Clear Sky Science · tr
Karşılaştırmalı distilasyon ile gürültülü etiketleri düzeltme: bir alan uyarlama yaklaşımı
Dağınık verinin neden büyüyen bir sorun olduğu
Modern yapay zeka veriye dayanır, ancak bu veriler sıklıkla hatalı, eksik veya tutarsız biçimde etiketlenmiştir. Etiketler gürültülü olduğunda—örneğin bir kedi fotoğrafının köpek olarak işaretlenmesi—öğrenme sistemleri yanıltılabilir ve doğrulukları ile güvenilirlikleri azalır. Bu makale, gerçek dünya sorunu olan şunu ele alıyor: eğitim etiketleri hatalı ve görüntüler farklı ortamlardan (örneğin çevrimiçi mağazalar versus gerçek dünya fotoğrafları) geldiğinde bile görüntü tanıma sistemlerini nasıl iyi çalışır halde eğitebiliriz?
Farklı dünyalar arasında öğrenme
Uygulamada, yapay zeka modelleri genellikle etiketlerin dikkatle kontrol edildiği bir “kaynak” dünyadan öğrenir, daha sonra etiketlerin kıt ve hataya açık olduğu bir “hedef” dünyada performans göstermelidir. Örneğin, stüdyoda fotoğraflanmış ofis nesneleri düzenli ve doğru etiketlenirken, aynı nesnelerin webcam veya günlük yaşam fotoğrafları dağınık ve tutarsız etiketlenmiş olabilir. Geleneksel alan uyarlama yöntemleri bu uçurumu iki dünyanın genel istatistiklerini hizalayarak kapatmaya çalışır. Ancak bunlar genellikle hedef etiketlerinin mevcut olduğunda doğru olduğu varsayımını yapar—bu, kitle kaynaklı etiketler, düşük kaliteli sensörler veya otomatik anotasyon araçlarının bulunduğu gerçek uygulamalarda tehlikeli bir varsayımdır.
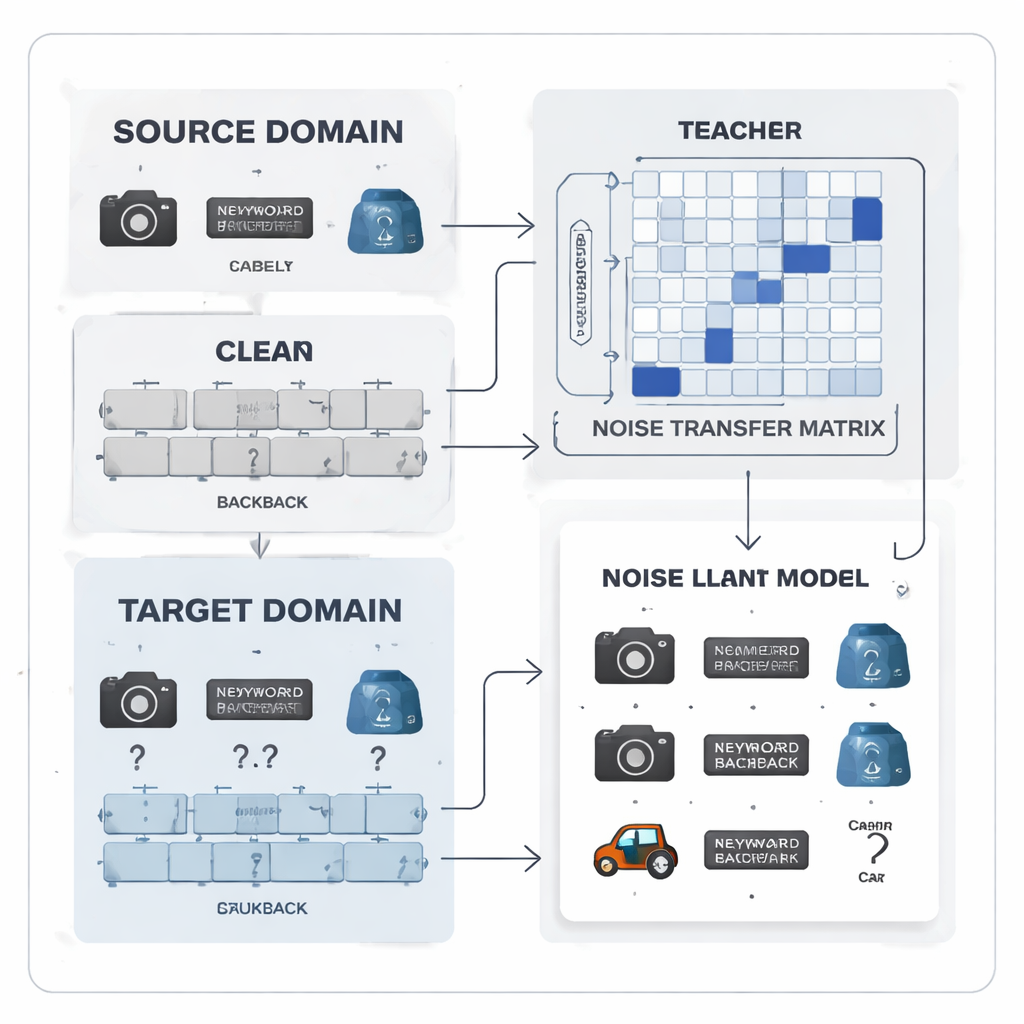
Etiket hatalarını öğrenilebilir bir örüntüye dönüştürmek
Yazarlar etiket gürültüsünü rastgele kaos olarak değil, öğrenilebilir bir örüntü olarak ele almayı öneriyor. Her gerçek sınıfın başka bir sınıf olarak yanlış etiketlenme olasılığını yakalayan bir “gürültü aktarım matrisi” tanıtıyorlar. Bu tabloyu birkaç kusursuz “çapa” örneğinden tahmin etmek yerine—ki etiketlerin gürültülü ve sınıfların dengesiz olduğu durumda gerçekçi değildir—matris doğrudan eğitim sırasında öğreniliyor. Öğrenmeyi başlatmak için yöntem, güçlü bir önceden eğitilmiş model tarafından çıkarılan her sınıf için ortalama özellik parmak izleri olan kategori “prototipleri” oluşturuyor. Bu prototipler arasındaki benzerlik matrisin başlangıçlandırılmasında kullanılıyor; böylece benzer ofis araçları gibi karıştırılabilir kategoriler baştan daha güçlü bağlarla ilişkilendirilerek sistemin etiketleri düzeltme konusunda erken bir yetenek kazanması sağlanıyor.
Daha temiz sinyaller için öğretmen–öğrenci ekip çalışması
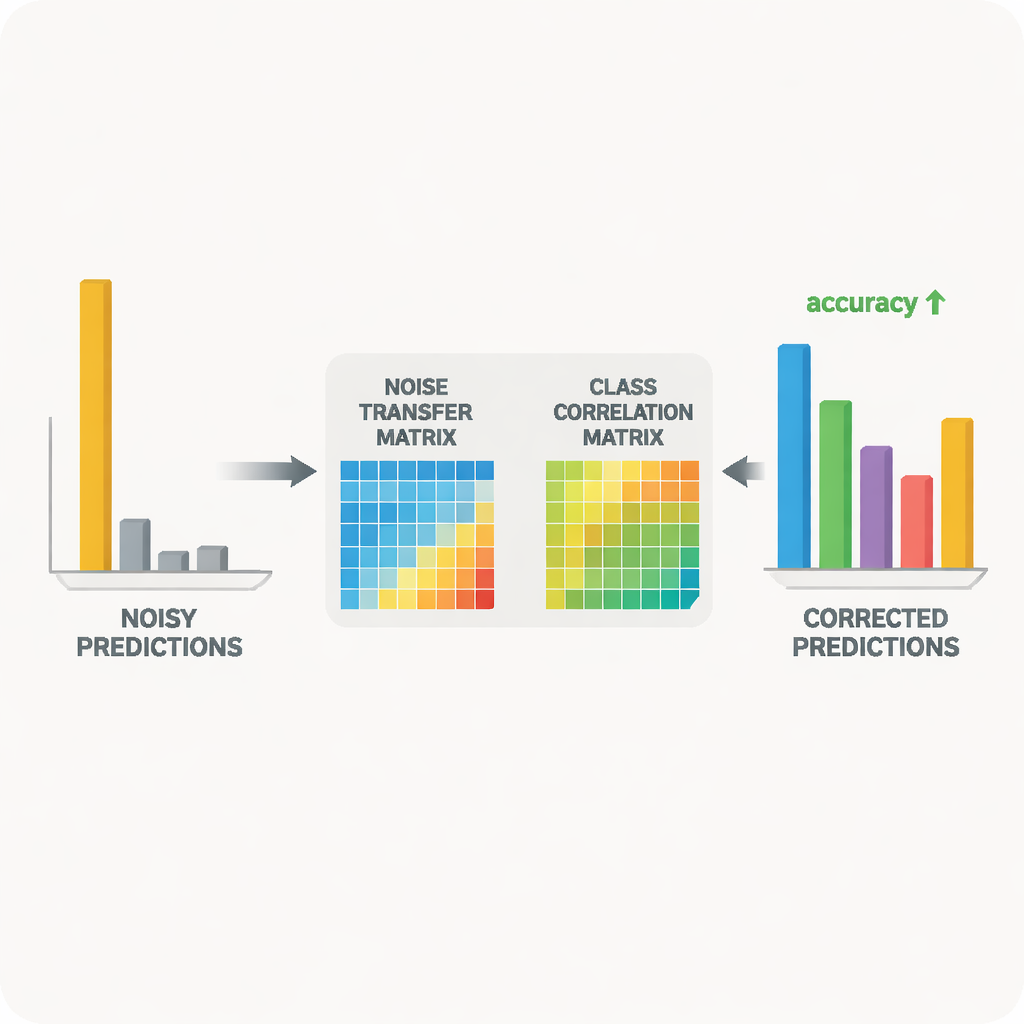
Sistemin merkezinde öğretmen–öğrenci çiftinden oluşan sinir ağları bulunuyor. Öğretmen, büyük bir kendi kendine denetimli görsel modele dayanıyor; bu model etiketlenmemiş büyük veri kümesinden zengin görsel özellikler öğrenmiş durumda. Öğrenci ise gürültülü hedef veride iyi performans göstermesi gereken daha hafif bir ağ. Öğretmen, farklı sınıfların nasıl ilişkili olduğunu gösteren yumuşak tahmin skorları üretiyor; bu skorlar kullanılarak hangi etiketlerin birlikte görülme eğiliminde olduğunu özetleyen bir sınıf korelasyon matrisi oluşturuluyor. Bu matris bir rehber görevi görerek gürültü aktarım matrisini daha gerçekçi düzeltmelere doğru yönlendiriyor. Aynı zamanda öğrenci, distilasyon olarak bilinen bir süreçle öğretmenin davranışını taklit edecek şekilde eğitilirken, kontrastif öğrenme her iki ağı da aynı görüntünün farklı artırılmış görünümlerine benzer iç temsiller ve farklı nesnelere ayrı temsiller vermeye teşvik ediyor.
Düzeltmeleri kararlı tutmak ve aşırı özgüveni önlemek
Gürültü aktarım matrisinin serbestçe değişmesine izin verilmesi onu kararsız veya aykırı değerlere aşırı duyarlı hale getirebilir. Bunu önlemek için yazarlar, matrisi temel germe yönlerine ayıran tekil değer ayrıştırımına dayalı matematiksel bir hile kullanıyor. Bu yönlerin ima ettiği toplam “hacmi” cezalandırarak yöntem aşırı bozulmaları ve gürültüyü büyütecek uç davranışları caydırıyor. Başka bir sorun da modelin kendinden çok emin hale gelmesi; neredeyse tüm olasılığı tek bir sınıfa atamak, yanlış etiketleri düzeltmeyi zorlaştırıyor. Bunu ele almak için yöntem, tahmin olasılıklarını daha pürüzsüz tutan Tsallis entropisine dayalı bir çeşit entropi düzenlemesi ekliyor. Bu, gürültü aktarım matrisinin yanlış bir sınıftan olasılık kütlesini daha makul alternatiflere kısmen yeniden atamasını kolaylaştırıyor.
Gerçek görüntü koleksiyonlarında fikri kanıtlamak
Araştırmacılar yaklaşımını çapraz alan nesne tanıma için yaygın kullanılan iki kıyas setinde test ettiler: Office‑31 ve Office‑Home; bunlar ürün fotoğrafları, çizgi film (clip art) ve gerçek dünya anlık görüntüleri gibi birden çok stilde günlük ofis öğelerinin görüntülerini içeriyor. Bir stilde eğitip başka bir stilde test etme görevleri arasında yöntemleri çeşitli durumlarda eşleşti veya öne çıkan algoritmaları aştı; özellikle alanlar arasındaki kaymanın en büyük olduğu en zor vakalarda üstün performans gösterdi. Ayrıntılı incelemeler, gürültü matrisine yönelik hacim kontrolünün, sınıf korelasyon rehberliğinin ve entropi düzlemesinin her birinin ölçülebilir kazanımlar sağladığını gösterdi. Öğrenilen matrisin ve özellik uzayının görselleştirmeleri, eğitim boyunca yanlış etiketlenmiş örneklerin kademeli olarak doğru kategorilerine çekildiğini ve kaynak ile hedef görüntü dağılımlarının daha iyi hizalandığını doğruladı.
Günlük AI sistemleri için bunun anlamı
Uzman olmayan biri için çıkarılacak ana sonuç, bu çalışmanın AI modellerini insan ve makine kaynaklı etiketleme hatalarına karşı daha hoşgörülü hale getirdiğidir; özellikle modeller temiz laboratuvar koşullarından daha dağınık gerçek dünya ortamlara taşınmak zorunda kaldığında. Etiketlerin nasıl yanlış gittiğini açıkça öğrenerek ve düzeltmeleri yönlendirmek için güçlü bir öğretmen modelinden yararlanarak, yöntem gürültülü eğitim sinyallerini temizleyebilir ve daha doğru, daha sağlam sınıflandırıcılar elde edebilir. Yaklaşım ek hesaplama gerektirse de, “doğada” toplanan büyük, kusurlu veri kümelerinin daha güvenli ve etkili biçimde kullanılabileceği, emek yoğun manuel anotasyona bağımlılığımızı azaltan bir geleceğe işaret ediyor.
Atıf: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Anahtar kelimeler: gürültülü etiketler, alan uyarlama, bilgi distilasyonu, görüntü sınıflandırma, yarı denetimli öğrenme