Clear Sky Science · tr
Büyük dil modellerinde klinik token optimizasyonu yoluyla tıbbi bilgi temsiliyetinin geliştirilmesi
Daha akıllı tıbbi okumanın önemi
Her tıbbi yapay zeka asistanının arkasında basit ama kritik bir beceri yatar: metni modelin anlayabileceği parçalara nasıl böldüğü. Bu “doğrama” yanlış gittiğinde —özellikle karmaşık Çince tıbbi terimler için— yapay zeka doktor notlarındaki veya hasta sorularındaki ana fikirleri kaçırabilir. Bu çalışma, o ilk adımda yapılan küçük ama hedefe yönelik bir değişikliğin, baştan yeni bir sistem kurmaya gerek kalmadan büyük dil modellerinin Çince tıbbi veriyi okuma, akıl yürütme ve soruları yanıtlama yeteneğini nasıl geliştirebileceğini gösteriyor.
Metni doğru şekilde parçalara ayırmak
Modern dil modelleri karakterleri veya kelimeleri doğrudan okumaz; önce metni token adı verilen kısa birimlere çevirir. İngilizce için bu yöntem genelde iyi çalışır çünkü boşluklar kelime sınırlarını işaretler. Çince daha zordur: boşluk yoktur ve birçok tıbbi ifade uzun, uzmanlaşmış sözcük öbekleridir. Çoğunlukla İngilizce için tasarlanmış standart tokenleştiriciler bu ifadeleri birçok rastgele parçaya böler. Bir model bir hastalık adını veya laboratuvar testini birkaç ayrık parçaya bölünmüş halde gördüğünde, o terimin gerçek anlamını öğrenmesi zorlaşır ve tıbbi sorulara verdiği yanıtlar belirsiz veya hatalı olabilir.
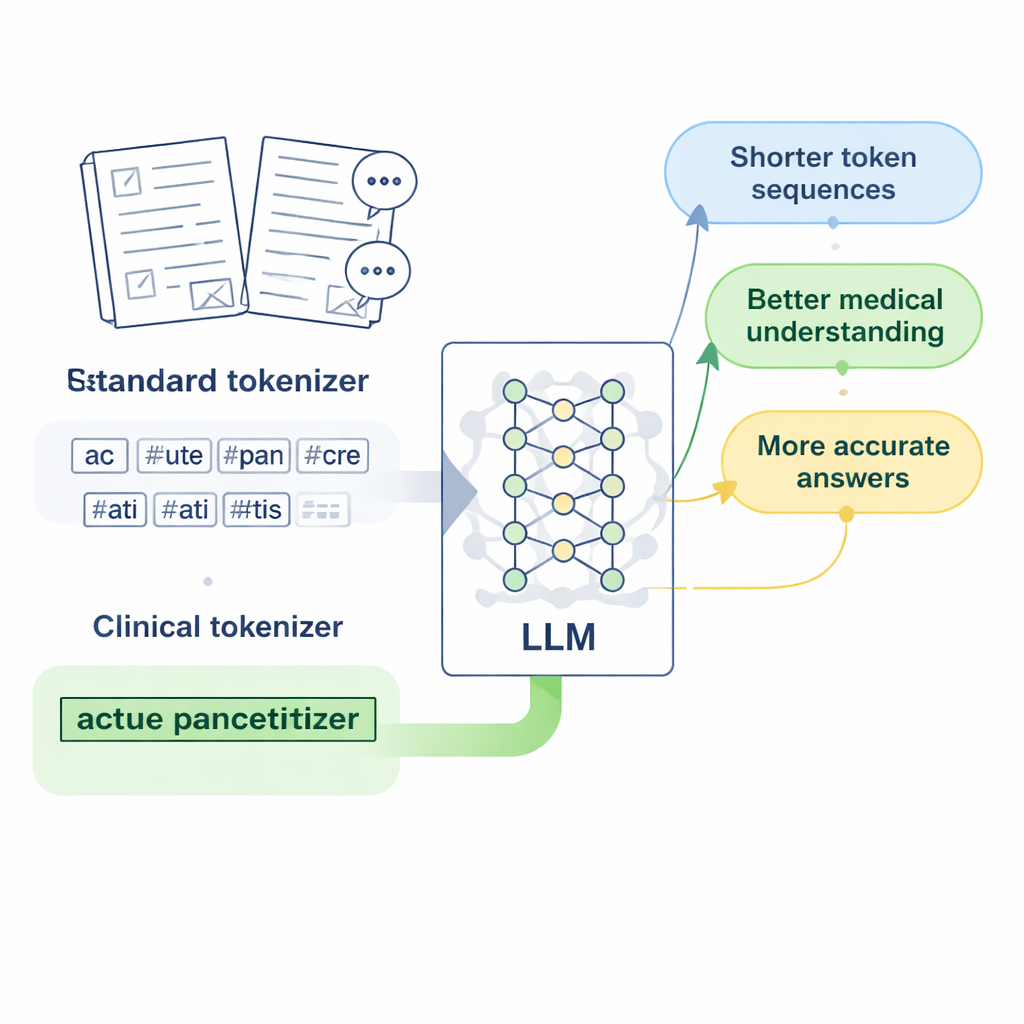
Çin tıbbı için “klinik token”lar tasarlamak
Araştırmacılar popüler açık kaynak LLaMA2 modeli üzerine odaklanıyor ve soruyorlar: tokenizer’a daha zengin bir tıbbi kelime dağarcığı öğretseydik ne olurdu? Onlar, dikkatle düzenlenmiş geleneksel Çin tıbbı veritabanları, binlerce klinik kayıt ve doktor–hasta soru-cevap çiftleri dahil olmak üzere büyük Çince tıbbi metin koleksiyonları topluyor. SentencePiece aracıyla uygulanmış byte-level Byte Pair Encoding (BPE) sürümünü kullanarak, yaygın tıbbi ifadeleri tek birim olarak tutmayı öğrenen yeni bir tokenizer eğitiyorlar. Yazarların “klinik token” dediği bu yeni birimler, modelin zaten bildiklerini atmadan Çince tıbbi dili daha iyi kapsayacak şekilde LLaMA2’nin orijinal kelime dağarcığına ekleniyor.
Daha iyi token’lardan daha iyi bir tıbbi modele
Yeni token eklemek yalnızca ilk adımdır; modelin bunlar için iyi temsiller öğrenmesi gerekir. Ekip, genişletilmiş kelime dağarcığı için vektörleri depolayabilmesi amacıyla LLaMA2’nin iç gömme (embedding) katmanını ayarlıyor ve bu yeni vektörleri başlatmak için iki yöntemi test ediyor. Bir yöntem her kelimenin eski alt parça vektörlerinin ortalamasını alırken, diğeri dikkatle ölçeklenmiş rastgele değerler kullanıyor. Tersine beklenebileceği gibi, rastgele yöntem daha iyi performans gösteriyor; muhtemelen bu, modeli her terim hakkında kötü bir ilk tahmine kilitlemekten kaçınıyor. Yazarlar daha sonra modeli tıbbi metin üzerinde eğitmeye devam ediyor ve LoRA adı verilen kaynak verimli bir yöntemle talimat tarzı tıbbi Soru–Cevap üzerinde ince ayar yaparak Medical-LLaMA adını verdikleri uzmanlaşmış bir sürüm üretiyorlar.
Hız, bağlam ve doğrulukta kazanımları ölçmek
Genişletilmiş kelime dağarcığı ile artık her bir Çince karakter öncekiye göre yaklaşık yarı kadar token gerektiriyor; bu da modelin sabit token penceresinde daha uzun pasajları işleyebileceği anlamına geliyor. Pratikte etkili Çince bağlam uzunluğu yaklaşık iki katına çıkıyor ve büyük bir tıbbi Soru–Cevap setinde ince ayar süresi neredeyse yarıya iniyor. Yanıt kalitesini değerlendirmek için yazarlar iki stratejiyi birleştiriyor: üretilen bir yanıtın bir referansa ne kadar anlamsal olarak yakın olduğunu ölçen BERTScore ve alaka, doğruluk, tamamlayıcılık ve akıcılığı puanlayan sofistike bir derecelendirme modeli (DeepSeek-R1). Bu ölçütlerin tümünde Medical-LLaMA, orijinal LLaMA2’yi ve tıbbi-özgü token’ları içermeyen Çince optimize edilmiş bir varyantı tutarlı şekilde geride bırakıyor. Ayrıca tıbbi varlık tanıma ve klinik metin sınıflandırma gibi ilgili görevlerde küçük ama sürekli iyileşmeler gösteriyor; tüm bunlar genel, tıbbi olmayan sorularda performansı korurken gerçekleşiyor.
Geleceğin tıbbi yapay zekası için anlamı
Uzman olmayanlar için ana mesaj, yapay zekaya yönelik daha akıllı “okuma gözlüklerinin” —burada tıbbi dili daha iyi parçalara ayırma biçimi— sağlık sorularını anlama ve yanıtlama yeteneğini belirgin şekilde iyileştirebileceğidir. Mevcut bir modelin kelime dağarcığına iyi seçilmiş klinik token’lar ekleyerek yazarlar verimlilik ve doğruluğu, büyük yeni eğitim koşuları veya tamamen yeni mimariler gerektirmeden artırıyor. Çalışma 7 milyar parametreli bir model ve Çince tıbbi metinle sınırlı olsa da, erken dil işleme katmanını alana göre uyarlayıp sonra hafifçe yeniden eğitme şeklinde pratik bir reçete sunuyor. Bu strateji, standart modellerin okumakta zorlandığı diller ve uzmanlık alanlarında geleceğin tıbbi yapay zeka araçlarının klinisyenler ve hastalar için daha güvenilir ortaklar haline gelmesine yardımcı olabilir.
Atıf: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Anahtar kelimeler: tıbbi dil modelleri, Çince klinik metin, tokenizasyon, klinik kelime dağarcığı, tıbbi soru-cevap