Clear Sky Science · tr
Derin çok etiketli öğrenmede tak-çalıştır ilişki güçlendirme modülleri üzerine araştırma
Makinelere çok sayıda etiketi yönetmeyi öğretmek
Çevrimiçi mağazalar, hukuk arşivleri ve tıbbi veri tabanları, her yeni belgeyi hızla doğru etiketlerle işaretleyebilen yazılımlara dayanır. Ancak modern sistemler sıklıkla on binlerce ya da milyonlarca olası etikete—ürün kategorilerinden tıbbi konulara—maruz kalırken her metin yalnızca birkaç etikete ihtiyaç duyar. Bu makale, mevcut derin öğrenme modellerinin etiketlerin gerçek veride birlikte nasıl göründüğünü daha iyi kullanmasına yardımcı olan ve metin etiketlemede doğruluğu ve hızı artıran Label Correlation Enhancement Network (LCENet) adlı yeni bir eklentiyi tanıtıyor.
Web ölçeğinde etiketlemenin neden bu kadar zor olduğu
Birçok gerçek dünya uygulaması, araştırmacıların aşırı çok etiketli metin sınıflandırması dediği sınıfa girer: kısa bir açıklama veya uzun bir belge verildiğinde sistem, muazzam bir katalogdan ilgili etiketlerin küçük bir alt kümesini seçmelidir. Örnekler arasında e-ticaret sitesinde ürünlere kategori atama, biyomedikal makaleleri MeSH terimleriyle indeksleme, reklamları web sayfalarına eşleme veya yasal metinleri ayrıntılı yasal kodlara haritalama bulunur. Bu durumlar üç ortak zorluk paylaşır: etiket listesi son derece büyüktür, çoğu etiket nadirdir ve her metin yalnızca birkaç etiket kullanır. Geleneksel teknikler ya problemi birçok küçük sınıflayıcıya böler ya da etiketleri daha düşük boyutlu vektörlere sıkıştırır, ancak genellikle basit kelime sayımlarına dayanır ve anlamı ya da etiketler arasındaki ilişkileri tam olarak yakalayamazlar.
Standart derin modellerin hâlâ kaçırdığı noktalar
Konvolüsyonel ağlar, yinelemeli ağlar ve BERT gibi Dönüştürücü tabanlı modeller gibi modern derin öğrenme yaklaşımları, zengin anlamsal temsil öğrenerek metin anlama yeteneğini büyük ölçüde geliştirdi. Ancak hemen hemen hepsi son adımda önemli bir basitleştirme yapar: metin bir vektöre kodlandıktan sonra her etiketi bağımsız olarak tahmin ederler. Oysa pratikte etiketler güçlü biçimde etkileşir. "Diyabet" ile etiketlenmiş bir tıbbi makale genellikle "insülin direnci"ni de içerirken, "akıllı telefon" etiketi taşıyan bir cihaz genelde "elektronik" ve "iletişim cihazları" ile ilişkilidir. Bu örüntüleri göz ardı etmek, modellerin yüksek güvenli etiketleri zayıf olanları desteklemek için kullanamamasına neden olur ve birlikte mantıksız kombinasyonlar üretme riski doğar.
Etiket ilişkilerini öğrenen bir eklenti
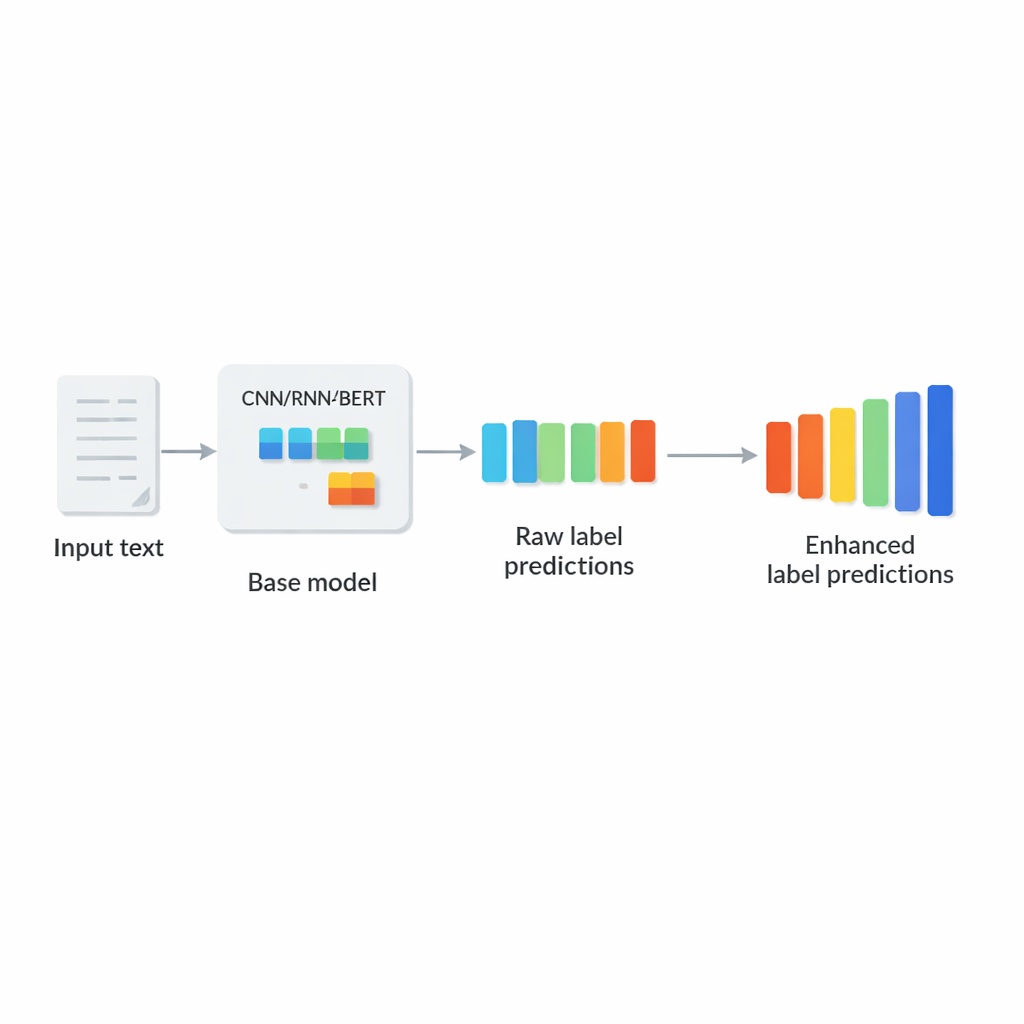
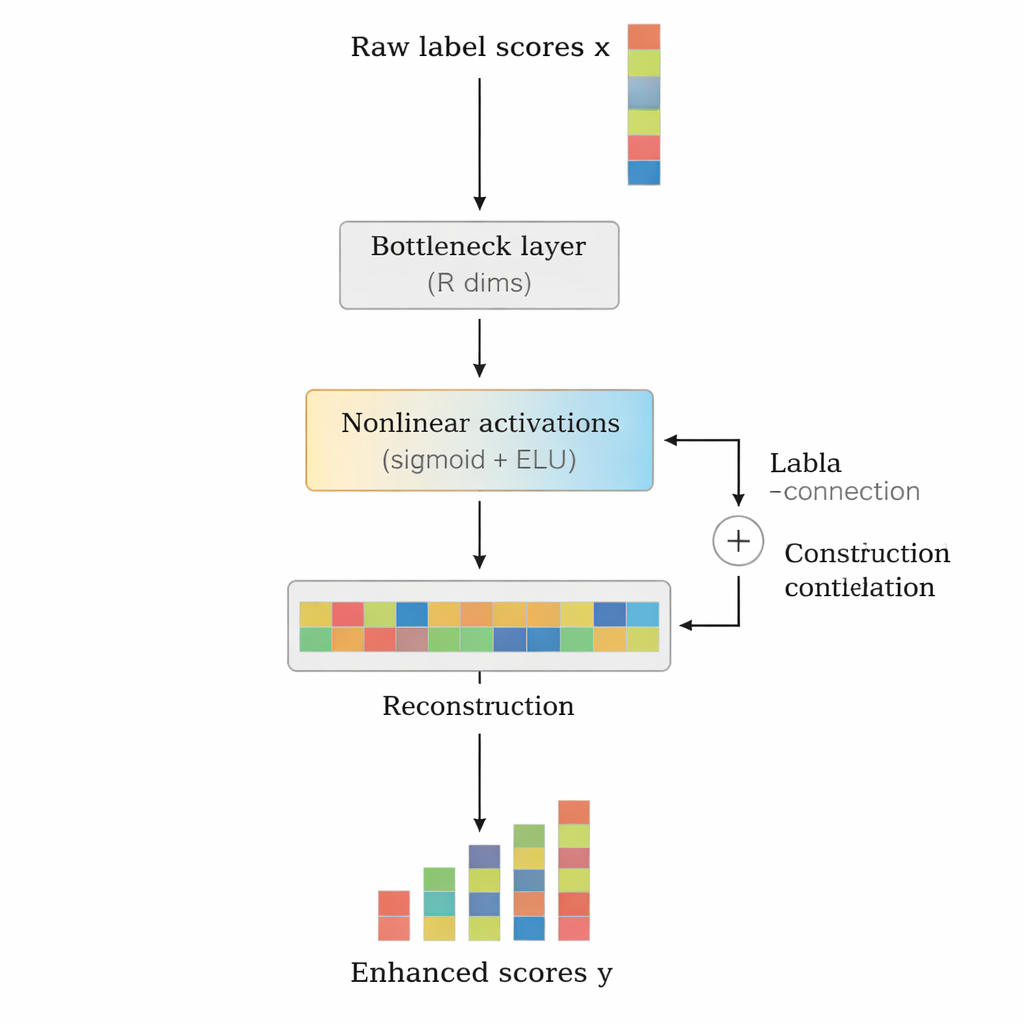
Yazarlar, herhangi bir mevcut derin metin sınıflayıcının sonuna oturan hafif, tak-çalıştır bir modül olarak LCENet'i önerir. Temel modelin metni nasıl okuduğunu değiştirmek yerine LCENet, ürettiği ham etiket skorlarını alır ve ilişkili etiketlerin birlikte kümelendiği düşük boyutlu bir temsili keşfetmeye zorlayan kompakt bir "darboğaz"dan geçirir. Doğrusal olmayan aktivasyon fonksiyonları, modülün yalnızca basit çift yönlü bağlantıları değil, karmaşık, daha yüksek dereceli ilişkileri de yakalamasına izin verir. Bir rezidüel ya da atlama bağlantısı, orijinal skorları düzeltilmiş skorlarla birlikte doğrudan çıktıya ileterek eğitimi stabilize eder ve eklentinin işi kolayca kötüleştirmesini engeller. Kritik olarak, LCENet ek parametre sayısını etiket sayısının karesiyle büyüyecek bir yapıdan çok daha yönetilebilir bir doğrusal büyümeye indirger, böylece yüz binlerce etikete sahip durumlarda bile uygulanabilir kalır.
Modeller ve veri setleri çapında faydaların kanıtlanması
LCENet'in gerçekten genel olup olmadığını test etmek için yazarlar, onu CNN tabanlı ve BERT tabanlı mimariler de dahil olmak üzere dört çok farklı derin modele ve biyomedikal ile aşırı etiketli ortamlara özel tasarlanmış sistemlere ekledi. Bu kombinasyonları üç açık benchmark veri setinde değerlendirdiler: bir Avrupa hukuk korpusu (EUR-Lex), bir Amazon ürün veri seti (AmazonCat-13K) ve yarım milyondan fazla etikete sahip devasa bir Wikipedia koleksiyonu (Wiki-500K). Tüm modeller, veri setleri ve sıralamaya odaklı altı metrikte LCENet sürekli olarak performansı iyileştirdi; bazen en büyük veri setinde top-1 doğruluğu beş yüzde puanından fazla artırdı. Eğitim eğrileri ayrıca LCENet'in genellikle belirli bir doğruluğa ulaşmak için gereken eğitim adımı sayısını neredeyse yarıya indirdiğini gösterdi; çünkü eklenen etiket-ilişkilendirme yapısı baştan daha net öğrenme sinyalleri sağlar.
Günlük sistemler için neden önemli
Metin etiketleme için hâlihazırda derin modellere güvenen uygulayıcılar için LCENet, sistemlerini yeniden tasarlamadan veya yeni türde anotasyonlar toplamadan doğruluk ve eğitim hızını artırmanın pratik bir yolunu sunar. Etiket alanını kendisi bir bilgi kaynağı olarak ele alır; hangi etiketlerin birlikte hareket etme eğiliminde olduğunu veya birbirini dışladığını öğrenir ve ardından tahminleri buna göre yönlendirir. Metin için geliştirildiği halde, çıktılar arasındaki öğrenilmiş ilişkileri kullanarak tahminleri güçlendirme fikri görsellerde, çok modlu veride ve diğer yapılandırılmış tahmin görevlerinde de uygulanabilir. Basitçe söylemek gerekirse, LCENet makinelerin etiketlerin nasıl ilişkilendiğini “hatırlamasına” yardımcı olur; böylece tahminler izole onay kutuları gibi değil, kavramların nasıl uyduğunu bilen bilgili bir insan gibi daha tutarlı olur.
Atıf: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Anahtar kelimeler: aşırı çok etiketli metin sınıflandırması, etiket ilişkilendirmesi, derin öğrenme, metin sınıflandırması, sinir ağları