Clear Sky Science · tr
Karmaşık uzaylarda yığın tabanlı evrimsel bir çerçeve kullanarak kanser mikroarray verilerinde öznitelik seçiminin optimize edilmesi
Doğru genleri seçmenin önemi
Modern genetik teknolojilerle yapılan kanser testleri aynı anda on binlerce geni ölçebilir, ancak doktorların ellerinde genellikle sadece birkaç düzine hasta verisi olur. Bu devasa “gen ormanı”nın içinde, bir kanser türünü diğerinden ya da tümörü sağlıklı dokudan gerçekten ayıran çok daha az sayıda sinyal gizlidir. Bu makale, bu kilit genleri otomatik olarak seçmeye yönelik yeni bir akıllı arama yöntemini sunuyor; amaç bilgisayar destekli kanser tanısının daha doğru, daha hızlı ve daha kolay yorumlanabilir olmasını sağlamak.
Çok fazla sinyal, çok az veri
Mikroarray deneyleri ve benzeri teknolojiler, her hasta örneğinde binlerce genin etkinlik düzeyini ölçmeyi mümkün kılar. Yine de örnek sayısı genellikle çok azdır; bazen yüzün bile altındadır. Bu gen okumalarının birçoğu gürültülü, birbirinin tekrarı ya da hastalıkla ilgisiz olabilir. Hepsini tutmak öğrenme algoritmalarını bunaltabilir, hesaplamayı yavaşlatabilir ve modellerin gerçek biyoloji yerine rastgele tuhaflıklara tutunmasına yol açabilir. Bunu kullanışlı bir alt kümeye indirme sürecine “özellik seçimi” denir ve yüksek boyutlu tıbbi verilerden güvenilir tahminler almak istiyorsak hayati önem taşır.
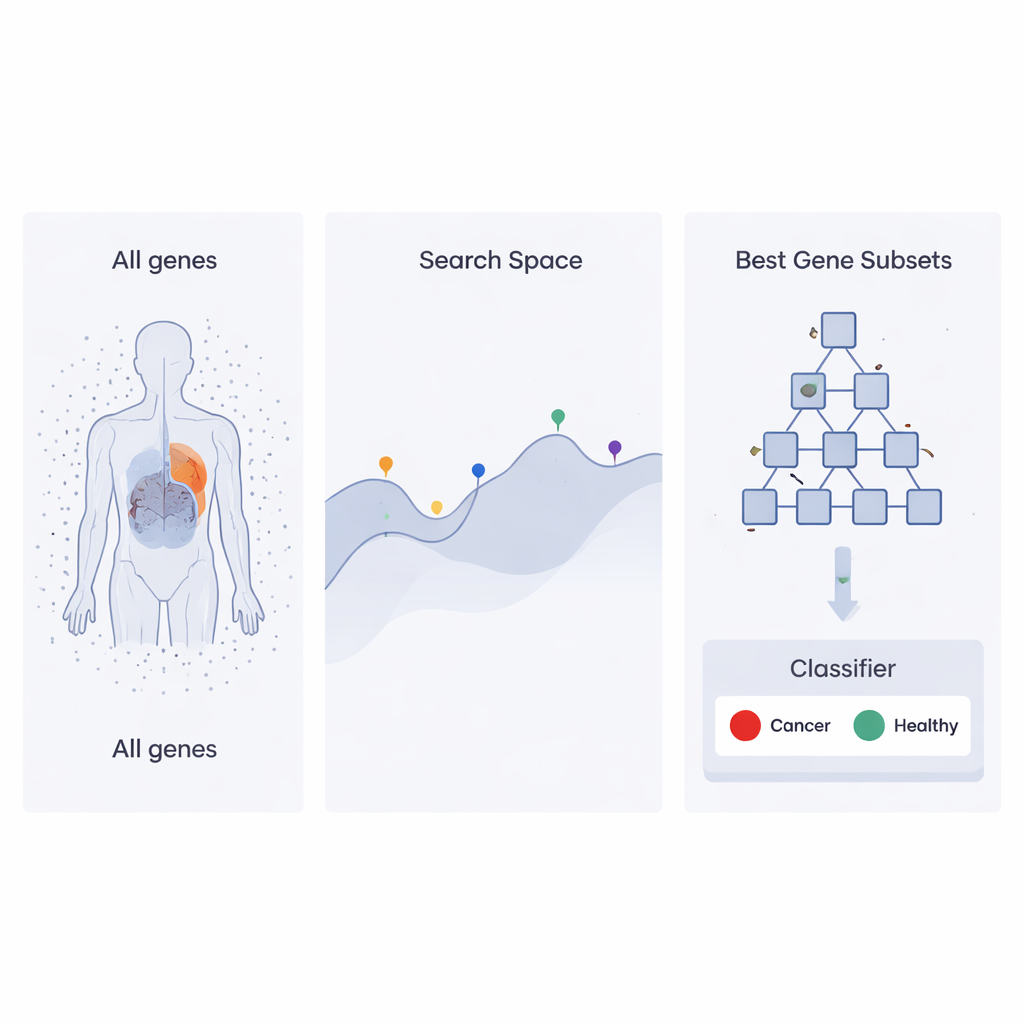
Şirket hiyerarşilerinden ilham alan bir arama stratejisi
Yazarlar, çalışanların bir şirkette nasıl organize edildiği fikirlerinden yararlanan Yak‑Temelli Optimizatör (HBO) adı verilen yakın tarihli bir optimizasyon yaklaşımı üzerine inşa ediyor. Her olası gen kümesini, performansı bir sınıflandırıcının kanser örneklerini sağlıklardan ayırmadaki başarısıyla değerlendirilen bir “çalışan” olarak hayal edin. Bu çalışanlar, bilgisayar yapısı olarak bilinen bir yığın (heap) kullanılarak bir merdiven gibi bir hiyerarşide dizilir. Yüksek performans gösteren gen kümeleri üstlerde yer alırken, zayıf olanlar daha aşağıdadır. Birçok tur boyunca, alt sıradaki çalışanlar patronlarının ve meslektaşlarının yaptığı seçimleri kopyalayarak ve bunları hafifçe değiştirerek tercihlerini ayarlar; bu süreç tüm organizasyonu daha iyi çözümlere doğru iter.
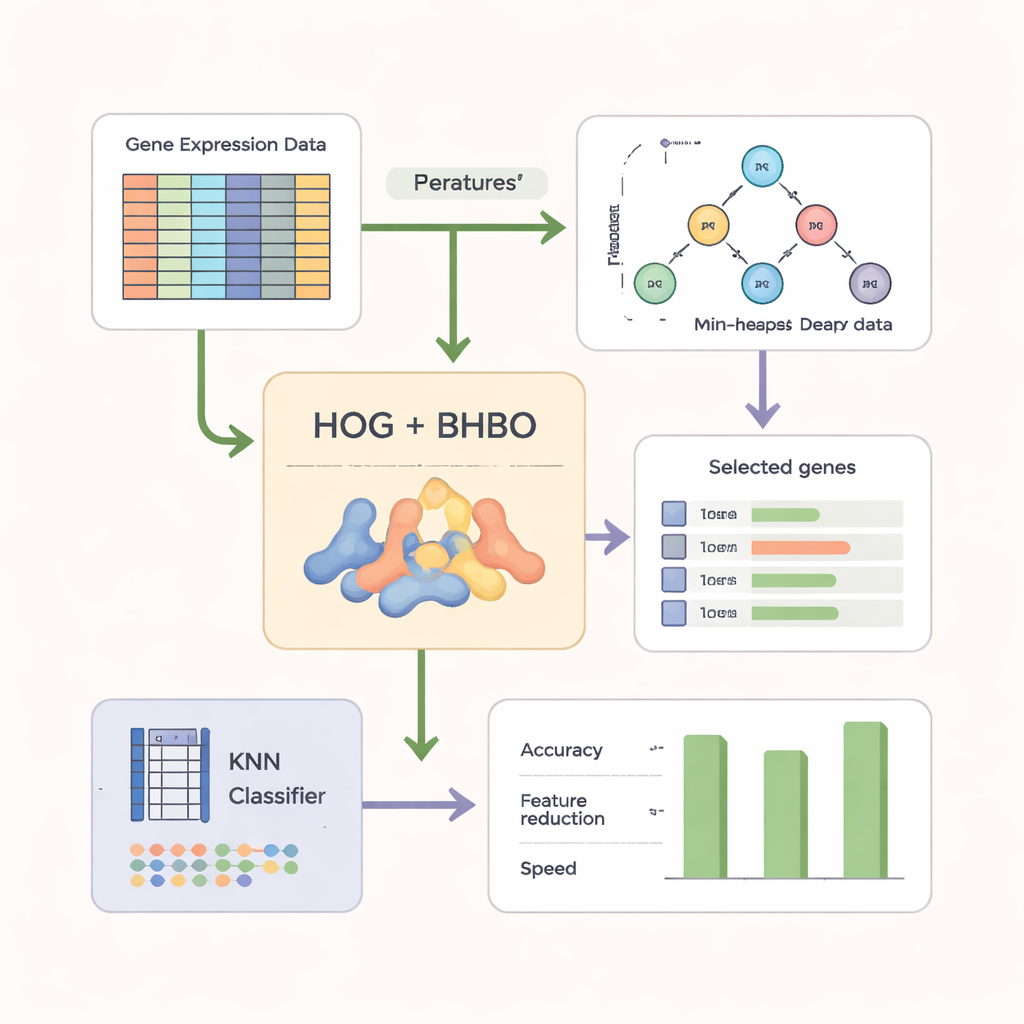
Ham gen verilerini daha keskin desenlere dönüştürmek
Aramayı daha etkili kılmak için yazarlar yalnızca ham gen okumalarına dayanmaz. Önce mikroarray verilerini görüntü benzeri bir forma yeniden şekillendirirler ve bilgisayarla görmede yaygın olarak kullanılan Eğilimlerin Yönelim Histogramı (Histogram of Oriented Gradients, HOG) adlı bir tekniği uygularlar. HOG, ifade düzeylerinin genler boyunca nasıl değiştiğini yakalar ve izole ölçümler yerine yerel desenleri vurgular. Bu desen tabanlı özellikler daha sonra orijinal gen bilgisiyle birleştirilir. Basit bir sınıflandırıcı olan k-En Yakın Komşu (KNN), her aday gen alt kümesini yeni örnekleri ne kadar doğru etiketlediğine göre puanlayan “hakem” işlevi görür; aynı zamanda daha küçük, daha kompakt kümeleri ödüllendirir.
Birden çok kanser veri kümesi üzerinde test
Araştırmacılar, Yığın‑Tabanlı Optimizatörün (BHBO) ikili versiyonunu beyin tümörleri, lösemiler, prostat kanseri ve birçok alt tipe sahip karışık tümör koleksiyonları dahil olmak üzere dokuz halka açık kanser mikroarray veri kümesi üzerinde değerlendirdi. Her veri kümesinde ölçülen gen sayısı binlerden on beş binden fazlaya kadar değişirken hasta örnek sayısı nispeten azdı. Her veri kümesi için BHBO tekrar tekrar çalıştırıldı ve genetik algoritmalar ve parçacık sürüsü optimizasyonu gibi yedi iyi bilinen arama yöntemiyle karşılaştırıldı. Ekip yalnızca doğruluğu değil, ayrıca tutulan gen sayısını, aramanın ne kadar hızlı yakınsadığını ve sonuçların simüle edilmiş gürültü, batch etkileri ve etiket hatalarıyla veriler bozulduğunda ne kadar kararlı kaldığını da ölçtü.
Yeni yöntemin elde ettikleri
Dokuz veri kümesi genelinde, yığın odaklı yaklaşım yaklaşık %95 ortalama sınıflandırma doğruluğuna ulaşırken gen sayısını %85’ten fazla azalttı. Birkaç veri kümesinde açıkça rakip yöntemleri geride bıraktı ve daha hızlı yakınsama gösterdi; yani daha az arama adımında iyi gen kümelerine odaklandı. Yazarlar verileri kasıtlı olarak bozduklarında—gürültü ekleyerek veya bazı örnek etiketlerini çevirerek—yöntemin performansı yalnızca biraz düştü ve yine alternatiflerden daha iyi kaldı. İstatistiksel testler bu kazanımların şansa bağlı olma olasılığının düşük olduğunu doğruladı.
Gelecekteki kanser tanıları için ne anlama geliyor
Pratik açıdan bu çalışma, dikkatle tasarlanmış bir arama stratejisinin devasa genetik veri kümelerini eleyebileceğini ve hâlâ kanserleri çok iyi sınıflandıran, küçük ve bilgi açısından zengin gen panellerini ortaya çıkarabileceğini gösteriyor. Klinikler ve araştırmacılar için böyle kompakt gen setleri biyolojik olarak doğrulaması daha kolay, takip testlerinde ölçülmesi daha ucuz ve karar destek araçlarına entegrasyon için daha uygundur. Yöntem doğrudan yeni ilaçlar veya yollar keşfetmese de, yüksek boyutlu kanser verilerinde gömülü en bilgilendirici sinyallere odaklanarak umut vadeden genetik belirteçlerin üzerine spot ışığı tutar ve diğer çalışmaların en önemli sinyallere yönelmesine yardımcı olur.
Atıf: Alweshah, M., Jebril, H., Kassaymeh, S. et al. Optimizing feature selection in cancer microarray data using a heap-driven evolutionary framework for high-dimensional spaces. Sci Rep 16, 6726 (2026). https://doi.org/10.1038/s41598-026-37803-5
Anahtar kelimeler: kanser mikroarray, özellik seçimi, meta-sezgisel optimizasyon, gen belirteçleri, tıbbi veri madenciliği