Clear Sky Science · tr
Marie Sklodowska-Curie eylemleri için doğal dil işleme tabanlı uzman atama sistemi
Doğru uzmanı seçmenin neden gerçekten önemli olduğu
Sınırlı fon için binlerce araştırma önerisi yarışırken her şey bunları kimin değerlendirdiğine bağlıdır. Atanan uzmanlar bir önerinin konusunu gerçekten anlamazlarsa, umut vaat eden fikirler yanlış yorumlanabilir veya gözden kaçabilir. Bu makale, yapay zekânın—özellikle güncel dil işleme sistemlerinin—önerileri bugün kullanılan anahtar kelime tabanlı araçlardan daha doğru ve adil şekilde en uygun uzmanlarla eşleştirmeye nasıl yardımcı olabileceğini inceliyor.
Anahtar kelime kontrol listelerinin sorunu
Bugüne kadar Marie Skłodowska-Curie doktora sonrası bursları gibi büyük Avrupa finansman programlarında uzman ataması büyük ölçüde anahtar kelimelere dayanıyordu. Mevcut platform, öneri açıklamalarını ve hakem profillerini tarayıp eşleşen terimleri buluyor, ardından üç uzman ve alternatifler öneriyor. Ancak süreci denetleyen kıdemli bilim insanları olan Başkan Yardımcıları bu atamaların yaklaşık %40’ını değiştiriyor. Bu düzeyde insan müdahalesi sistemi emek yoğun, yavaş ve biraz kapalı hale getiriyor; hem de yılda çoğu zaman yeni ortaya çıkan alanlarda sabit anahtar kelime listelerinin zayıf kaldığı şekilde yaklaşık 10.000 öneri gelmesi durumunda.
Araştırmayı insan gibi, ölçeklenebilir şekilde okumak
Yazarlar, araştırmayı bir insan uzmanın yaptığı gibi “okumaya” çalışan yeni bir atama sistemi geliştirdiler. Etiketlere güvenmek yerine her uzmanın yayınlarını küresel araştırmacı kimliği sistemi ORCID aracılığıyla topluyor ve 2.800’den fazla makale özetinden oluşan bir veritabanı oluşturuyorlar. Öneri özetleri ve yayın özetleri, bilimsel metinler üzerinde özel olarak eğitilmiş büyük bir dil modeli olan GALACTICA ile işleniyor. GALACTICA her özeti yalnızca sözcükleri değil anlamını da yakalayan sayısal bir parmak izi haline getiriyor. Bu parmak izlerini karşılaştırarak sistem, bir önerinin içeriğinin her bir uzmanın geçmiş çalışmalarıyla ne kadar örtüştüğünü tahmin edebiliyor.
Uzmanlığı toplamanın üç yolu
Bir zorluk, uzmanların onlarca yayına sahip olabilmesi. Sistem her uzman ve öneri için tek bir skora ihtiyaç duyuyor; bu nedenle yazarlar benzerlikleri birleştirmenin üç basit yolunu test ettiler. Toplam (Sum) stratejisi tüm benzerlik puanlarını toplayarak geniş ve tekrar eden uygunluğu ödüllendiriyor. Çarpım (Product) stratejisi puanları çarparak birçok yayında tutarlı benzerliği vurguluyor, ancak zayıf bir eşleşmeyi ağır biçimde cezalandırıyor. Maksimum (Maximum) stratejisi yalnızca tek en güçlü eşleşmeyi koruyor; bunun, bir atamayı haklı çıkarmak için bir çok yakından ilişkili makalenin yeterli olabileceği varsayımına dayanıyor. Bu skorlar ardından her bir 181 öneri için 48 aday uzmanı sıralamakta kullanılıyor ve sıralamalar Başkan Yardımcılarının nihai uzman seçimleriyle karşılaştırılıyor.
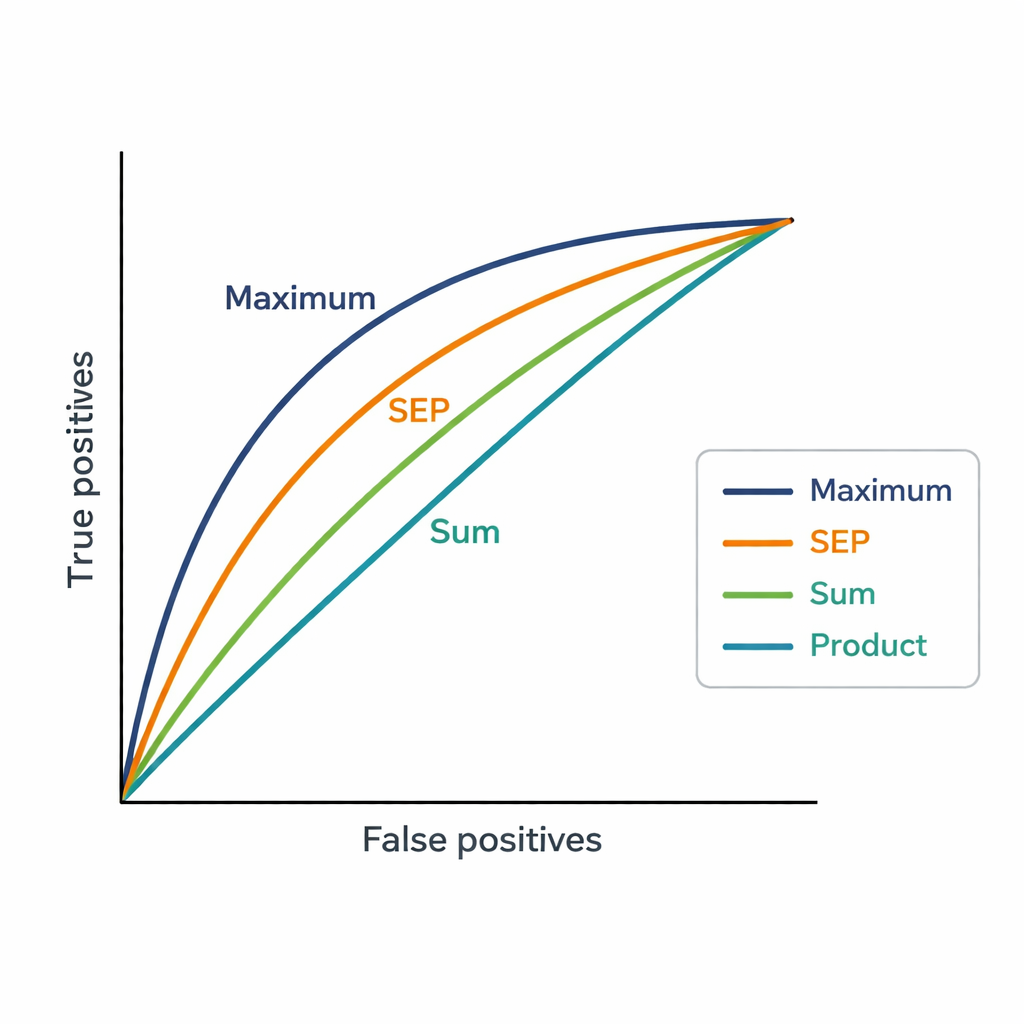
Rakamlar insan tercihleri hakkında ne gösteriyor
Maksimum strateji, Başkan Yardımcılarının kararlarıyla en yüksek uyumu gösterdi ve 0,82 AUC elde etti; bu, mevcut anahtar kelime tabanlı sistemin (AUC 0,75) ve diğer birleştirme yöntemlerinin üzerinde. Uygulamada Başkan Yardımcılarının seçtiği uzman genellikle Maksimum stratejisinin ürettiği ilk dört öneri arasında yer alıyordu. Bu, hakem atarken insanların bir uzmanın önceki çalışmaları ile bir öneri arasında en az bir çok güçlü bağlantının bulunup bulunmadığına odaklanma eğiliminde olduğunu; tüm yayınların uyum göstermesini şart koşmadıklarını gösteriyor. Yeni yöntem ayrıca platformun kaba “uyum” düzeylerinden çok daha ince ayrımlı skorlar üreterek yakın sıralanan uzmanlar arasında net ayrımlar yapılmasını sağlıyor.
Gelecekteki hibe değerlendirmeleri için anlamı
Bir okuyucu için çıkarım açık: bilimsel dili anlayan yapay zekâ kullanarak fon veren kuruluşlar önerileri doğru uzmanlarla daha iyi eşleştirebilir, insan düzeltmelerini azaltabilir ve süreci daha tutarlı ve şeffaf hale getirebilir. Yayınlardan elde edilen kanıtları birleştirmenin farklı yolları uzmanlığın farklı yönlerini vurgulasa da, basit “en iyi tek eşleşme” kuralı insanların aslında nasıl karar verdiğini yansıtıyor gibi görünüyor. Bu tür sistemler daha geniş çapta ve yeni dil modelleriyle test edildikçe, dünya çapında daha adil ve verimli araştırma değerlendirmelerinin önemli bir parçası olabilirler.
Atıf: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Anahtar kelimeler: hakem değerlendirmesi, uzman eşleştirme, araştırma finansmanı, doğal dil işleme, büyük dil modelleri