Clear Sky Science · tr
Kişiselleştirilmiş spor antrenman planı üretimi için bilgi temelli büyük dil modeli
Günlük İnsanlar İçin Daha Akıllı Antrenman Planları
Çoğu fitness uygulaması kişiselleştirilmiş antrenman vaat eder, ancak birçoğu vücudunuzun gerçek durumunu görmezden gelen genel şablonlara dayanır. Bu makale, modern sohbet robotlarının arkasındaki türde büyük dil modellerini, doğrulanmış spor bilimi bilgisi ve giyilebilir verilerle birleştirerek daha güvenli ve daha etkili antrenman planları oluşturan LLM-SPTRec adlı yeni bir sistemi tanıtıyor. Uygulamanızın neden sürekli yanlış egzersizler önerdiğini merak eden veya yapay zekâ tarafından verilen sağlık tavsiyelerinin gerçekten güvenli olup olmadığından endişe eden herkes için bu çalışma, dijital koçluğu hem daha kişisel hem de daha bilimsel hale getirmenin yollarını gösteriyor.
Neden Geleneksel Fitness Uygulamaları Yetersiz Kalıyor
Film veya ürün öneren geleneksel tavsiye motorları egzersize uygulandığında zorlanır. Genellikle standart şablonları kopyalar ve yeniden kullanır, yeni kullanıcılar için sınırlı veriyi işlemekle zorlanır ve nadiren vücudunuzun günler içinde nasıl değiştiğine bakar. Daha kötüsü, güvenliğin önemli olduğu yüksek riskli kararlar için tasarlanmamışlardır. Genel amaçlı dil modelleri antrenmanlar hakkında konuşmakta iyidir, ancak geniş internet metinleriyle eğitildikleri için riskli tavsiyeler “üretebilir” veya önemli dinlenme günlerini atlayabilirler. Yazarlar, sakatlanma veya aşırı antrenman gibi zararlı sonuçların ortaya çıkabileceği egzersiz planlamasında—yapay zekânın doğrulanmış spor bilimi ile temellenmesi ve bireyin zaman içindeki değişen durumunu takip etmesi gerektiğini savunuyorlar.
Bireyin Ayrıntılı Bir Resmini Oluşturmak
LLM-SPTRec'in merkezinde her kullanıcı için ayrıntılı bir anlık görüntü oluşturan bir modül bulunur. Sadece yaş, cinsiyet veya deneyim düzeyini saklamak yerine sistem üç tür bilgiyi birleştirir: statik özellikler (ör. antrenman geçmişi), dinamik sinyaller (giyilebilir cihazlar ve günlüklerden kalp atış hızı, kalp atış hızı değişkenliği, uyku skoru ve önceki antrenmanlar gibi) ve kullanıcının serbest metin olarak yazdığı hedefler. Modern dil modellerinin arkasındaki teknolojiyle akraba olan bir transformer tabanlı model, bu zaman serisi verilerdeki kalıpları öğrenir; örneğin dün yapılan zorlu bir antrenmanın bugünkü hazır oluşu nasıl etkileyebileceğini. Bir dikkat mekanizması hangi sinyallerin o anda daha önemli olduğunu tartar ve bunları kullanıcının mevcut durumunun tek bir sayısal gösterimine birleştirir.
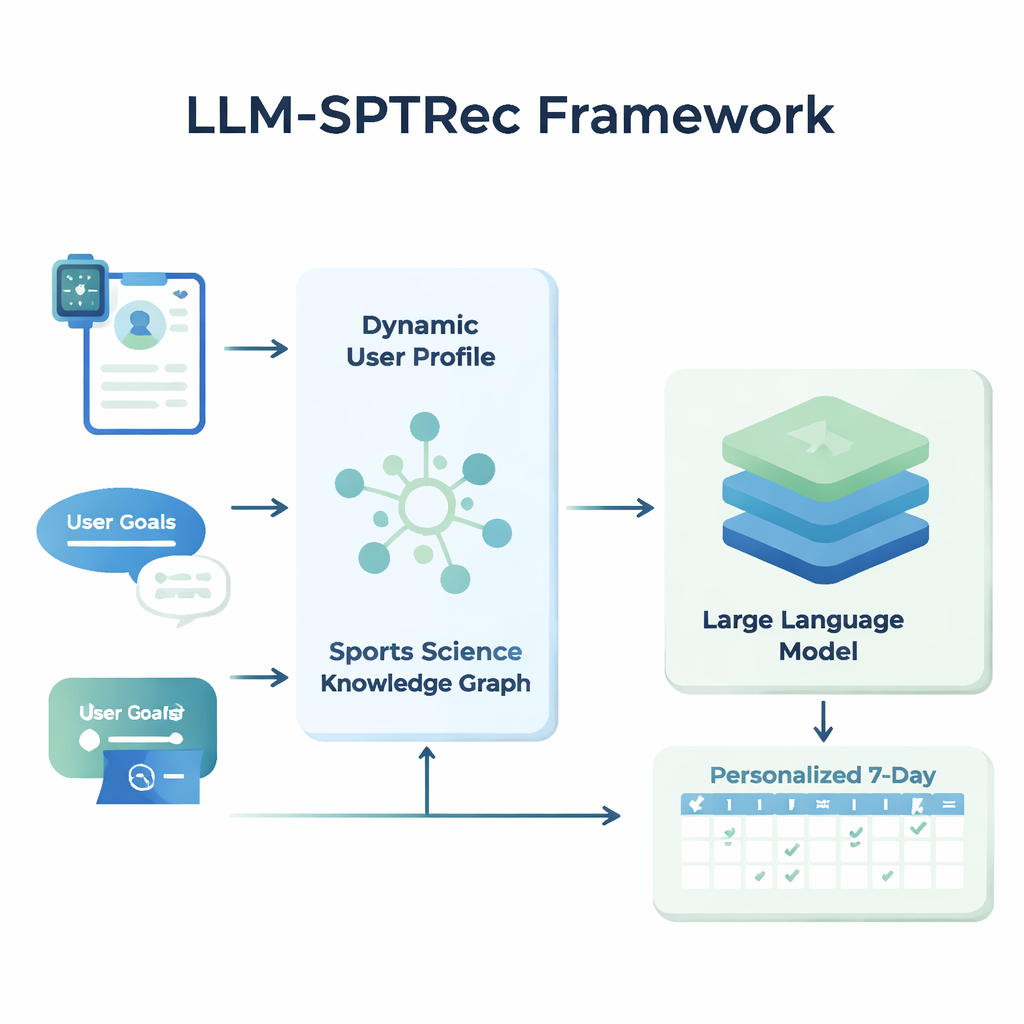
Yapay Zekâyı Gerçek Spor Bilimiyle Eğitmek
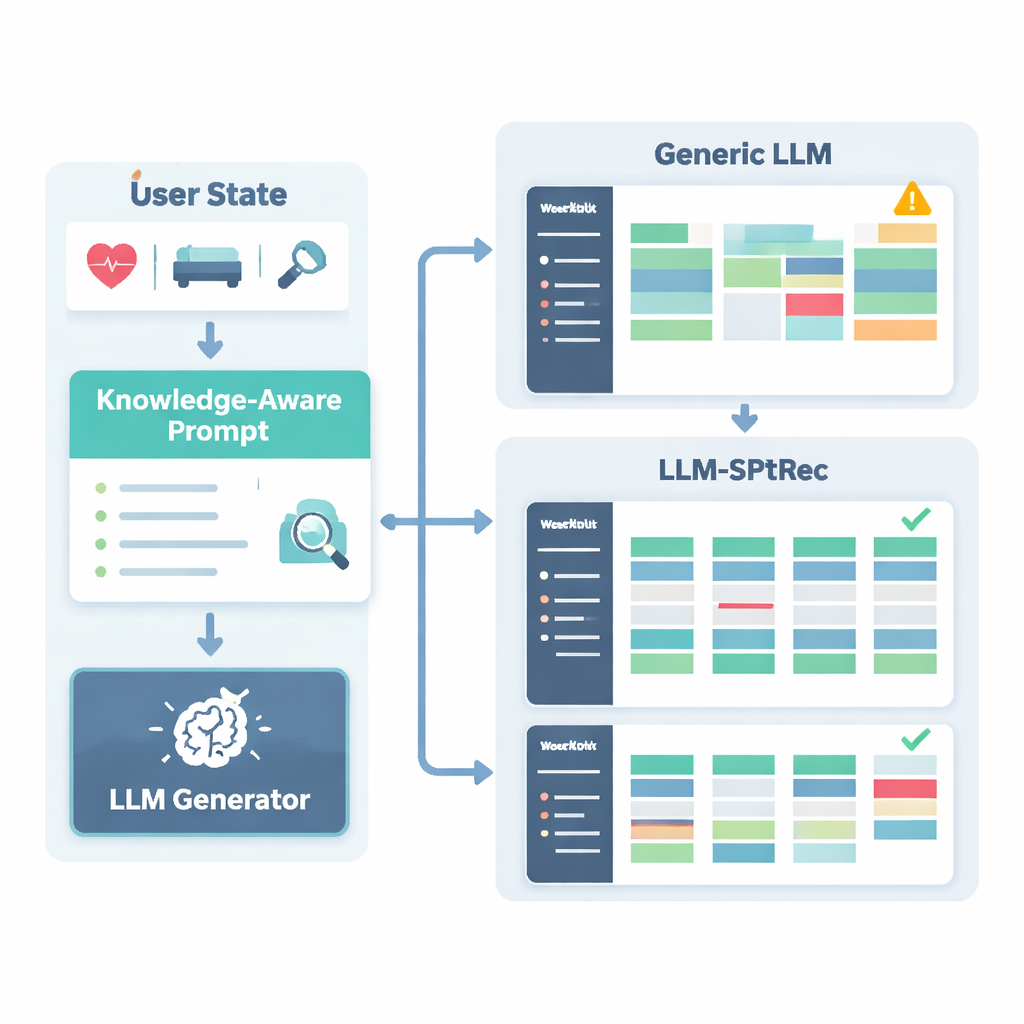
Güvenli olmayan veya bilimsel olmayan önerileri önlemek için araştırmacılar Spor Bilimi Bilgi Grafiği adında, uzman onaylı gerçeklerin yapılandırılmış bir haritasını oluşturdular. Bu grafik, egzersizleri kaslara, hareket türlerine, ekipmana, yaygın yaralanmalara ve progresif yüklenme ile özgüllük gibi antrenman ilkelerine bağlayan binlerce girdiyi içerir. Her kullanıcı için sistem grafiğin en alakalı bölümlerini—örneğin bench press’in hedeflediği kaslar veya omuz sorunları için zararlı olabilecek hareketler gibi—çıkartır ve bunları kullanıcının profiliyle birlikte dil modeline beslenen okunabilir metne dönüştürür. Dil modelinden, dikkatle tasarlanmış bir istem aracılığıyla, kas gruplarını günler arasında döndürmek ve bilinen kontrendikasyonlardan kaçınmak gibi kurallara uyan çok günlük bir antrenman planını yapısal bir formatta üretmesi istenir.
Planları Yapılandırılmış, Güvenli Tutmak ve Zamanla İyileştirmek
LLM-SPTRec sadece metin üretmekle kalmaz. Bir doğrulama modülü her planı aynı primer kas gruplarını art arda aşırı yüklememek gibi katı kurallara karşı kontrol eder ve bilgi grafiğinde saklı yaralanma riskleriyle çelişkileri işaretler. Bir plan bu kontrollerden geçemezse sistem modeli tekrar çağırır ve açıkça neyin yanlış olduğunu belirterek güvenli bir plan üretilene kadar düzeltilmesini sağlar. Sistemin eğitimi de iki aşamalı gerçekleşir. Önce geniş bir uzman tasarımı plan koleksiyonundan öğrenir. Ardından, simüle edilmiş veya gerçek kullanıcı geri bildirimleriyle daha fazla rafine edilir; tutarlı, hedeflerle uyumlu ve uygulanması tatmin edici planları ödüllendirirken güvenli olmayan önerileri ağır şekilde cezalandıran değerlendirmeler kullanılır. Bu geri bildirim döngüsü modeli pratikte daha iyi çalışan önerilere yönlendirir.
Sistemin Pratikteki Performansı Nasıl?
Yazarlar LLM-SPTRec'i SportFit-1M adlı büyük, gerçek dünya veri setinde test ettiler; bu veri seti fitness uygulamaları ve giyilebilir cihazlardan anonimleştirilmiş verileri birleştirir, on binlerce kullanıcıyı ve milyonlarca antrenman kaydı ile fizyolojik veriyi kapsar. Sistemlerini güçlü temel yöntemlerle karşılaştırdılar: klasik işbirlikçi filtreleme, yalnızca geçmiş tercihleri inceleyen bir sıra modeli, ileri düzey bir bilgi grafiği önericisi ve genel amaçlı bir dil modeline dayanan bir çerçeve. LLM-SPTRec bunların hepsini sadece uygun egzersizleri seçmede değil, daha da önemlisi uzmanların daha tutarlı ve kullanıcı hedefleriyle daha yakından uyumlu bulduğu eksiksiz planlar üretmede geride bıraktı. Tahmini kullanıcı memnuniyeti puanları da daha yüksekti ve sertifikalı antrenörlerle yapılan küçük bir insan çalışması, spor özelinde temellenmeyen genel bir dil modeline göre güvenliğini çok daha iyi değerlendirdi.
Geleceğin Dijital Koçluğu İçin Ne Anlama Geliyor
Genel okuyucu için çıkarım şudur: cihazlarınızdan gelen zengin veri, yapılandırılmış olarak kodlanmış uzman spor bilimi ve yaratıcılığı dikkatle yönlendirilen güçlü dil modelleri bir araya geldiğinde daha akıllı, daha güvenli AI koçluğu mümkün olur. LLM-SPTRec, böyle bir kombinasyonun vücudunuzun değişen durumuna ve kişisel hedeflerinize saygı gösteren, gün gün uyarlanabilen antrenman planları üretebileceğini ve zararlı veya mantıksız tavsiyelerin riskini azaltabileceğini gösteriyor. İleride aynı reçete, antrenmanların ötesine; beslenme, yaralanma rehabilitasyonu veya hatta zihinsel iyi oluşa kadar genişleyebilir ve yapay zekâ asistanlarının sıradan sohbet botlarından çok, bilgili ve güvenlik bilincine sahip dijital koçlar gibi davrandığı bir geleceğe işaret edebilir.
Atıf: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Anahtar kelimeler: kişiselleştirilmiş antrenman, spor bilimi AI, fitness önerisi, giyilebilir veriler, bilgi grafiği