Clear Sky Science · tr
Sürekli kontrol pekiştirmeli öğrenmede lambda alt güven sınırı ile risk duyarlı ikiz dağılımsal eleştirmenler
Robotlara Tedbirli Olmayı Öğretmek
Günümüzün en etkileyici robotları ve oyun oynayan programlarının çoğu, yazılım ajanlarının ödüller toplayarak deneme-yanılma yoluyla öğrendiği pekiştirmeli öğrenmeye dayanıyor. Ancak bu ajanlar genellikle kararlarının ne kadar riskli olduğuna bakmadan en yüksek skoru kovalar; bu durum öğrenmenin dengesizleşmesine ve zaman zaman çöküşlere yol açar. Bu makale, TDC-λ (Lambda Alt Güven Sınırı ile İkiz Dağılımsal Eleştirmenler) adlı bir yöntem sunarak ajanlara yalnızca yüksek hedeflemeyi değil, aynı zamanda öğrenirken güvenli kalmayı da öğretir.
Öğrenen Makinelerde İstikrarın Neden Önemli Olduğu
Yaygın olarak kullanılan TD3 ve Soft Actor–Critic (SAC) gibi standart sürekli kontrol algoritmaları, robotların karmaşık simülatörlerde koşmasını, zıplamasını ve dengede kalmasını mümkün kıldı. Ancak bu yöntemler tipik olarak her eylemi tek bir sayı ile değerlendirir: uzun vadede ne kadar ödül getireceğine dair bir tahmin. Bu tekil puan, öğrenme süreci gürültülü olduğunda yanıltıcı olabilir ve sistemin bazı eylemleri olduğundan daha iyi değerlendirmesine neden olur. Sonuç, ortalamada iyi görünen ama denemeler arasında vahşice dalgalanan bir öğrenme eğrisidir; bu da aynı algoritma fiziksel makineleri veya güvenlik açısından kritik sistemleri kontrol edecekse sorun yaratır.
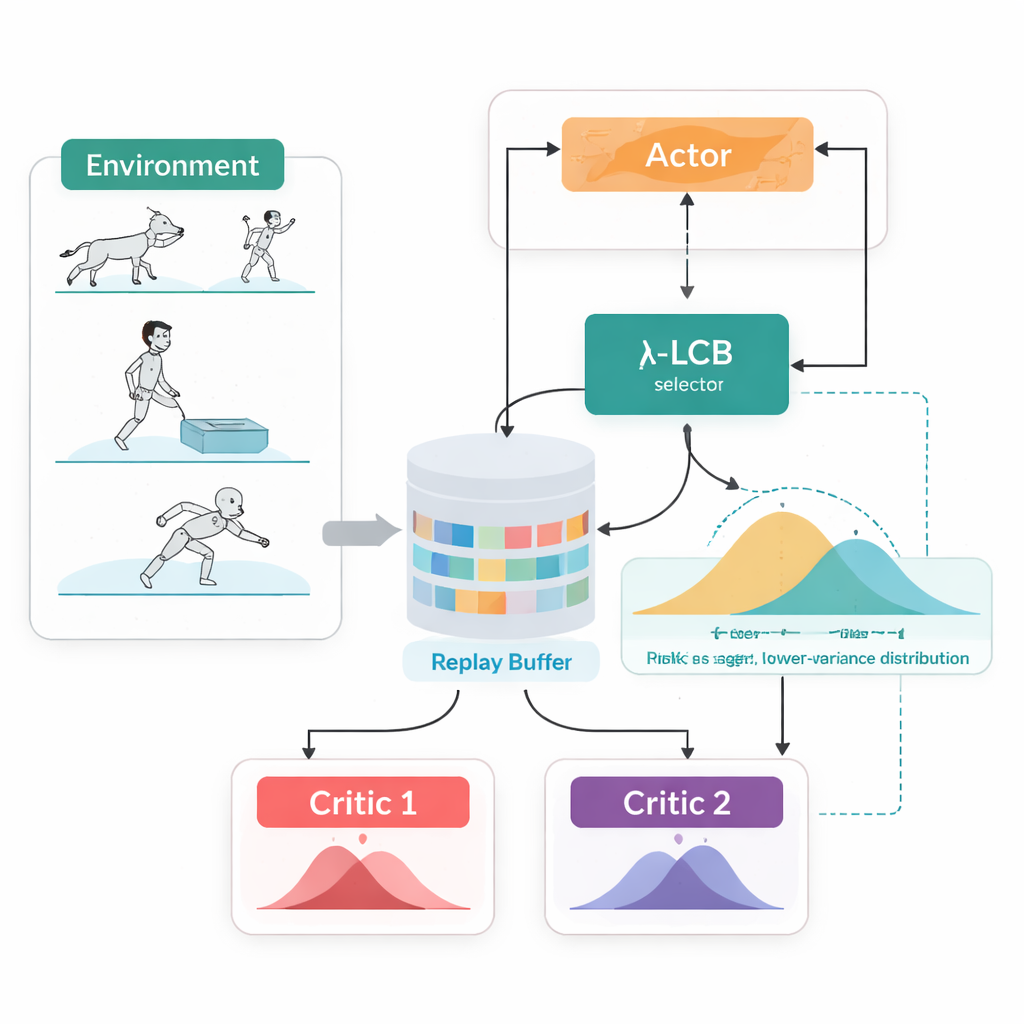
Tek Sayılar Yerine Tam Gelecekleri Görebilmek
TDC-λ, ajanın geleceği değerlendirme biçimini değiştirerek bu sorunu ele alır. Her eylem için yalnızca tek bir beklenen ödül tahmin etmek yerine, olası gelecek getirilerinin tam dağılımını çıktılayan iki ayrı "eleştirmen" öğrenir. Bu dağılımlardan algoritma yalnızca ortalamayı değil, olasılıkların ne kadar yayıldığını da hesaplar. Bu yayılma belirsizliği veya riski yansıtır. Basit bir kuralla, bir alt güven sınırı özetinde, TDC-λ daha güvenli olduğu öngörülen eleştirmeni tercih eder: biraz daha az iyimser olabilecek ama daha tutarlı kanıtlarla desteklenen bir seçimi. Bir risk parametresi olan λ, bu seçimin ne kadar tedbirli olacağını pürüzsüz biçimde ayarlar — λ sıfır iken geleneksel TD3 tarzı davranışa yakınken, λ büyüdükçe daha muhafazakâr hale gelir.
Tek Bir Eğitim Döngüsü, İki Eylem Biçimi
TDC-λ’nin bir diğer pratik özelliği, tek ve birleşik bir çerçeve içinde hem deterministik hem de stokastik eylem seçme yollarını desteklemesidir. Eğitim sırasında kullanıcılar klasik deterministik bir politika ya da eylemleri örneklemeyi teşvik eden tanh ile sıkıştırılmış Gauss politikası arasında tercih yapabilir. Bu tercih ne olursa olsun, ikiz dağılımsal eleştirmenler aynı biçimde eğitilir ve değerlendirme her zaman deterministik ortalama eylem kullanılarak yapılır. Bu tasarım, test zamanında deterministik davranışın çoğu zaman örneklemeden en az onun kadar iyi performans gösterdiği önceki bulguların avantajından yararlanırken, öğrenme sırasında zengin ve keşfi teşvik eden politikalara izin verir.
Yöntemi Sınamaya Koymak
Yazarlar TDC-λ’yi HalfCheetah, Hopper, Ant, Walker2d ve Humanoid gibi simüle robotların verimli hareket etmeyi öğrenmesi gereken beş popüler MuJoCo benchmark görevinde değerlendirdi. Bu görevler boyunca yeni yöntem, TD3, DDPG, SAC ve MEOW adlı gelişmiş akış temelli yaklaşımlar da dahil güçlü karşıt metodlarla karşılaştırıldığında nihai performansı eşitledi veya geliştirdi ve tekrarlı denemeler arasında daha düşük değişkenlik gösterdi. Humanoid gibi daha zor ve yüksek boyutlu görevlerde, daha temkinli hedef tahminlerini ifade eden biraz daha yüksek λ değerleri en iyi uzun vadeli getirileri ve en sıkı performans bantlarını verdi. Diğer simülatörlerde (PyBullet ve NVIDIA Isaac) yapılan ek deneyler ve öğrenme sinyalinin değişkenliğini izleyen tanılama çalışmaları, TDC-λ’nin öğrenmeyi yavaşlatmadan daha stabil hâle getirdiği bulgusunu güçlendirdi.
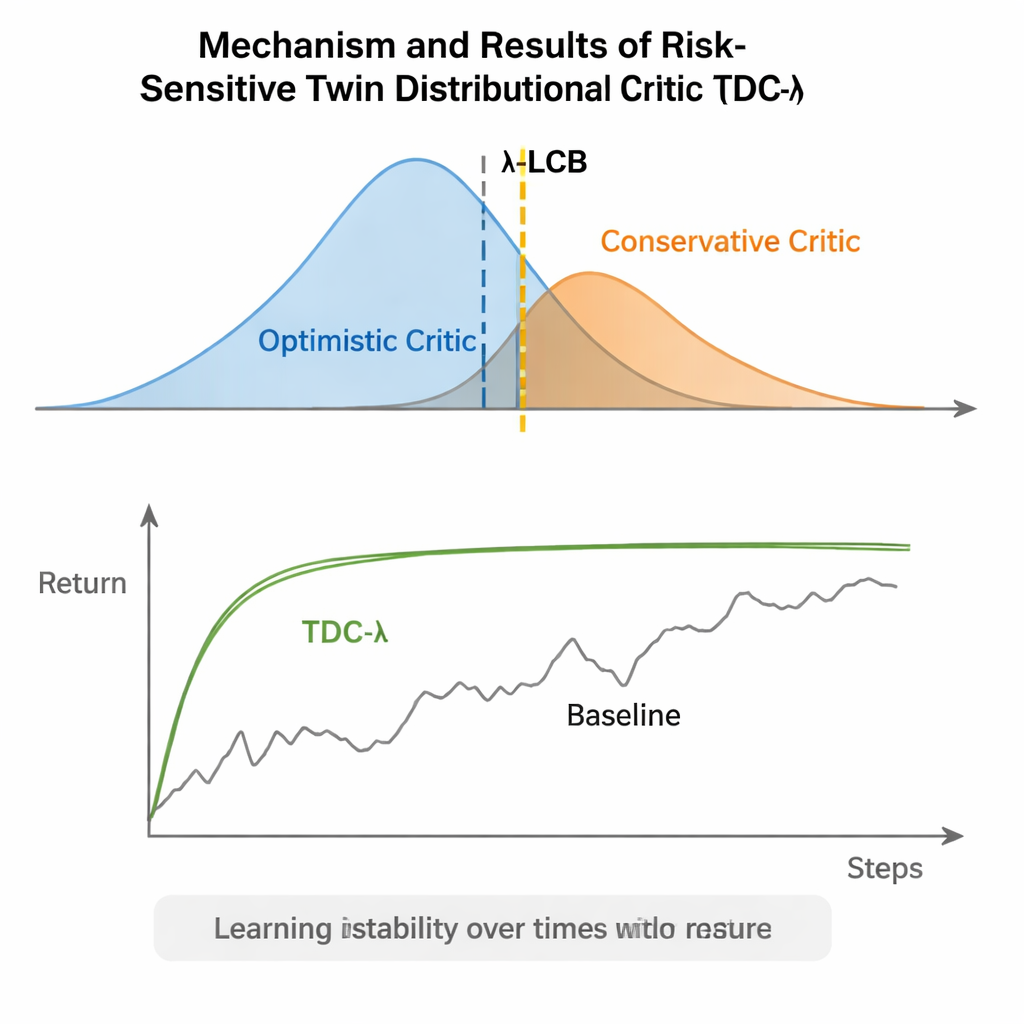
Daha Güvenli Öğrenme İçin Basit Bir Ayar
Gündelik bir ifadeyle, TDC-λ pekiştirmeli öğrenme sistemlerine kendi iyimserliklerine ne kadar güveneceklerine karar verirken bir "güvenlik marjı" sağlar. Olası sonuçların tam dağılımlarını öğrenip ardından λ düğmesiyle daha güvenli eleştirmen tarafına yaslanarak, algoritma eğitimdeki ani dalgalanmaları azaltırken yüksek nihai performansı korur. Uygulayıcılar için bu, robotlar ve diğer sürekli kontrol sistemleri için daha güvenilir denetleyiciler oluşturmanın pratik bir yolunu sunar: orta derecede muhafazakâr bir λ ile başlayın ve öğrenme süreci ne kadar dalgalı görünüyorsa ona göre ayarlayın. Daha geniş mesaj ise şudur: ajanın ne öğrenmesinin hedeflendiğini —yani eğitim hedeflerini— dikkatle biçimlendirmenin, genellikle daha karmaşık mimarilere atfedilen sağlamlığın büyük bir kısmını sağlayabileceği ve gelişmiş pekiştirmeli öğrenmeyi hem daha istikrarlı hem de daha erişilebilir kıldığıdır.
Atıf: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Anahtar kelimeler: pekiştirmeli öğrenme, sürekli kontrol, risk duyarlı öğrenme, dağılımsal eleştirmenler, robotik