Clear Sky Science · tr
K‑katmanlı çapraz doğrulamada K seçiminin denetimli öğrenme modellerinde önyargı ve varyans üzerindeki etkisi
Modelinizi iki kez kontrol etmenin neden gerçekten önemli olduğu
Tıbbi teşhisten kredi puanlamaya kadar birçok karar artık geçmiş verilerle eğitilmiş makine öğrenmesi modellerine dayanıyor. Peki ekranda iyi görünen bir modelin yeni, görülmemiş örneklerde de iyi davranacağını nasıl anlarız? Modelleri “test etmenin” popüler bir yolu k‑katmanlı çapraz doğrulamadır; burada veriler defalarca eğitim ve test parçalarına bölünür. Bu çalışma aldatıcı derecede basit ama hayati bir soruyu soruyor: kaç parçaya bölmeliyiz—k ne kadar büyük olmalı—ve bu seçim modelin bildirilen performansının güvenilirliğini nasıl sessizce şekillendirir?
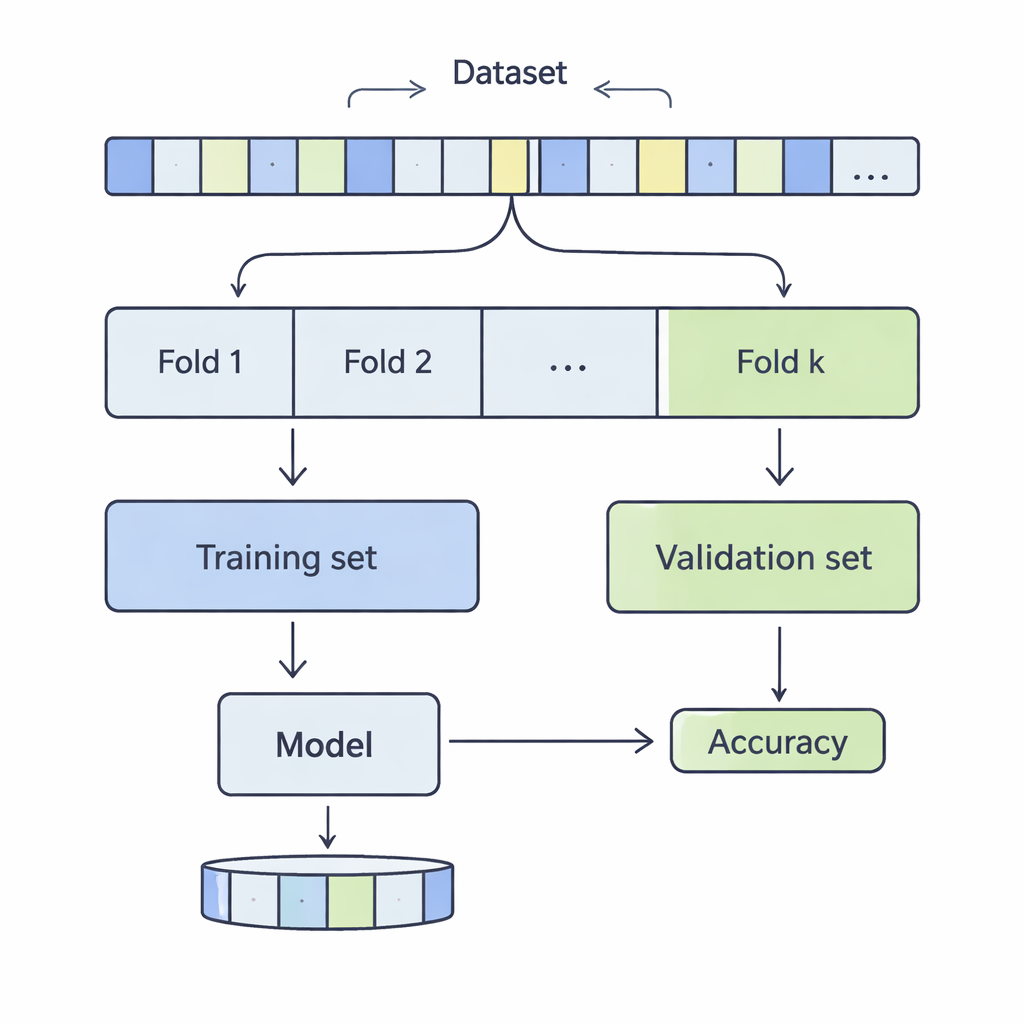
Gerçeklik kontrolü için veriler nasıl dilimlenir
K‑katmanlı çapraz doğrulamada veri kümesi karıştırılır ve k eşit parçaya, yani katmana bölünür. Model bu katmanların k‑1’inde eğitilir ve kalan bir katmanda değerlendirilir; her katman test kısmı olana kadar bu süreç tekrarlanır. Yazarlar 3 ile 20 arasındaki k değerlerini, birkaç binden yarım milyondan fazla kayda kadar değişen 12 gerçek dünya veri kümesinde inceledi; bunlar gelir tahmini, tıbbi sonuçlar, siber saldırılar, oyunlar ve şarap kalitesi gibi alanları kapsıyordu. Dört yaygın sınıflandırma yöntemini—Destek Vektör Makineleri, Karar Ağaçları, Lojistik Regresyon ve k‑En Yakın Komşu—uyguladılar ve k seçimlerinin performansın iki temel yönü olan önyargı ve varyansı nasıl etkilediğini titizlikle ölçtüler.
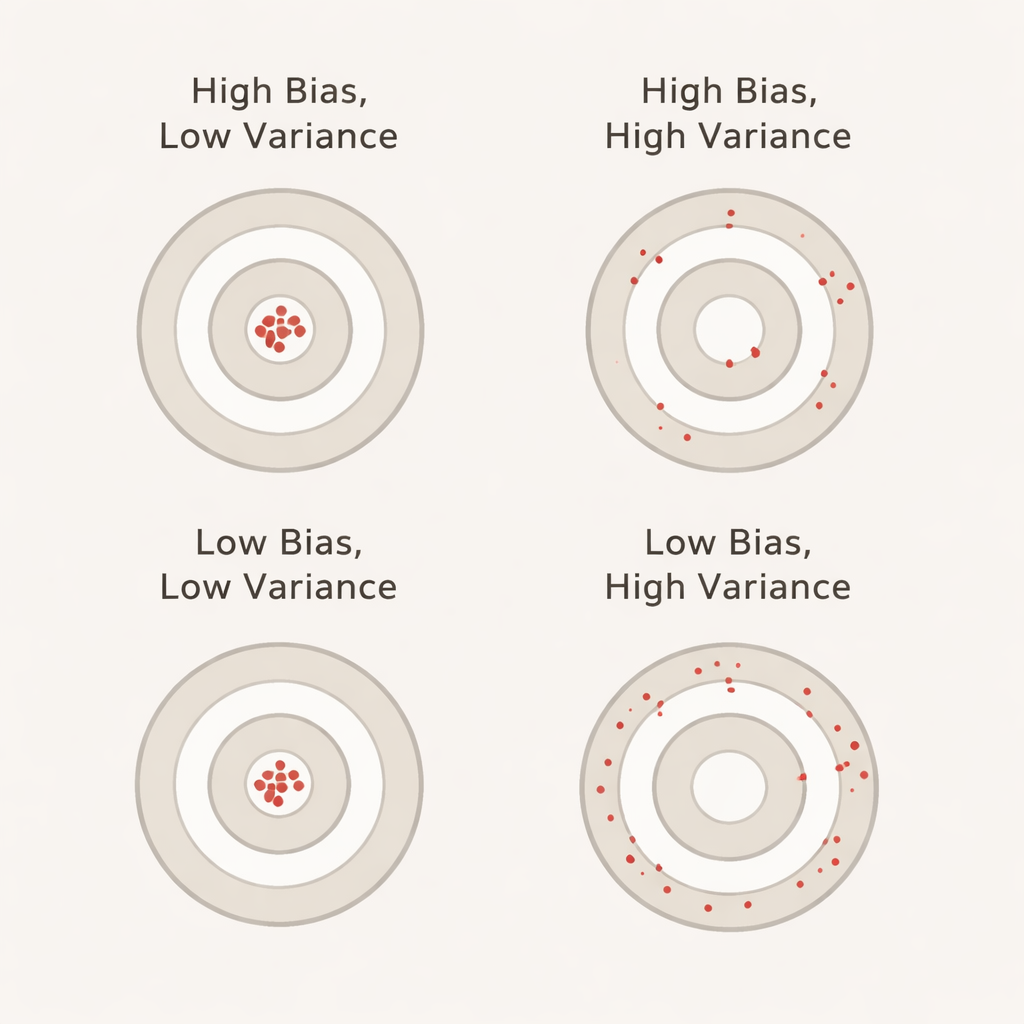
Günlük terimlerle önyargı ve varyans ne demektir
Bu bağlamda önyargı, modelin çapraz doğrulama sırasında gerçekte ayrı ve hiç dokunulmamış bir test setinde olduğundan ne kadar daha iyi görünme eğiliminde olduğunu yakalar. Büyük pozitif bir önyargı, doğrulama sırasında modelin aşırı iyimser göründüğü anlamına gelir—pratik sınavlarda başarılı olan ama gerçek sınavda tökezleyen bir öğrenciye benzer. Varyans ise modelin performansının katmandan katmana ne kadar oynadığını yansıtır: düşük varyans skorların farklı veri dilimlerinde istikrarlı olduğunu, yüksek varyans ise skorların yukarı-aşağı dalgalandığını gösterir. İdeal olan, bildirilen doğruluğun hem gerçekçi hem de istikrarlı olması için hem önyargının hem de varyansın düşük olmasıdır.
Katman sayısını artırdığımızda ne oluyor
Tüm on iki veri kümesi ve dört algoritma genelinde güçlü biçimde öne çıkan bir desen vardı: k arttıkça varyans neredeyse her zaman yükseldi. Başka bir deyişle, daha fazla katman kullanmak bildirilen doğruluğun bir katmandan diğerine daha az istikrarlı olmasına yol açtı. Bu, daha fazla katmanın otomatik olarak daha iyi, daha güvenilir tahminler sağladığına dair yaygın inanışa ters düşer. Nedeni, k büyük olduğunda her doğrulama diliminin çok küçük ve daha az temsil edici hale gelmesi, dolayısıyla sonuçların verideki tuhaflıklara daha duyarlı olmasıdır. Aynı zamanda önyargı daha uniform bir davranış göstermedi. k‑En Yakın Komşu ve Destek Vektör Makineleri için k büyüdükçe önyargı yükselme eğilimi gösterdi; bu da bu modellerin çapraz doğrulamada genellikle beklenenden daha doğru görünme eğiliminde olduğu anlamına geliyor. Karar Ağaçları yaklaşık olarak dengeli desenler sergiledi ve Lojistik Regresyon ara bir yerde konumlandı; daha karışık ama daha ılımlı önyargı değişimleri gözlendi.
“Standart ayarlar” neden yanıltıcı olabilir
Çoğu pratik kılavuz, veri kümesi veya öğrenme algoritmasından bağımsız olarak genellikle beş ya da on katman kullanılmasını önerir. Yazarların analizi, bu tür tek‑beden‑herkese uyar tavsiyelerin yanıltıcı olabileceğini gösteriyor. Bazı veri kümelerinde ve bazı modeller için daha yüksek k değerleri, performans hakkında aşırı iyimser izlenimleri artırdı; hepsinde ise daha fazla katman tahminlerde daha fazla değişkenlik getirdi. Bu, sağlık hizmetleri, finans veya altyapı gibi yüksek riskli alanlarda özellikle endişe vericidir; bir modelin doğruluğu konusunda yanlış güven, gerçek dünyada sonuçlar doğurabilir. Çalışma, k etkilerinin hem verinin doğasına (küçük vs. büyük, gürültülü vs. daha temiz) hem de belirli algoritmanın tekrar eden, neredeyse aynı eğitim setlerinden nasıl öğrendiğine bağlı olduğunu savunuyor.
Makine öğrenmesi kullanan herkes için alınacak ders
Ana ders, çapraz doğrulamada katman sayısının zararsız bir teknik ayrıntı olmadığı—doğruluk rakamlarınızın güvenilirliğini doğrudan şekillendirdiğidir. Bu deneylerde daha fazla katman tutarlı biçimde sonuçları daha sarsak hale getirdi ve sık sık bazı modellerin gerçekte olduklarından daha iyi görünmesine neden oldu. Körü körüne k=5 veya k=10 seçmek yerine yazarlar k’yı bir ayar düğmesi olarak ele almayı öneriyor: sonuçların küçük bir k aralığında nasıl değiştiğini kontrol edin ve mümkünse birden fazla performans ölçütüne bakın. Uygulayıcılar ve ilgili okuyucular için mesaj net: makine öğrenmesi modellerini değerlendirirken verileri nasıl dilimlediğiniz, modelin kendisi kadar önemli olabilir.
Atıf: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Anahtar kelimeler: k-katmanlı çapraz doğrulama, önyargı-varyans dengesi, model değerlendirmesi, makine öğrenmesi doğrulama, denetimli sınıflandırma