Clear Sky Science · tr
Video dizilerinde şiddet tespiti için hafif bir konvolüsyonel sinir ağı mimarisi
İnsanların İzlemesine Gerek Kalmadan Kalabalıkları Gözetlemek
Konserlerden spor arenalarına, metro istasyonlarından alışveriş merkezlerine kadar kameralar artık neredeyse her kalabalık alanı izliyor. Yine de bu video akışlarının çoğu hâlâ uykulu insan gözleriyle denetleniyor ve kavganın ya da izdihamın ilk işaretleri kolayca kaçabiliyor. Bu makale, düşük maliyetli donanımda bile canlı videoyu gerçek zamanlı tarayabilecek ince, hızlı bir yapay zekânın nasıl şiddet davranışını tespit edebileceğini inceliyor; böylece güvenlik çalışanlarının durum kontrolden çıkmadan önce hızlıca müdahale etmesine yardımcı oluyor.
Videoda Şiddeti Farketmenin Neden Bu Kadar Zor Olduğu
İlk bakışta bir bilgisayardan “kavga” ile “kavga yok”u ayırt etmesini istemek basit görünebilir: insanlar birbirine vuruyorsa tespit et. Gerçekte sorun karmaşık. Aydınlatma zayıf olabilir veya aniden değişebilir, kalabalık görüşü engelleyebilir ve kameralar çok farklı açılara yerleştirilmiş olabilir. Dolu bir rock konseri tehlike olmasa bile kaotik görünürken, bir boks maçı şiddetli görünür ama ringin içinde tamamen normaldir. Geleneksel görme sistemleri çerçeve çerçeve elle tasarlanmış hareket desenleri ve kenarlar üzerine odaklanıyordu; laboratuvarda işe yarasalar da yoğun, gerçek dünya gözetim ağları için genellikle çok yavaş veya yetersiz doğrulukluydular.
Kamera Akışları İçin Daha İnce Bir Beyin
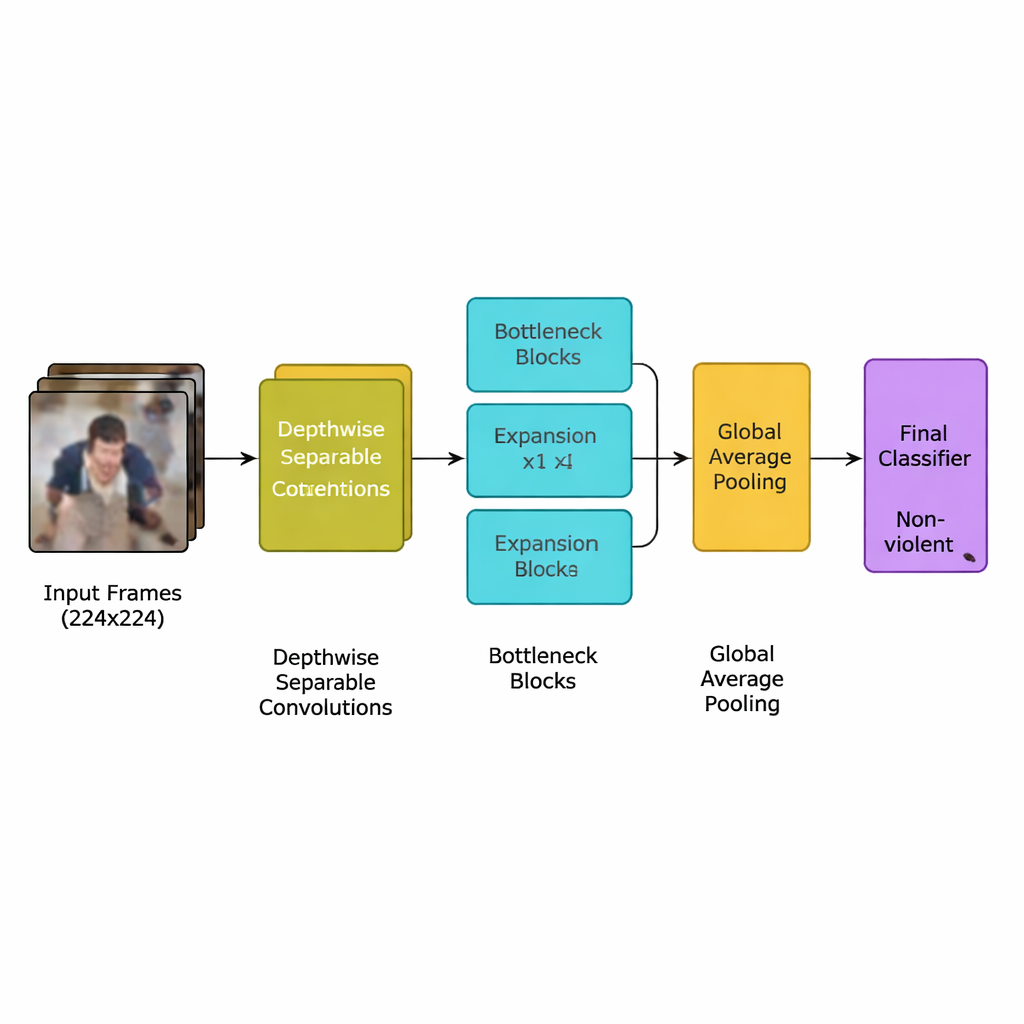
Yazarlar bu görev için özel olarak tasarlanmış yeni bir derin öğrenme modeli sunuyor: MobileNetV2 ailesinden türetilmiş hafif bir konvolüsyonel sinir ağı (CNN). Güç isteyen ağır katmanlar yerine ağ, hesaplama miktarını ciddi şekilde azaltan derinlik ayrımsal (depthwise separable) convolüsyonlara dayanıyor—küçük, hedefe yönelik işlemler. Ayrıca bilgiyi kısa süreli genişletip sonra sıkıştırarak önemli hareket ipuçlarını koruyup gereksizliği eleyen “ters şişe boyun” (inverted bottleneck) blokları kullanıyor. Buna ek olarak ekip, ağın uzay ve zamandaki şiddetle ilişkili hareket desenlerine odaklanmasını sağlayan squeeze-and-excitation adı verilen bir dikkat mekanizması ekliyor; böylece dikkat dağıtan arka plan ayrıntıları göz ardı edilebiliyor.
Ham Videodan Şiddet Uyarılarına
Tam sistem açık bir iş akışını izliyor. Önce video akışları çerçevelere bölünüyor ve neredeyse kopyaları kaldırmak ama genellikle bir kavganın işareti olan ani hareketleri korumak için yalnızca her beşinci çerçeve tutuluyor. Çerçeveler standart 224×224 piksele yeniden boyutlandırılıyor, arka plan gürültüsünü azaltmak için hafifçe bulanıklaştırılıyor ve modelin farklı kamera görüş açılarına uyum sağlamayı öğrenmesi için eğitim sırasında rastgele çevriliyor veya döndürülüyor. Bu hazırlanmış görüntüler hafif CNN’e besleniyor; ağ ham pikselleri kademeli olarak daha yüksek düzeyde kalabalık davranışı desenlerine dönüştürüyor. Her çerçeveyi özetleyen son bir havuzlama adımından sonra küçük bir sınıflandırıcı basit bir karar veriyor: şiddetli veya şiddetsiz. Model yalnızca yaklaşık 1,94 milyon parametre kullandığı için—MobileNet ve MobileNetV2 atalarından daha az—uzaktaki bir veri merkezinde değil, kameraların yanına yerleştirilmiş mütevazı cihazlarda gerçek zamanlı çalışabiliyor.
Sistemi Teste Sokmak
Bu kompakt tasarımın daha hacimli ağlarla rekabet edip edemeyeceğini görmek için araştırmacılar onu iki yaygın kullanılan kıyas seti üzerinde eğitti ve değerlendirdi. Real‑Life Violence Situations Dataset, YouTube’dan toplanmış 2.000 kısa klip içeriyor; bunlar günlük sahneleri ve çeşitli mekanlardaki gerçek kavgaları gösteriyor. Hockey Fight Dataset ise sıradan oyun ile buz üzerindeki kavgalara ayrılmış 1.000 profesyonel hokey maçı klibi sunuyor. Bu veri setlerinde önerilen model, gerçek hayat senaryolarında yaklaşık %97, hokey görüntülerinde %94 civarında doğru etiketleme yaptı; InceptionV3 ve VGG‑19 gibi daha büyük CNN’lerle eşleşti veya onları geride bıraktı ve çok daha az hesaplama kullandı. İki veri seti arasında çapraz test—birinde eğitip diğerinde test etme—sisteminin hâlâ makul performans gösterdiğini ortaya koydu; bu da modelin tek bir ortamı ezberlemek yerine genel hareket desenlerini yakaladığını düşündürüyor.
Günlük Güvenlik İçin Anlamı
Uzman olmayanlar için temel çıkarım şu: artık dev sunuculara veya sürekli insan gözetimine ihtiyaç duymadan, potansiyel şiddeti hızlı ve ekonomik şekilde işaretleyebilen kamera sistemleri kurmak mümkün. Çalışma, dikkatle budanmış ve ayarlanmış bir sinir ağının aynı anda birçok akışı izleyebileceğini, tehlikeli davranış tespit ettiğinde uyarı gönderebileceğini ve yine de toplu taşıma merkezleri, okullar, hastaneler ve şehir sokakları için uygun düşük güçlü donanımlarda çalışabileceğini gösteriyor. Çok karanlık sahnelerin, yoğun kalabalıkların veya ses ipuçlarının eklenmesi gibi zorluklar devam etse de bu çalışma, akıllı kameraların yorulmadan erken uyarı sensörleri gibi davranabileceği; güvenlik ekiplerinin insan gözetçileri üzerindeki yükünü hafifleterek insanları daha etkili korumasına yardımcı olacağı bir geleceğe işaret ediyor.
Atıf: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Anahtar kelimeler: şiddet tespiti, video gözetimi, hafif CNN, MobileNetV2, kamu güvenliği