Clear Sky Science · tr
Transkripsiyon faktörü bağlanma bölgelerini öngörmek için DNABERT tabanlı bir derin öğrenme çerçevesi
DNA kontrol anahtarlarını öngörmenin önemi
Vücudunuzdaki her hücre temelde aynı DNA’ya sahiptir, ama sinir hücreleri, karaciğer hücreleri ve bağışıklık hücreleri çok farklı davranır. Bunun bir nedeni, transkripsiyon faktörleri adı verilen özel proteinlerin genleri açıp kapatan moleküler anahtarlar gibi davranmasıdır; bu proteinler kısa DNA dizilerine, yani bağlanma bölgelerine yerleşir. Tüm bu bağlanma noktalarını deneysel olarak genom çapında bulmak yavaş ve maliyetlidir. Bu çalışma, ham DNA harflerini okuyabilen ve transkripsiyon faktörlerinin nerelere bağlandığını daha doğru tahmin edebilen yeni bir yapay zeka modeli olan TFBS-Finder’ı tanıtıyor; bu, gen düzenlenmesi ve hastalık araştırmalarını hızlandırabilir.
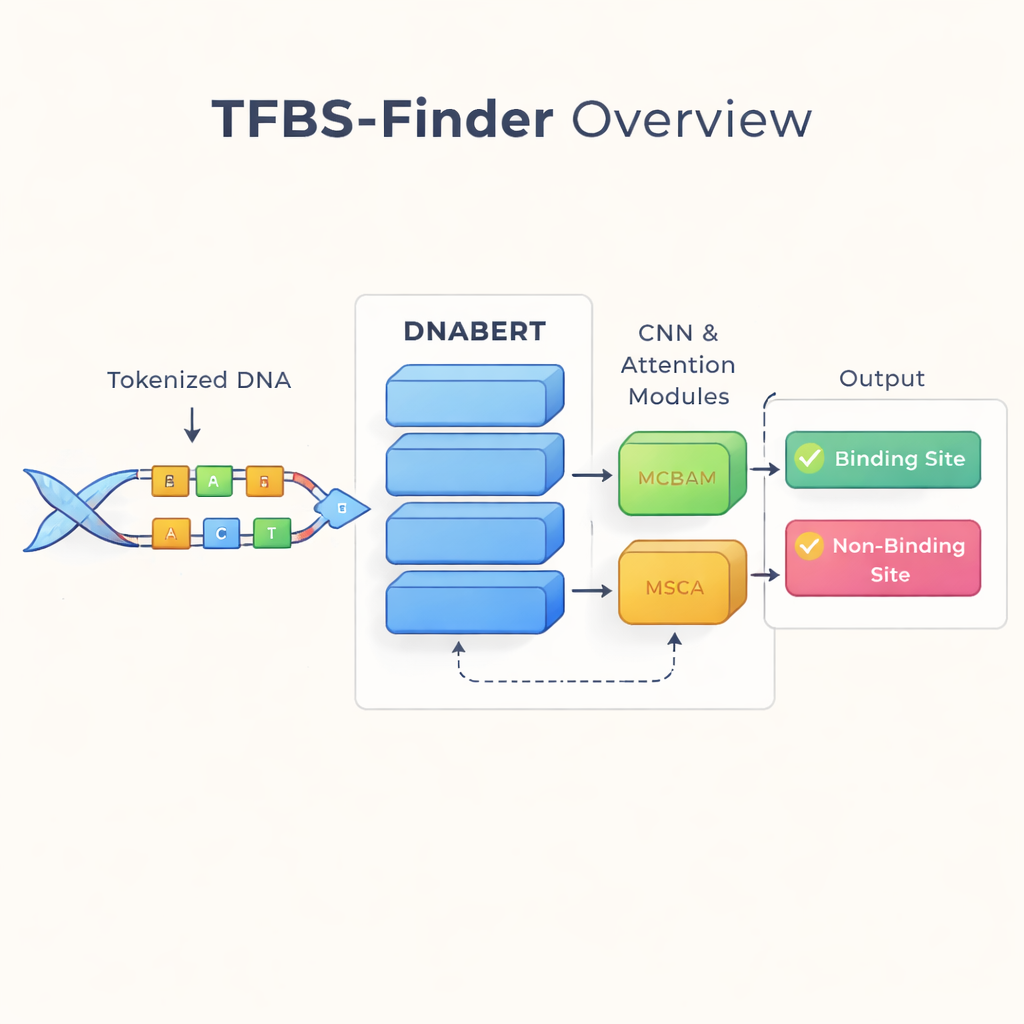
DNA’yı bir dil gibi okumak
Yazarlar, dil teknolojisini dönüştüren bir fikri temel alıyor: DNA’yı metin gibi ele almak. Kelimeler yerine insan DNA’sı üzerinde tekrar eğitilmiş bir BERT modeli olan DNABERT kullanıyorlar. DNABERT tek harflere bakmıyor; DNA’yı üst üste binen beş harfli kısa “kelimelere” böler ve bu parçaların birlikte nasıl ortaya çıktığını öğrenir. Bu, modelin bir dizinin bir ucundaki desenlerin uzaktaki desenlerle nasıl ilişkili olduğunu yakalaması gibi uzun menzilli bağlamı kavramasını sağlar; tıpkı bir cümlenin anlamını izole kelimelerden ziyade bağlam içinde anlamak gibi.
Odaklanmış dikkatle yerel desenleri bulmak
DNABERT küresel bağlamı kavramada iyidir, ancak transkripsiyon faktörü bağlanması genellikle çok kısa ve hassas motiflere—DNA’daki yerel desenlere—bağlıdır. Bu nedenle TFBS-Finder DNABERT’in üzerine birkaç ek bileşen ekler. Bir konvolüsyonel sinir ağı (CNN) dizi yerleşimlerini tarayarak tekrar eden yerel şekilleri ön plana çıkarır; bu, görüntü yazılımlarının kenarları ve köşeleri tespit etmesine benzer. MCBAM ve MSCA adlı iki dikkat modülü ise ayarlanabilir projektörler gibi davranarak en bilgilendirici özellikleri güçlendirir ve gürültüyü azaltır. Birlikte bu bloklar, bir DNA segmentinin gerçek bir bağlanma bölgesi içerip içermediğini belirlemek için geniş ölçekli bağlamı hassas ayrıntılarla dengeler.
Her parçanın gerçekten faydalı olduğunu kanıtlamak
Bütün bu bileşenlerin gerekli olup olmadığını test etmek için ekip kapsamlı “ablasyon” deneyleri gerçekleştirdi; modülleri sistematik olarak kaldırdı veya yeniden düzenledi ve sistemi 29 transkripsiyon faktörünü kapsayan 32 hücre tipinde 165 kıyas veri seti üzerinde yeniden eğitti. Standart tahmin kalitesi ölçüleri kullanıldığında, tam TFBS-Finder modeli tutarlı şekilde en iyi performansı gösterdi. Sadece DNABERT’e dayanan veya dikkat modüllerinden birini çıkartan daha basit versiyonlar belirgin şekilde doğruluk kaybetti. İstatistiksel testler bu performans düşüşlerinin şansa bağlı olmadığını doğruladı; bu, küresel dizi anlayışı ile yerel desenlere özenle tasarlanmış dikkatin birleşiminin kritik olduğunu gösteriyor.
Hücre tipleri arasında çalışmak ve eski araçları geride bırakmak
Önemli bir soru, bir biyolojik bağlamda eğitilmiş bir modelin başka bir bağlama genelleme yapıp yapamayacağıdır. Yazarlar iyi incelenmiş bir transkripsiyon faktörü olan CTCF’ye odaklandı ve TFBS-Finder’ı bir hücre hattından elde edilen verilerle eğitip diğerlerinde test etti. Tüm kombinasyonlarda model yüksek puanlara ulaştı; bu, modelin dokular arasında paylaşılan CTCF bağlanmasının temel özelliklerini yakaladığını gösteriyor. Dokuz önde gelen yöntemle, önceki derin öğrenme ve BERT tabanlı modeller de dahil, karşılaştırıldığında TFBS-Finder daha yüksek ortalama doğruluk gösterdi ve bağlanma bölgelerinin daha güvenilir sıralamalarını üretti. Ayrıca en benzer önceki modele göre biraz daha hızlı çalıştı ve daha az bellek kullandı; bu da daha iyi performansın daha ağır hesaplama gerektirmediğini gösteriyor.
Modelin ne öğrendiğini görmek
Karmaşık yapay zeka sistemleri genellikle “kara kutu” olmakla eleştirilir. Burada araştırmacılar, TFBS-Finder’ın kararlarını en çok hangi DNA pozisyonlarının etkilediğini görselleştirerek o kutuyu açmaya çalıştı. İyi bilinen bağlanma motiflerine sahip iki transkripsiyon faktörü, CEBPB ve GATA3 için diziler boyunca önem puanları ürettiler ve en güçlü sinyalleri konsensus desenlere kümelediler. Bu geri kazanılmış motifler, yerleşik veri tabanlarındaki referans motiflerle yakından eşleşti ve tahmin edilen bağlanma bölgeleri bağımsız olarak tespit edilmiş motif örnekleriyle örtüştü. Bu, TFBS-Finder’ın yalnızca örnekleri ezberlemediğini, transkripsiyon faktörlerinin DNA’yı nasıl tanıdığına dair biyolojik olarak anlamlı kuralları öğrendiğini gösteriyor.
Genetik ve tıp için bunun anlamı
TFBS-Finder, DNA’mızda gömülü kontrol anahtarlarını haritalamak için daha doğru ve yorumlanabilir bir yol sunuyor. Transkripsiyon faktörlerinin nerelere bağlanma olasılığı olduğunu belirleyerek, araştırmacıların gen düzenleme ağlarını çıkarmalarına, hangi genetik varyantların önemli kontrol bölgelerini bozabileceğini önceliklendirmelerine ve daha hedeflenmiş deneyler tasarlamalarına yardımcı olabilir. Mevcut çalışma karıştırılmış dizileri yapay negatifler olarak kullanıyor ve yalnızca DNA harflerine odaklanıyor olsa da, yazarlar DNA şekli hakkında yapısal bilgi eklemeyi ve daha gerçekçi arka plan dizilerini araştırmayı planlıyor. Bu modeller geliştikçe, kodlamayan DNA’daki değişikliklerin gelişim, evrim ve hastalık riskine nasıl katkıda bulunduğunu anlamada güçlü yardımcılar haline gelebilirler.
Atıf: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Anahtar kelimeler: transkripsiyon faktörü bağlanma bölgeleri, derin öğrenme, DNABERT, gen ekspresyonu, genomik