Clear Sky Science · tr
Dengesiz veri kümeleri için GAN tabanlı artırma kullanarak diller arası SMS istenmeyen mesaj tespiti
Metin mesajlarınızın neden hâlâ korunmaya ihtiyacı var
Çoğumuz istenmeyen mesajların sessizce bir istenmeyen posta klasörüne düşeceğine güveniriz, ancak perde arkasında bu çok zor bir problemdir. Gerçek spam, günlük mesajlara kıyasla nadirdir ve giderek aynı anda birçok dilde ortaya çıkar. Bu makale, güçlü dil modellerini akıllıca bir “sahte veri” üreticisiyle harmanlayarak tehlikeli SMS spam’lerini tespit etmenin yeni bir yolunu sunuyor; böylece filtreler, gizliliğinizi riske atmadan kötü mesaj örneklerinden çok daha fazlasını öğrenebiliyor.
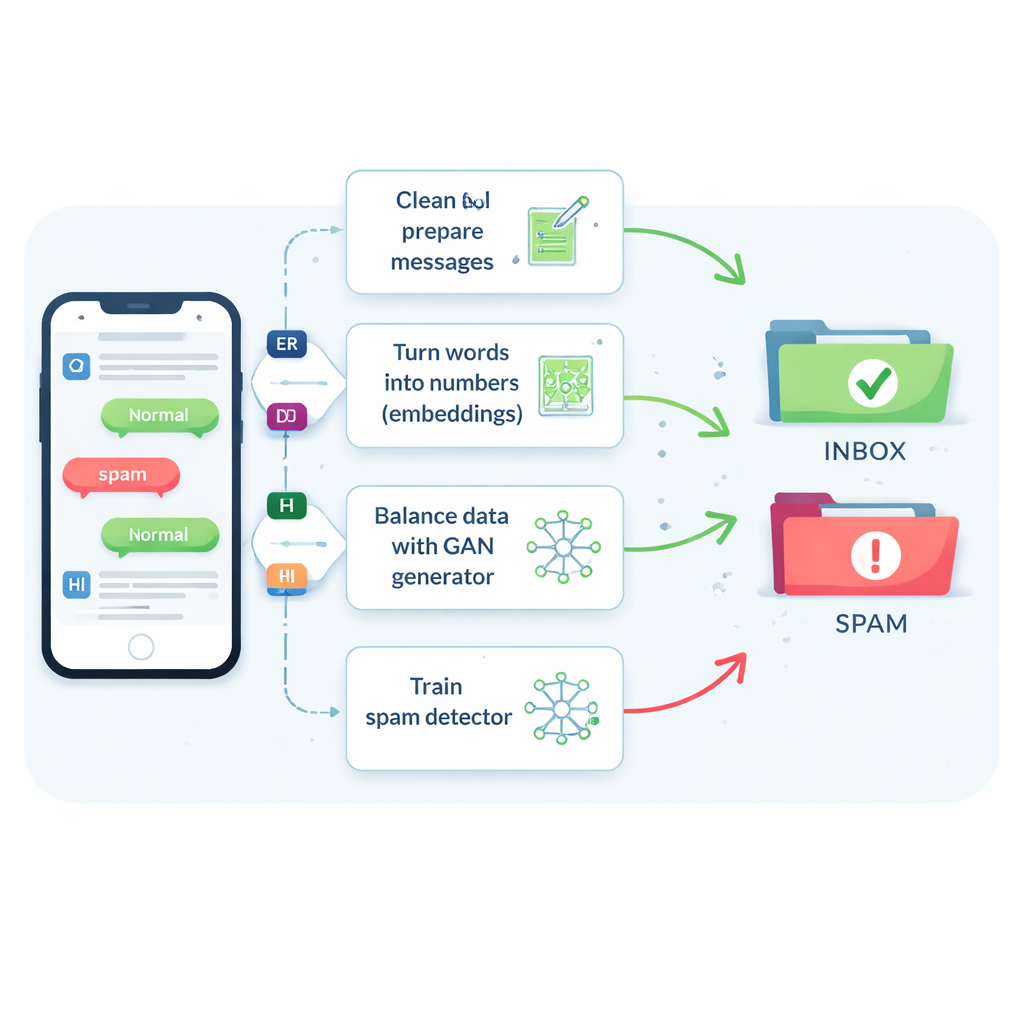
Nadir ve biçim değiştiren spam ile ilgili sorun
Spam mesajlar tüm mesajların yalnızca yaklaşık yedisinde birini oluşturur, ancak bunların küçük bir kısmının bile kaçırılması insanları dolandırıcılık, kötü yazılım ve kimlik hırsızlığına maruz bırakabilir. Geleneksel filtreler, SMS’lerin kısa, argo ve kısaltmalarla dolu olması ve genellikle ek bağlam olmadan gerçek zamanlı olarak gelmesi nedeniyle zorlanır. Sonuç olarak birçok sistem mesajları güvenli kabul etmeye eğilimlidir; bu kullanıcıları memnun eder fakat daha zararlı mesajların gözden kaçmasına yol açar. Spam mesajlarını basitçe çoğaltan veya kelimeleri değiştirerek yeni örnekler uyduran eski aldatmacalar bir miktar yardımcı olabilir, ancak genellikle filtreyi yanıltır veya suçluların gerçekten gönderdiği örneklere uymayan gerçek dışı örnekler yaratır.
Aygıtların mesaj anlamını öğrenmesi
Yazarlar, destek vektör makineleri ve karar ağaçları gibi tanıdık araçlardan, metni bir dizi olarak okuyan uzun-kısa süreli bellek (LSTM) ağları gibi daha gelişmiş sinir ağlarına kadar sekiz farklı öğrenme algoritmasını karşılaştırarak başlıyor. Ayrıca sözcükleri bilgisayarın kullanabileceği sayılara çevirmenin beş yolunu test ediyorlar. Her bir kelimenin ne sıklıkta göründüğünü sayan basit yöntemler (bag-of-words veya TF–IDF olarak bilinir) hızlıdır ancak anlamı göremez. Word2Vec ve GloVe gibi daha yeni “gömme” yöntemleri, benzer anlamdaki kelimeleri sayısal bir uzayda birbirine yakın yerleştirir. En gelişmiş olanlar ise BERT gibi dönüştürücü tabanlı modellerdir; bunlar bir kelimenin temsilini çevresindeki cümleye göre ayarlar ve sistemin örneğin dostça bir hatırlatmayı ikna edici bir dolandırıcılıktan ayırmasına yardımcı olur.
Dengesiz veri kümesini düzeltmek için akıllı “sahte” spam kullanmak
Çalışmanın merkezi yeniliği, spam örneklerinin eksikliğini nasıl ele aldığıdır. Tam sahte cümleler üretmek yerine ekip, spam mesajlarının sayısal gömmeleri üzerinde doğrudan bir tür sinir ağı olan Üretici Çekişmeli Ağ (GAN) eğitiyor. GAN’ın bir bölümü olan üretici, bu yüksek boyutlu uzayda spam benzeri sentetik noktalar yaratmayı öğrenirken, diğer bölüm olan ayrımcı bunları gerçeklerden ayırmayı öğreniyor. Bu rekabet sayesinde üretici, eğitim setini genişleten gerçekçi yeni spam gömmeleri üretiyor. Benzerliğe dayalı bir kalite kontrolü yalnızca gerçek spama yakından benzeyen sentetik örneklerin tutulmasını sağlayarak, sınıflandırıcıyı yanılabilecek anlamsız verilerin riskini azaltıyor.
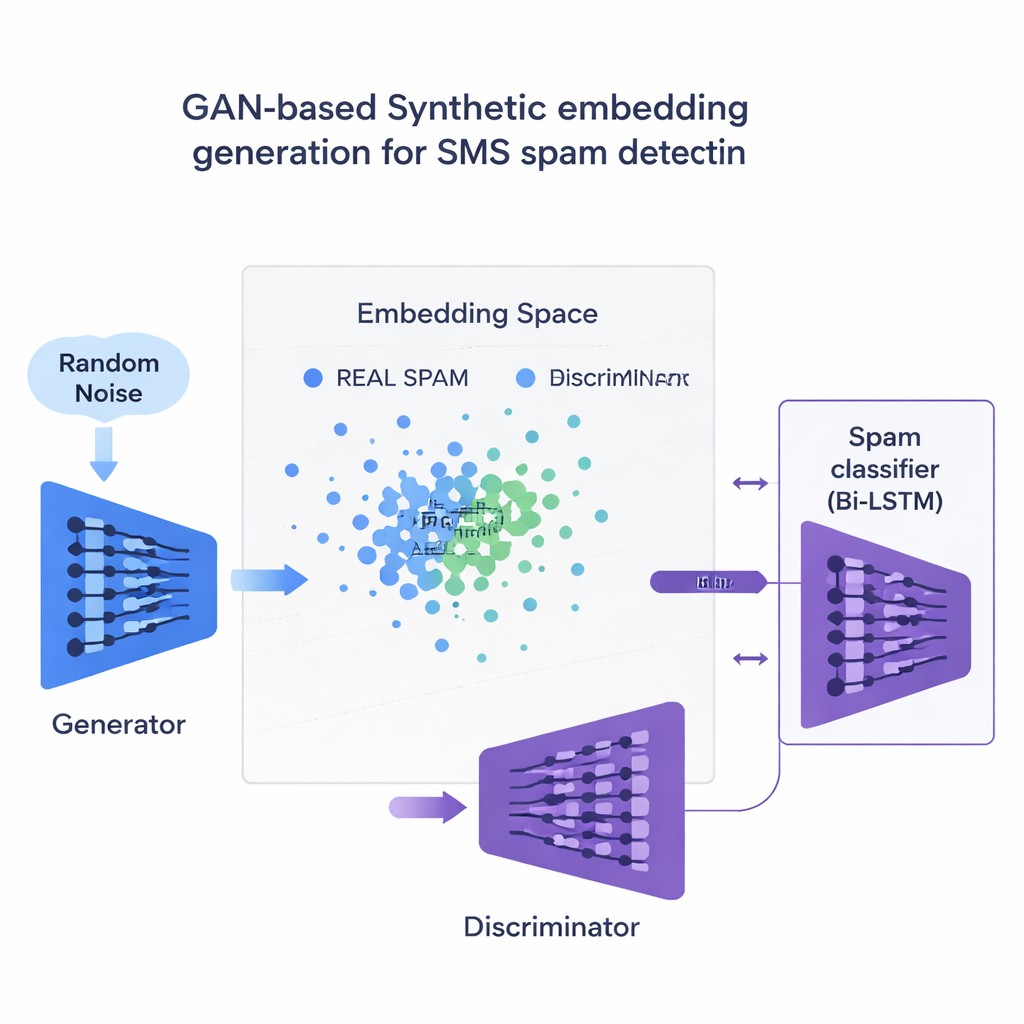
Diller ve cihazlar arasında elde edilen sonuçlar
Araştırmacılar, modellerin, gömmelerin ve veri dengeleme yöntemlerinin 120 farklı kombinasyonunu hem İngilizce bir SMS veri kümesinde hem de Fransızca, Almanca ve Hintçe’ye çevrilmiş çokdilli bir versiyonda test ediyor. Genel olarak, BERT gibi bağlamsal gömmeler eski kelime-sayım yaklaşımlarından daha iyi performans gösteriyor. En iyi düzen—BERT gömmeleriyle beslenen iki yönlü bir LSTM ve GAN tarafından üretilen spam örnekleriyle eğitilmiş—İngilizce mesajlarda yaklaşık %97,6 F1-skora ve çokdilli sette %94,4’e ulaşıyor ve mevcut en iyi sistemleri geride bırakıyor. Kritik olarak, bu başarı sahte alarm oranlarını son derece düşük tutarken elde ediliyor; tek kullanımlık şifreler ve banka bildirimlerinin yanlışlıkla kullanıcıdan gizlenmemesi açısından bu önemli. Çalışma ayrıca bu GAN stratejisini SMOTE ve ADASYN gibi daha yaygın dengeleme araçlarıyla karşılaştırıyor; GAN’ın daha temiz, daha gerçekçi eğitim verileri ürettiğini ve genel performansta hafifçe daha iyi olduğunu buluyor.
Günlük kullanıcılar için bunun anlamı
Uzman olmayanlar için çıkarılacak ders şu: spam filtreleri artık yalnızca bireysel kelimeleri değil, mesajlarınızın anlamını ve bağlamını anlamaya başlıyor ve gerçek metinlerinizi daha fazla görmeye gerek kalmadan özenle hazırlanmış sentetik verilerle “öğretilebiliyor”. Mesaj anlamının kodlandığı uzayda doğrudan çalışarak önerilen yöntem, güvenlik sistemlerine birçok dilde spam’in nasıl göründüğüne dair daha zengin bir resim sunuyor ve hantallık içeren sahte örneklerle sistemi doldurmuyor. Bu, tehlikeli mesajların yakalanma olasılığını artırırken gerçek mesajların teslim edilmesini sağlamayı kolaylaştırıyor ve dolandırıcılar taktiklerini değiştirmeye devam ettikçe mobil kullanıcılar için daha güçlü, daha uyarlanabilir bir koruma sunuyor.
Atıf: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Anahtar kelimeler: SMS istenmeyen mesaj tespiti, GAN veri artırımı, BERT metin gömme, çokdilli siber güvenlik, mobil oltalama