Clear Sky Science · tr
Büyük dil modellerinin diş hekimliği uzmanlık sınavındaki performansına karşılaştırmalı bir analiz
Geleceğin diş hekimleri için akıllı sohbet botları neden önemli
Yapay zekâ, doktorların ve diş hekimlerinin öğrenme ve çalışma biçimini hızla değiştiriyor. En görünür araçlardan biri, birçok popüler yapay zekâ asistanının arkasındaki teknoloji olan büyük dil modelleriyle güçlendirilmiş konuşma tabanlı sohbet botları. Bu çalışma basit ama önemli bir soruyu sordu: diş hekimliği öğrencileri bu araçları oral ve maksillofasiyal radyoloji gibi rekabetçi bir uzmanlık sınavına hazırlanmak için kullansalar, makineler gerçekte ne kadar başarılı olurdu?
Gerçek bir sınavda yapay zekâyı test etmek
Bunu öğrenmek için araştırmacılar, gelişmiş eğitim programlarına kimin kabul edileceğini belirleyen Türkiye'deki Dişhekimliği Uzmanlık Sınavı'na (DUS) başvurdu. Bu ülke çapındaki sınavın geçmiş yıllarından, radyoloji uzmanlarının ustalaşması gereken konuları kapsayan 208 çoktan seçmeli soru seçtiler; radyasyon fiziği ve görüntüleme tekniklerinden çene tümörleri ve sinüs hastalıklarına kadar. Soruların çoğu yalnızca metin içeriyordu, ancak daha küçük bir alt küme radyografik görüntülerin yorumlanmasını gerektiriyordu; bu da gerçek tanısal çalışmayı yansıtıyordu.
Aynı meydan okumayı yedi sohbet botu yanıtladı
Araştırma ekibi daha sonra her bir soruyu Türkçe olarak yedi yaygın kullanılan büyük dil modeli tabanlı sohbet botuna yöneltti: iki ChatGPT sürümü ile birlikte Gemini, Copilot, DeepSeek, Claude ve Grok. Her soru dikkatle ve ayrı ayrı girildi, böylece konuşmalar arasında bilgi taşınması önlendi. İkinci bir araştırmacı her bir yapay zekâ yanıtını resmi cevap anahtarıyla karşılaştırdı ve doğru ya da yanlış olarak işaretledi. Son olarak yazarlar, modelleri genel olarak ve belirli konu alanları içinde karşılaştırmak için standart istatistiksel testler kullandı.
En yüksek puanı kim aldı—ve nerede tökezlediler
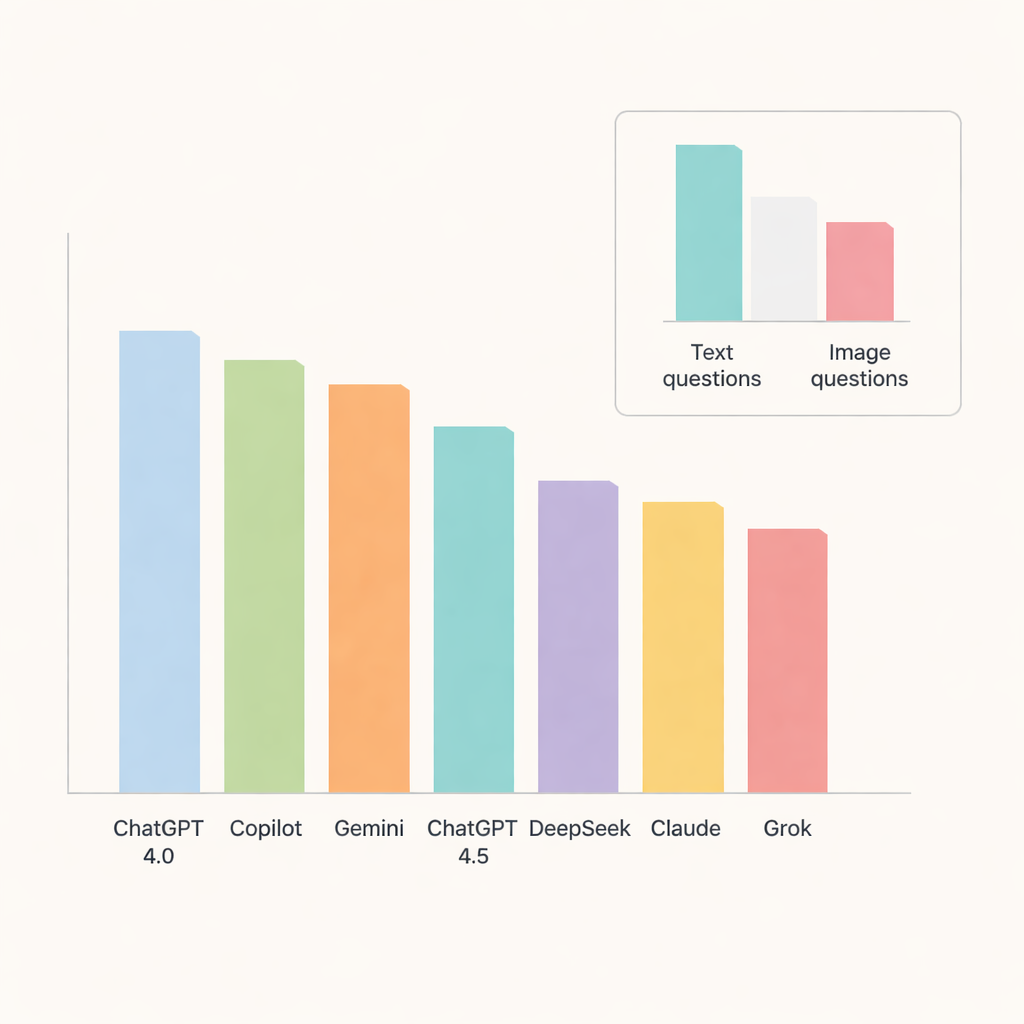
Tüm sohbet botları arasında ChatGPT 4.0 öne çıktı ve soruların yaklaşık %91'ine doğru yanıt verdi. Copilot ve Gemini onu orta-yüksek 80'lerde doğrulukla yakından izledi, ChatGPT 4.5, DeepSeek, Claude ve Grok ise biraz daha geride kaldı. Araştırmacılar konulara daha ayrıntılı baktıklarında, modellerin özellikle oral patoloji ve tükürük bezi hastalıklarında çok iyi performans gösterdiğini; doğruluğun %90'a yaklaştığını veya aştığını gördüler. Buna karşılık, radyografik anatomi ve yumuşak doku kalsifikasyonları belirgin şekilde daha zordu; bu alanlar sistemler genelinde puanları düşürdü ve yapay zekânın ince ayrıntılarda hâlâ zorlandığını işaret etti.
Görüntüler hâlâ metinden daha zor
Ana testlerden biri sohbet botlarının görüntüleri metin kadar iyi işleyip işleyemeyeceğiydi. Burada sınırlamaları belirginleşti. Görüntü tabanlı sorularda doğruluk keskin şekilde düştü, en iyi performans gösteren modeller için bile. ChatGPT 4.0, Gemini ve Copilot bu kategoride önde geldi ancak görsel soruların yalnızca yaklaşık üçte ikisini doğru yanıtladı. DeepSeek görüntülerde en kötü performansı gösterdi; doğruluk biraz üçte birin üzerindeydi. Çoğu model için metin ve görüntü performansı arasındaki fark istatistiksel olarak anlamlı olacak kadar büyüktü; bu da tıbbi görüntü yorumlamanın günümüzün genel amaçlı yapay zekâları için hâlâ zor bir görev olduğunu vurguluyor.
Öğrenciler ve hastalar için anlamı
Çalışmanın temel sonucu, modern sohbet botlarının özellikle radyolojide bilgi gözden geçirme ve sınav tarzı sorularla pratik yapma konusunda diş hekimliği eğitiminde güçlü yardımcılar olabileceği yönünde. Ancak en güçlü sistemler bile—özellikle görsel olarak zorlu veya yüksek derecede spesifik konularda—yeterince hata yapıyor; bu nedenle uzman yargısının güvenli bir şekilde yerini alamazlar. Öğrenciler ve klinisyenler için bu araçlar, bağımsız otoriteler olarak değil, akıllı çalışma ortakları ya da karar destek araçları olarak görülmelidir. Uygun dikkat ve denetimle kullanıldıklarında öğrenmeyi hızlandırabilir ve yüksek kaliteli açıklamalara erişimi genişletebilirler; tanı ve tedavi üzerindeki nihai sorumluluk ise eğitimli profesyonellerde kalmalıdır.
Atıf: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Anahtar kelimeler: dental eğitim, yapay zeka, büyük dil modelleri, oral ve maksillofasiyal radyoloji, tıbbi sınavlar