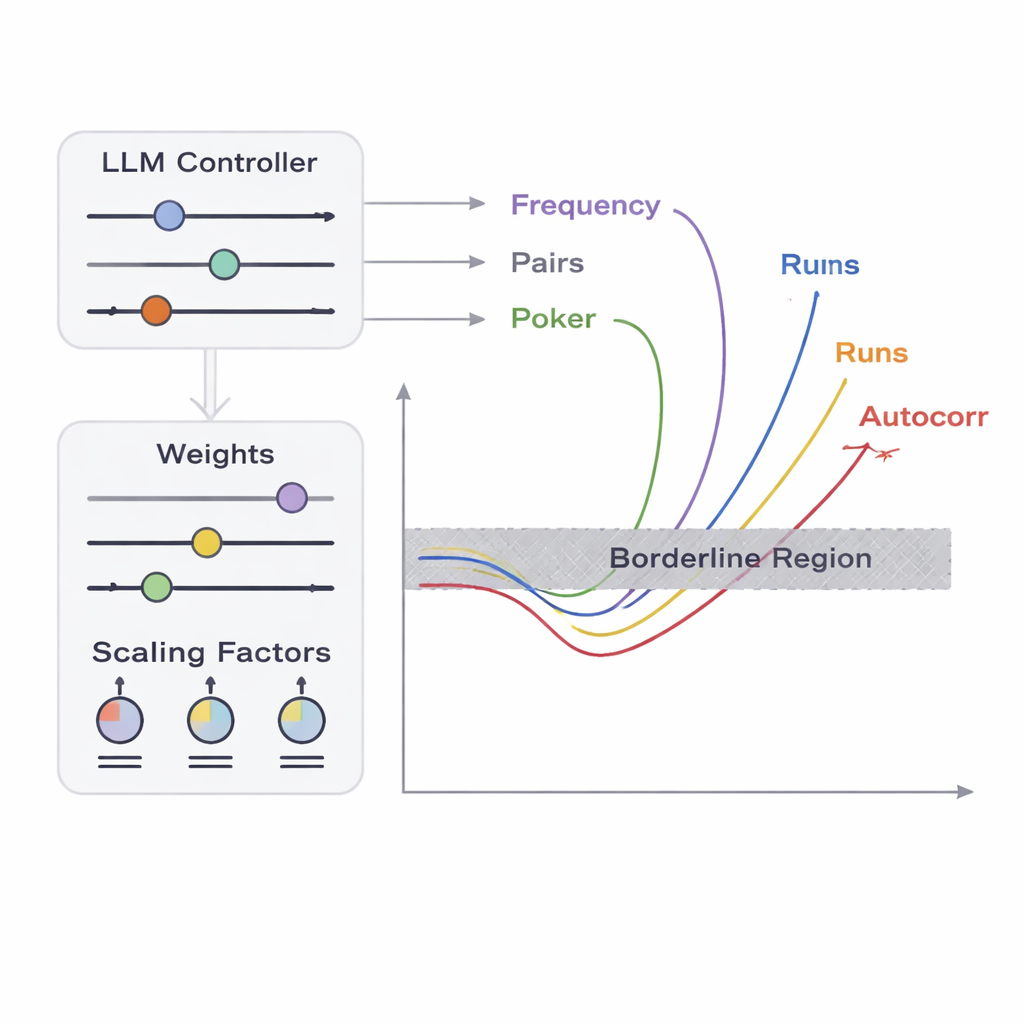
Bir test cihazı açısından basit hatalar—örneğin tüm çıktının sıfırlardan oluşması—kolayca fark edilir. Gerçek zorluk sınırdaki durumları tespit etmektir: ideal rastgelelikle neredeyse ayırt edilemez ancak bir veya daha fazla istatistiksel testi zar zor geçemeyen diziler. Yazarlar, sıfırların ve birlerin ne sıklıkta göründüğünü, bit çiftlerinin davranışını, belirli kısa örüntülerin dağılımını, bitlerin kaydırılmış kopyalarıyla korelâsyonunu ve aynı bitlerin ardışık tekrar uzunluklarının düzenini içeren farklı bit örüntüsü yönlerini inceleyen beş klasik teste odaklanıyor. Her test için verinin olağan kabul eşiğini hafifçe ihlal ettiği dar bir “sınır bölgesi” tanımlıyorlar. Uzun bir dizinin aynı anda bu dar bantların tümünün içine düşmesi tesadüfen son derece düşük bir olasılıktır; çünkü testler karmaşık, doğrusal olmayan şekillerde etkileşir. İşte burada optimizasyon ve yapay zekâ devreye giriyor.
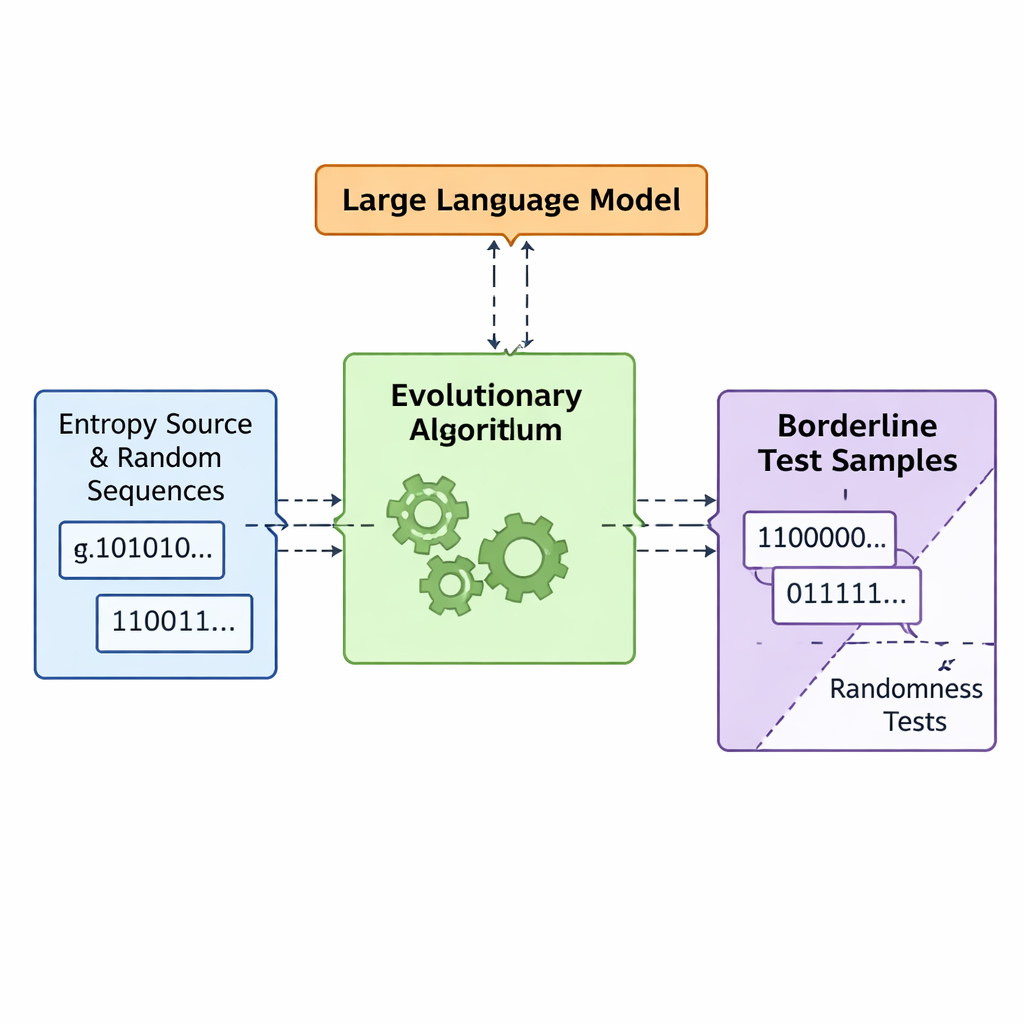
Evrim ve dil modellerine kötü rastgeleliği birlikte tasarlatmak
Araştırma ekibi, dizgi üretimini yüksek boyutlu bir optimizasyon problemi olarak ele alan APAM‑IGLLM adlı bir çerçeve tanıtıyor. Her aday dizi bir bit dizisi ve “uygunluğu” beş testin sınır bölgelerine ne kadar yakın olduğunun bir ölçüsü. Bir genetik algoritma bu dizileri tekrarlı olarak mutasyona uğratıp yeniden kombinleyerek, hedef bölgeye doğru ilerleyenleri koruyor. Bunun üzerine bir büyük dil modeli (LLM) bir tür strateji koçu rolü oynuyor. Her nesilde popülasyonun özet istatistiklerini ve kısa dönem geçmişini inceleyip hangi iç ayarların—her testin uygunluk üzerindeki etkisini belirleyen ağırlıklar ve ölçekleme faktörleri—nasıl ayarlanması gerektiğini öneriyor. Bu, bir geri bildirim döngüsü yaratıyor: genetik algoritma olası diziler uzayını keşfederken, LLM aramayı beş test skorunun tümünün dizilerin zar zor rastgele olmayan küçük kesişim bölgesine doğru yakınsaması için yönlendiriyor.
Hatalı veriler mükemmel rastgeleliğe ne kadar yakın görünebilir?
Yapay kusurlarının gerçekçi görünüp görünmediğini görmek için yazarlar ürettikleri dizileri yaygın olarak kullanılan karşılaştırma ölçütleriyle karşılaştırıyor. Her baytın ne kadar öngörülemez göründüğünü ölçen Shannon entropisi ve min‑entropiyi hesaplıyorlar ve bayt başına yaklaşık 7.6–8 bit aralığı buluyorlar—teorik maksimum olan 8’e çok yakın ve ticari donanım rastgelelik kaynakları ile NIST’in halka açık rastgelelik beacon’una benzer. Ayrıca tam NIST SP 800‑22 istatistiksel test paketini çalıştırıyor ve sınırdaki dizilerinin, gerçek yüksek kalitedeki rastgele verilerle neredeyse aynı kalıp içinde geçip geçtiğini gözlemliyorlar. Başka bir deyişle, standart araçlara göre bu örnekler esasen normal görünüyor, oysa kasıtlı olarak birden fazla başarısızlık eşiğinin yakınında olacak şekilde tasarlanmışlar. Bu da onları gömülü rastgelelik test cihazlarının ne kadar sağlam olduğunu kontrol etmek için ideal “adversaryel” girişler yapıyor.
Gerçek dünya güvenliği için anlamı
Bir laikin bakış açısından, bu çalışma şifrelemenin temelini oluşturan rastgele sayı mekanizmalarını güvenlik açısından kontrol etmenin yeni bir yolunu sunuyor. Aygıtları yalnızca açıkça bozuk veya açıkça sağlıklı rastgelelikle test etmek yerine, mühendisler artık ince donanım hatalarını veya çevresel sapmayı taklit eden dikkatle hazırlanmış, neredeyse iyi dizilerle onları bombardımana tutabilir. Bir gerçek zamanlı rastgelelik test cihazı bu sınırdaki durumları kaçırıyorsa, bu dağıtım öncesi düzeltilmesi gereken potansiyel bir kör nokta olduğunu gösterir—bankacılık, güvenli iletişim veya blok zinciri sistemlerinde kullanılmadan önce. Bir dil modeli tarafından yönlendirilen evrimsel arama kullanarak yazarlar, bu tür zorlu test verilerini üretmek için pratik bir araç sağlıyor ve dijital güvenliğin görünmeyen temellerini daha yüksek güvenilirlik seviyelerine taşımaya yardımcı oluyor.
Atıf: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Anahtar kelimeler: rastgele sayı üreteçleri, entropi kaynakları, evrimsel algoritmalar, büyük dil modelleri, kriptografik testler