Clear Sky Science · tr
Uyarlanabilir bulanık küme yönlendirmeli basit, hızlı ve verimli özellik seçimi yüksek boyutlu ve yüksek dengesiz ikili sınıf biyoinformatik mikroarray verileri için
Gen araştırmaları için bunun önemi
Günümüzün gen ekspresyonu testleri tek bir hasta örneğinde on binlerce geni ölçebilir. Bu veri seli kanserin daha erken teşhisi ve daha iyi tedavi seçimleri için umut vaat ediyor, ancak aynı zamanda bir sorun yaratıyor: bu genlerin çoğu gürültülü, birbirinin yinelemeleri ya da nadir ve tehlikeli vakalarla değil, daha yaygın vakalarla ilişkilendiriliyor. Bu makale, bilgisayarların yalnızca çok küçük, özenle seçilmiş bir gen seti kullanarak küçük ve tespit edilmesi zor hasta alt gruplarını güvenilir şekilde saptamasını sağlayacak biçimde büyük gen-ekspresyon veri kümelerini elemek için yeni bir yol sunuyor.
Çok fazla ve birbirine çok benzeyen genlerin zorluğu
Mikroarray deneyleri genellikle yalnızca birkaç yüz hasta için binlerce gen aktivite düzeyini izler. Genellikle bir sınıf (örneğin yaygın bir kanser alt tipi) diğerini büyük ölçüde sayısal olarak aşar ve bu da yüksek dengesizliğe sahip veriler yaratır. Bu durumda birçok gen çok benzer davranışlar sergiler ve çoğunluk ile azınlık hastaların desenleri örtüşebilir. Standart öğrenme yöntemleri çoğunluk sınıfına takılmaya ve yineleyici genlerden dolayı kafa karışıklığına meyillidir; bu da fazla öğrenmeye ve nadir alt tiplerin kötü tespitine yol açar. Geleneksel boyut indirgeme yöntemleri ya yeni karışık özellikler üreterek yorumlanabilirliği feda eder ya da bir sınıflandırıcının azınlık vakalarını tanımada ne kadar yardımcı olduklarına yakından bakmadan genleri seçer.
Daha akıllı gen seçimi için yeni bir yol haritası
Yazarlar, özellikle yüksek boyutlu, dengesiz gen-ekspresyon verileri için tasarlanmış uyarlanabilir bir özellik seçimi modeli olan AFCG‑SFE’yi tanıtıyor. Yöntem, genleri açıp kapatan ve bunların sınıflandırmayı ne kadar desteklediğini test eden basit bir “tek ajan” aramadan başlar, ancak bunu birkaç veri kaynaklı adımla zenginleştirir. Önce, genleri benzer davranışlarına göre gruplar, sonra bir genin birden çok yolda yer alabileceği biyolojik gerçeği yansıtmak için genlerin birden fazla gruba ait olmasına izin verir. Her grup içinde, genleri hastalık etiketi hakkında ne kadar bilgi taşıdıklarına göre sıralar ve yalnızca birkaç kilit temsilciyi tutar; bu, ana arama başlamadan önce yinelemeyi keskin biçimde azaltır. 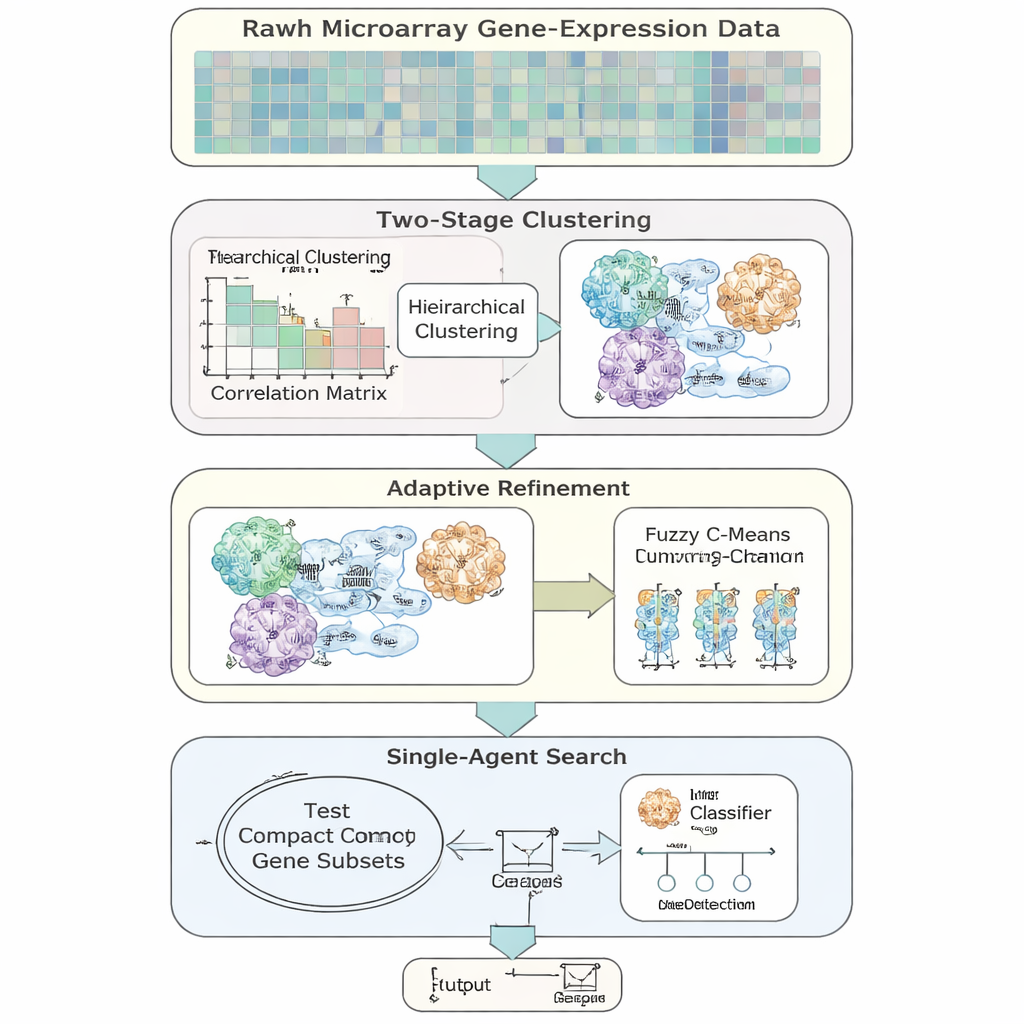
Bilgisayarın nadir hastalara önem vermesini sağlamak
Basit doğruluğa odaklanmak yerine AFCG‑SFE, dengesiz veriler için uygun metrikleri vurgulayan; azınlık ve çoğunluk vakalarını doğru tanımlama dengesi ve tüm karar eşiklerinde performans gibi ölçümleri içeren bir uygunluk (fitness) puanı kullanır. Uygunluk fonksiyonu ayrıca çok sayıda gen seçilmesine veya aynı kümeden çok sayıda gen seçilmesine cezalar ve hastalık etiketiyle güçlü bağımlılık gösteren genlere ödül içerir. Önemli olarak, bu ceza ve ödüllerin gücü, el ile ayarlama yerine veri setinin hasta başına düşen gen sayısı veya sınıfların örtüşme düzeyi gibi özelliklerinden otomatik olarak belirlenir. Bu da yöntemi daha sağlam ve çalışmalar arasında daha kolay aktarılabilir kılar.
Problemin zorluğuna uyum sağlama
Ana fikirlerden biri algoritmanın her zaman mümkün olan en küçük gen setini hedeflememesi gerektiğidir. İki sınıfı ayırmak çok zor veya yoğun şekilde örtüşmüş olduğunda, yöntem nadir fakat önemli sinyallerin atılmamasını sağlamak için tutulması gereken gen sayısı için otomatik olarak bir alt sınır yükseltir. Arama ilerledikçe, AFCG‑SFE her gruptan hayatta kalabilecek gen sayısı için küme başına bir üst sınırı kademeli olarak sıkılaştırır, aynı zamanda bu asgari değere saygı gösterir. Sonuç, verinin yapısını yakalayan, tek bir yineleyici desenin hakim olmadığı kompakt ve çeşitli bir gen panelidir. 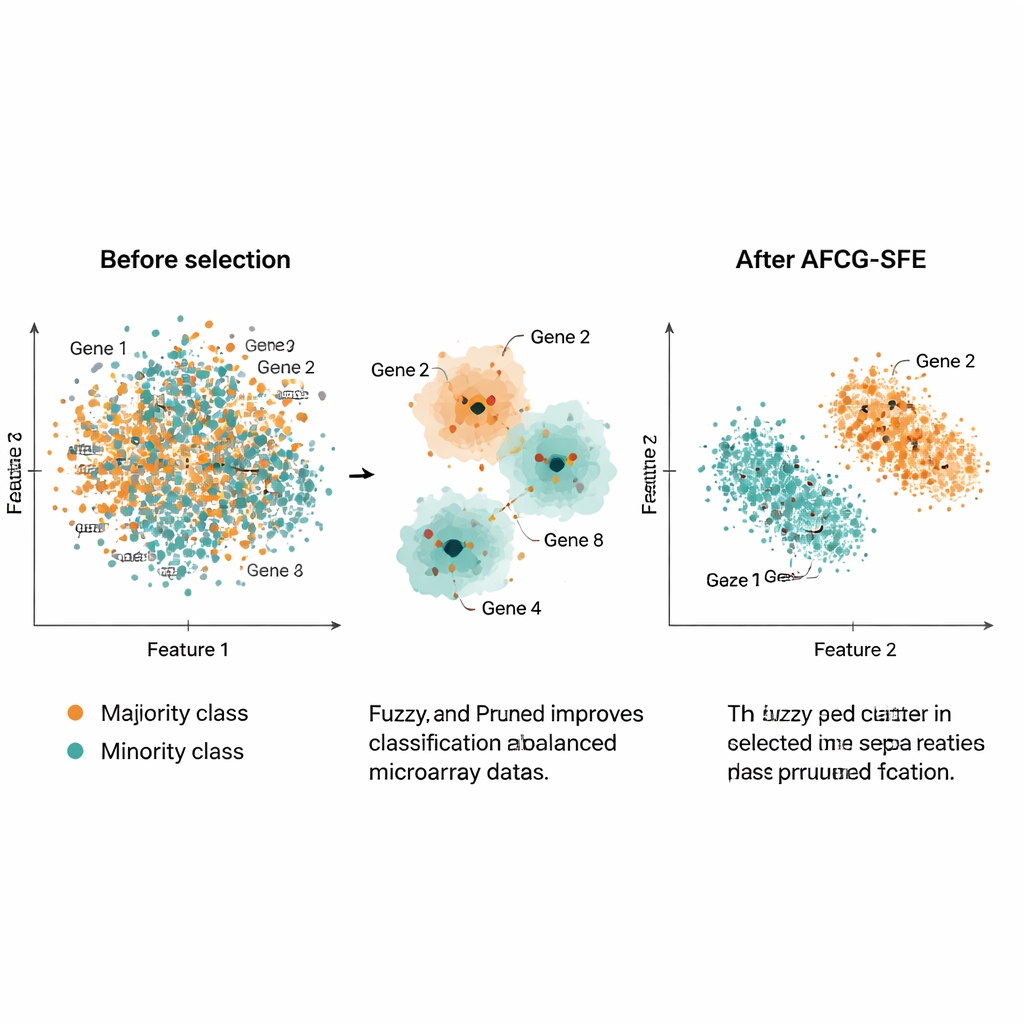
Deneyler ne gösteriyor
Yazarlar AFCG‑SFE’yi her biri binlerce gene fakat sadece yaklaşık 100–200 örneğe ve güçlü sınıf dengesizliğine sahip 20 halka açık kanser mikroarray veri setinde test ettiler. Yöntemlerini birkaç evrimsel arama kıstası, basit filtreler ve sınıflandırıcıya gömülü özellik seçimi yaklaşımları ile karşılaştırdılar. F‑ölçüsü, dengeli doğruluk, ROC eğrisi altındaki alan ve fazla öğrenme ölçütü dahil olmak üzere bir dizi ölçüde AFCG‑SFE tüm veri setlerinde en iyi veya en iyi ile eşit performans gösterdi. Genellikle 25’ten az gen seçti (çoğu zaman 6–8 kadar az), orijinal özelliklerin %99’dan fazlasını elerken sınıflandırma performansını iyileştirdi veya korudu. Ayrıca sınıfların özellik uzayında ne kadar örtüştüğünü yakalayan bir karmaşıklık indeksini azalttı; bu, seçim sonrası daha net bir ayrım olduğunu gösteriyor.
Uzman olmayanlar için sonuç
Pratik olarak bu çalışma, devasa, gürültülü gen‑ekspresyon profillerini bilgisayarların nadir hasta alt gruplarını doğru tanımasına izin veren çok küçük, bilgilendirici gen setlerine indirgeme yolunu sunuyor. Benzer genleri akıllıca gruplayarak, hastalığı gerçekten izleyenleri ödüllendirerek ve çoğunluk sınıfına karşı yanlılığa karşı açıkça korunarak, AFCG‑SFE hem daha iyi tahmin hem de çok daha basit gen panelleri sağlar. Bu birleşim, araştırmacıların potansiyel biyobelirteçlere odaklanmasına, daha yorumlanabilir tanı testleri tasarlamasına ve nihayetinde hassas tıp araçlarının gerçek, kusurlu biyolojik verilerle daha iyi çalışmasına yardımcı olabilir.
Atıf: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
Anahtar kelimeler: gen ekspresyonu, özellik seçimi, dengesiz veri, mikroarray, kanser alt tipleri