Clear Sky Science · tr
Etiket grafiği optimizasyonu ve hibrit kayıp fonksiyonları ile çapraz modal geri getirmeyi geliştirme
Görüntüler ve Sözcükler Arasında Daha Akıllı Arama
Her gün fotoğraf, video ve metin denizlerinde kaydırma yapıyoruz. Tam olarak aradığımız şeyi bulmak—örneğin kısa bir altyazıya uyan tüm resimler—bilgisayarların görüntülerle dili ne kadar iyi bağlayabildiğine bağlıdır. Bu makale, özellikle birçok fikrin ve nesnenin aynı anda göründüğü dağınık, gerçek dünya sahnelerinde bu bağı daha doğru kurmanın yeni bir yolunu araştırıyor. Sonuç, sadece yazdığımızı değil ne demek istediğimizi daha iyi “anlayan” daha akıllı arama araçlarıdır.
Bir Resimde Birden Çok Anlamın Neden Önemli Olduğu
Tek bir görüntü nadiren yalnızca tek bir şeyi gösterir. Denizde sıçrayan bir balinanın fotoğrafı aynı anda okyanusu, gökyüzünü, dalgaları, rüzgarı ve vahşi yaşamı içerebilir. Böyle bir resmi etiketlediğimizde genellikle birbirleriyle ince bağları olan birkaç etiket ekleriz. Mevcut arama sistemleri çoğunlukla bu etiketleri ilgisiz onay kutuları gibi ele alır. Bu basitleştirme yararlı ipuçlarını atar: eğer “balina” sıklıkla “deniz” ile birlikte görünüyorsa, birini görmek diğerinin olasılığını artırmalıdır. Bu çalışma, bir fikir için yapılan aramanın buna yakın olan görüntüleri ve metinleri de bulabilmesi için etiketler arasındaki gizli bağları yakalamaya odaklanıyor.

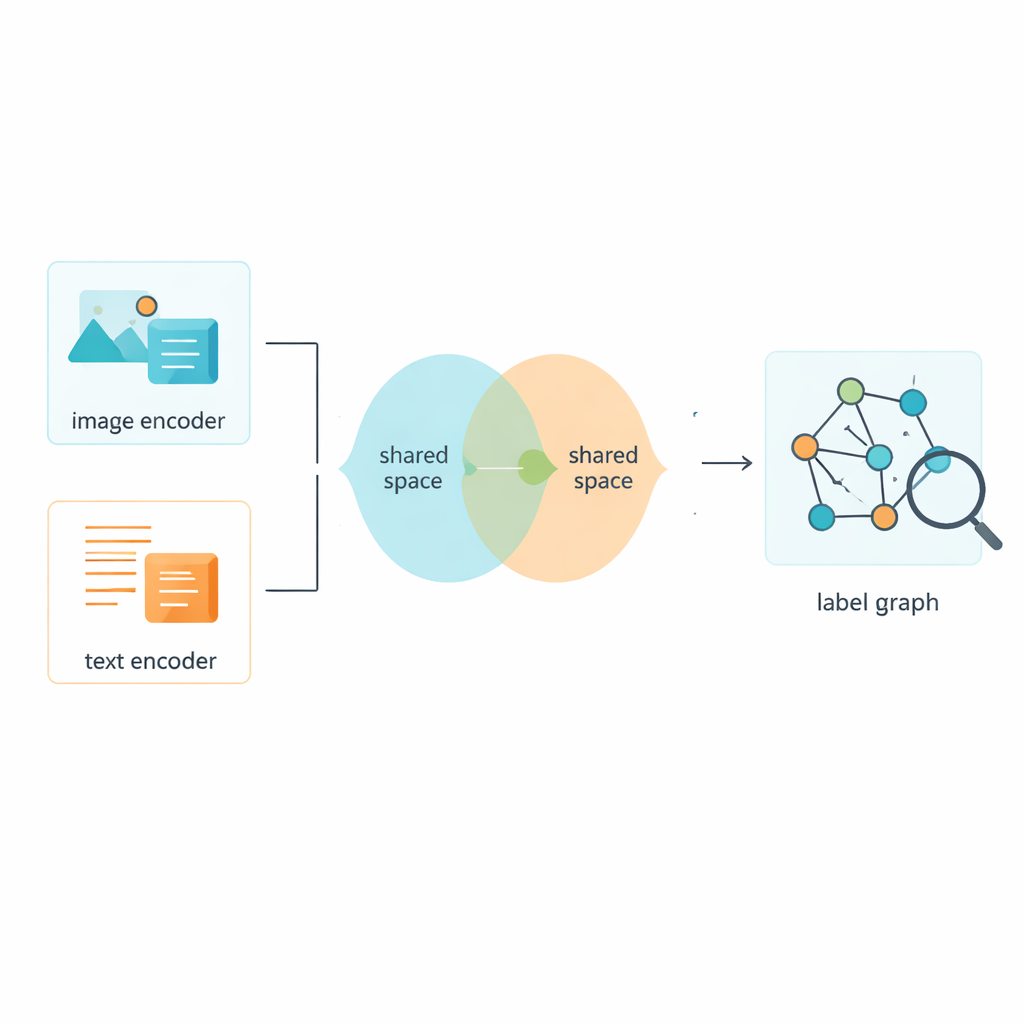
Bağlantılı Etiketler Ağı Kurmak
Yazarlar, etiketlerin birbirleriyle nasıl ilişkili olduğunu modellemek için İki Katmanlı Graf Konvolüsyonel Ağ (L2-GCN) adını verdikleri bir tekniği tanıtıyor. Basitçe söylemek gerekirse, her etiket (örneğin “gökyüzü” veya “balina”) ağda bir nokta olarak ele alınıyor ve noktalar arasındaki çizgiler bu etiketlerin ne sıklıkla birlikte göründüğünü yansıtıyor. Yöntem, her etikete komşularını “dinleme” ve ilişkili etiketlerden gelen bilgileri kendi kimliğini korurken harmanlama imkânı veriyor. Bu işlemden sonra sistem, paralel fikirlerden (“deniz” ve “plaj”) daha katmanlı ilişkilere kadar (“hayvan” ve “balina”) gerçek sahnelerin yapısını daha iyi yakalayan zengin etiket tanımları elde ediyor.
Görüntüleri ve Metinleri Ortak Bir Alanda Eğitmek
Elbette etiketler hikâyenin sadece yarısı; sistemin görüntülerden ve metinlerden de öğrenmesi gerekiyor. Çerçeve, ham pikselleri ve sözcükleri sayısal özelliklere dönüştürmek için yerleşik araçları kullanıyor ve ardından her iki tür veriyi anlamlarının doğrudan karşılaştırılabileceği ortak bir alana itiyor. Jeneratif karşıt ağların itme-çekme mantığından esinlenen bir karşıt modül, modelin yalnızca görüntülerin veya yalnızca metnin tuhaflıklarına tutunmasını caydırıyor. Bu, ortak alanın biçim yerine içeriğe odaklanmasına yardımcı oluyor; böylece hareketli bir sokağın fotoğrafı ile onu tanımlayan kısa bir altyazı bu ortak anlam haritasında birbirine yakın konumlanıyor.
Daha Keskin Ayrımlar İçin Hibrit Bir Eğitim Stratejisi
Böyle bir sistemi eğitmek tek bir öğrenme kuralından daha fazlasını gerektirir. Yazarlar, Circle-Soft adını verdikleri birleşik bir kayıp fonksiyonu tasarlıyor ve bu fonksiyon iki tamamlayıcı fikri harmanlıyor. Bir bölüm aynı kategoriden örneklerin sıkı bir şekilde kümelenmesini teşvik ederken farklı kategorileri esnek, uyarlanabilir bir şekilde uzaklaştırıyor. Diğer bölüm ise aynı sahneyi tarif eden görüntülerin ve metinlerin formatlar arasında ne kadar iyi hizalandığına odaklanıyor. Ayarlanabilir bir ağırlık bu iki hedefi dengeliyor, böylece model ne sadece düzgün kategori sınırlarına ne de yalnızca çapraz modal hizalanmaya aşırı uyum sağlamıyor. İlave sınıflandırma ve karşıt kayıplar, rafine edilmiş etiketler ile ortak görüntü–metin özellikleri arasında tutarlılığı daha da teşvik ediyor.
Aramayı Ne Kadar İyileştiriyor?
Bu fikirlerin daha iyi aramaya dönüşüp dönüşmediğini görmek için yazarlar yöntemi MIRFlickr, NUS-WIDE ve MS-COCO olmak üzere üç popüler gerçek dünya görüntü–metin koleksiyonunda test etti. Bu veri kümeleri, binlerce ila yüz binlerce fotoğrafı etiketler veya altyazılarla içeriyor ve şehir sokaklarından vahşi yaşama kadar günlük sahneleri kapsıyor. Üç benchmark genelinde yeni yaklaşım, etiket tabanlı grafik modellemeyi zaten kullanan diğer gelişmiş sistemler de dahil olmak üzere çok sayıda rakip yöntemi tutarlı şekilde geride bıraktı. Kazançlar—katı bir getirme skorunda yaklaşık yarım puandan bir tam puana kadar—mütevazı gelebilir, ancak olgun benchmark’larda küçük iyileşmeler bile içeriğin daha hassas anlaşılmasına işaret eder. Uygulamada bu, kullanıcı kısa bir metin sorgusu girdiğinde veya bir görüntü gönderdiğinde sistemin en alakalı çapraz modal eşleşmeleri sonuçların üst sıralarında getirme olasılığının daha yüksek olması demek.
Günlük Kullanıcılar İçin Anlamı
Uzman olmayanlar için ana mesaj, etiketlerin ve eğitim kurallarının daha akıllı ele alınmasının makinelerin resimler ve sözcükler arasındaki bağlantıyı belirgin şekilde iyileştirebilmesidir. Etiketleri izole etiketler yerine birbirine bağlı bir ağ olarak ele alıp görsel ve metinsel bilgilerin ortak bir alanda buluşma şeklini dikkatlice şekillendirerek bu çerçeve, karmaşık, çok konulu sahnelerde çapraz modal aramayı daha güvenilir kılıyor. Zaman içinde bu tür teknikler, anlamak istediğimiz şeyi—sözlerimiz görüntülerle tam örtüşmese bile—daha sezgisel fotoğraf kütüphaneleri, medya platformları ve akıllı asistanlar sağlama potansiyeline sahip olabilir.
Atıf: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Anahtar kelimeler: görüntü-metin getirme, çok modlu arama, graf sinir ağları, anlamsal etiketler, makine öğrenimi