Clear Sky Science · tr
Kullanıcı etkinliğine dayalı DNS parmak izi
Web gezintileriniz neden gizli bir iz bırakır
Her web gezinmeniz sırasında bilgisayarınız, Alan Adı Sistemi (DNS) adlı özel bir adres kitabına, her siteye nasıl ulaşılacağını sessizce sorar. Bu sorgular kaybolmaz. Günler ve haftalar içinde hangi tür siteleri ziyaret ettiğinizin, ne zaman ve ne sıklıkla ziyaret ettiğinizin bir desenini oluştururlar. Bu makale, bu desenlerin davranışsal bir parmak izi gibi ayırt edici olabileceğini, güçlü algoritmaların görünür IP adresiniz değişse bile kullanıcıları ayırt etmesine izin verebileceğini gösteriyor; bu durum hem güvenlik için fırsatlar hem de önemli gizlilik soruları doğuruyor.
İnternetin telefon rehberi ve alışkanlıklarınız
DNS, www.google.com gibi insan tarafından okunabilir web adreslerini bilgisayarların birbirleriyle konuşmak için kullandığı sayısal IP adreslerine çevirmek için vardır. Çoğu insan bunun hiç farkında değildir, ancak her arama, video akışı, e‑posta kontrolü veya uygulama güncellemesi bir veya daha fazla DNS sorgusunu tetikler. Bu sorgular genellikle yerel veya genel DNS sunucuları tarafından işlenir ve hangi IP adresinin hangi alan adını ne zaman sorduğu gibi basit kayıtlar olarak tutulur. Yeterince bu kayıtları toplarsanız, bir kullanıcının iş araçlarından bulut depolamaya, sosyal ağlardan akış platformlarına kadar hangi çevrimiçi hizmetlere güvendiğine dair ayrıntılı bir resim elde edersiniz. Önceki araştırmalar bu izleri kötü amaçlı yazılımları tespit etmek veya cihaz türlerini tanımlamak için kullanmışken, bu çalışma daha doğrudan bir soruyu soruyor: yineleyen DNS davranışlarından yalnızca bireysel kullanıcılar veya makineler tespit edilebilir mi?
Günlük tıklamaları davranışsal bir parmak izine dönüştürmek
Yazarlar, bir yerel internet sağlayıcısından üç aylık süre boyunca toplanmış büyük, herkese açık bir DNS veri kümesi üzerine inşa ediyor. Her gün, her etkin IP adresi için DNS etkinliğini kompakt bir özet halinde topluyorlar: toplam sorgu sayıları, kaç farklı alan adına başvurulduğu ve kritik olarak bu alan adlarının “Genel İş,” “Yazılım / Donanım” veya “Sosyal Ağlar” gibi 75 içerik kategorisinden hangilerine düştüğü. Kullanıcı başına yeterli geçmiş sağlamak için yalnızca günlerin en az yüzde 80’inde görünen IP adreslerini tutuyor, ayrıca yinelenen veya neredeyse boş özellikleri dikkatle çıkarıyorlar. Çok yüksek korelasyonlu alanları tespit etmek için istatistiksel araçlar uyguluyor, sorgu hacminde aşırı aykırı değerleri filtreliyor ve sonra ana bileşen analiziyle veriyi sıkıştırarak faydalı varyasyonun büyük kısmının çok daha az boyutta korunmasını sağlıyorlar. Temizlenmiş veriyi t‑SNE adlı bir teknikle görselleştirince, birçok IP adresinin sıkı, iyi ayrılmış kümeler oluşturduğunu görüyorlar — bu, otomatik sınıflandırmanın mümkün olabileceğine dair erken bir işaret.
Makine öğrenimi modellerini teste sokmak
İşlenmiş veri kümesi hazır olduğunda ekip, kullanıcı tanımlamayı devasa bir sınıflandırma problemi olarak ele alıyor: bir günlük DNS istatistikleri verildiğinde bunun hangi 1.727 IP adresinden geldiğine karar verin. Naive Bayes ve Random Forests gibi klasik yöntemlerden XGBoost ve derin sinir ağları gibi daha gelişmiş araçlara kadar bir dizi modeli karşılaştırıyorlar. Her model farklı veri versiyonları (ham, yeniden ölçeklenmiş, standartlaştırılmış veya boyutu azaltılmış) üzerinde eğitilip doğrulanıyor ve doğru sınıfı ne sıklıkla atadığı, hassasiyet ve duyarlılık ölçüleriyle değerlendiriliyor. Geleneksel modeller makul bir performans sergiliyor — Random Forests yaklaşık yüzde 73 doğruluğa ulaşıyor ve XGBoost yüzde 81’i aşarken tüm sınıfların yüzde 99’dan fazlasını doğru biçimde ayırt ediyor. Ancak öne çıkan performans sinir ağlarına ait; özellikle günlük davranışın tek boyutlu bir görüntüsüymüş gibi özellik vektörünü ele alan özel bir konvolüsyonel sinir ağı (CNN) dikkat çekiyor.
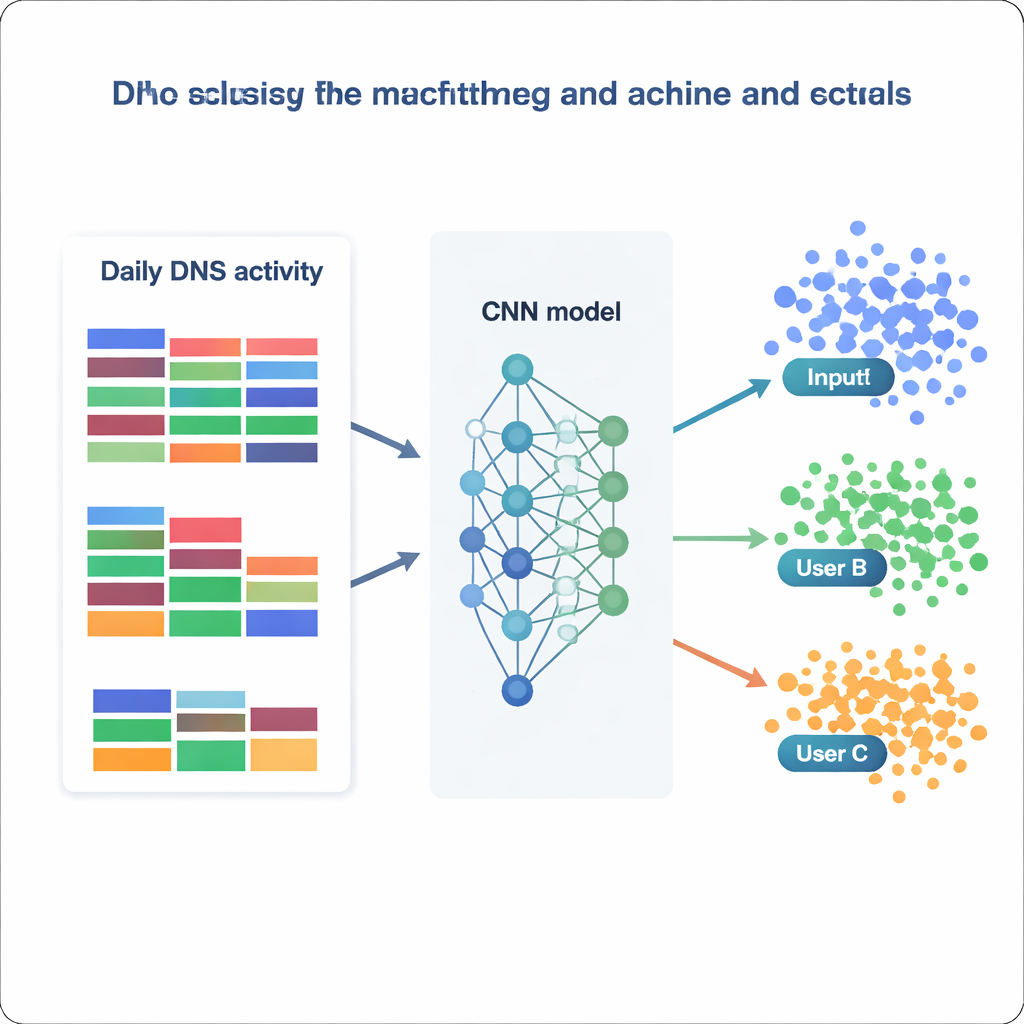
Bir model sizi "kim" olarak ne kadar iyi tanıyabilir?
Normalleştirilmiş veriler üzerinde eğitilmiş en iyi CNN, ayrılmış günlerin neredeyse yüzde 87’sinde kaynak IP’yi doğru belirliyor ve 1.727 ayrı IP adresinin 1.694’ünü başarıyla tahmin ediyor. Pratik açıdan bu, çoğu kullanıcının — veya paylaşılan bir IP arkasında gizlenen küçük grupların — zaman içinde istikrarlı, tanınabilir DNS desenleri sergilediğini gösteriyor. Modellerin en çok hangi özelliklere dayandığını incelediklerinde yazarlar iki tamamlayıcı strateji buluyorlar. Bazı modeller genel iş veya yazılım hizmetleri gibi çok yaygın kategorilere güçlü şekilde yaslanarak geniş alışkanlıkları yakalıyor. XGBoost gibi diğerleri ise güvenlik, siyaset veya niş ilgi alanlarına bağlı nadir ama belirleyici kategorilerden ekstra güç kazanıyor. Birlikte, bu sonuçlar tam alan adı listesini incelemeden bile basit, toplanmış istatistiklerin kullanıcıları çarpıcı bir güvenilirlikle yeniden tanımlamak için yeterli yapıyı kodlayabileceğini gösteriyor.
Söz, sınırlar ve gizlilik dengesi
Hukuk uygulayıcıları ve ağ savunucuları için DNS parmak izleri tekrar eden suçluları izleme, ele geçirilmiş makineleri tespit etme veya engellemeden kaçmak için değiştiren IP adresleri kullanan botnetleri saptama konusunda değerli bir araç haline gelebilir. Aynı zamanda çalışma belirgin sınırları vurguluyor: DNS parmak izleri bir genel IP tek bir kullanıcıya bağlı olduğunda en kararlı oluyor; bu durum günümüz IPv4 dünyasında NAT üzerinden birçok kullanıcının tek bir adres paylaştığı ortamdan ziyade modern IPv6 ağlarında daha gerçekçidir. DNS sunucularının veya genel Wi‑Fi ağlarının sık sık değişmesi sinyali zayıflatır. En önemlisi, çalışma sıradan kullanıcıların fark etmesinin zor olduğu bir gizlilik riskini öne çıkarıyor. Çünkü DNS kaydı büyük ölçüde görünmez ve pasiftir, davranışsal izleme çerezler veya müdahaleci betikler yüklemeden gerçekleşebilir. Yazarlar veri setlerini ve modellerini açıkça paylaşıyor; şeffaf araştırmanın, toplumun DNS tabanlı parmak izi oluşturmanın güvenlik yararlarını sessiz gözetim potansiyeliyle tartıp hangi korumaların ve politikaların bu güçlü yeni çevrimiçi tanımlama biçimini düzenlemesi gerektiğine karar vermesi için gerekli olduğunu savunuyorlar.
Atıf: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Anahtar kelimeler: DNS parmak izi, kullanıcı takibi, internet gizliliği, ağ güvenliği, makine öğrenimi