Clear Sky Science · tr
Açıklanabilir YZ’de etiket gürültüsü altında yorum kayması
Yapay Zekâ Açıklamaları Neden Sessizce Yanlış Gidebilir
Artık birçok kişi yapay zekâyı yalnızca cevaplar için değil, aynı zamanda gerekçeler için de kullanıyor: Bir kredi neden reddedildi? Bir sistem neden bir hastayı yüksek riskli olarak işaretledi? Bu çalışma, bir YZ modelinin doğruluğu görünürde istikrarlı olsa bile, eğitim verilerinde hata varsa kararının neden alındığına dair anlattığı hikâyenin ciddi şekilde kayabileceğini gösteriyor. Yazarların “yorum kayması” adını verdiği bu gizli değişim, önemli kararları gerekçelendirmek için YZ’ye güvenen profesyonelleri yanıltabilir.
Temiz Verilerle Dağınık Etiketler Karşılaştığında
Çoğu modern YZ sistemi, açık nedenler sunmaksızın tahmin veren “kara kutular”dır. Yapay zekâyı daha şeffaf kılmak için birçok uygulama, insanın if–then mantığını andıran kural tabanlı modellere başvuruyor: örneğin, “eğer kan basıncı yüksek ve yaş 60’ın üzerindeyse, risk yüksektir.” Bu kural setleri sağlık, hukuk ve finans gibi kullanıcıların mantığı incelemesi ve güvenmesi gereken hassas alanlarda özellikle cazip. Ancak gerçek dünya verileri nadiren kusursuzdur. Yaygın sorunlardan biri etiket gürültüsü—eğitim verilerindeki sözde “doğru cevap”ın hatalı olduğu durumlar, örneğin yanlış kaydedilmiş bir tanı veya yanlış etiketlenmiş bir müşteri sonucu gibi. Etiket gürültüsünün tahmin kalitesini düşürdüğü bilinse de, YZ açıklamalarının kararlılığı üzerindeki etkisi sistematik olarak incelenmemişti.
Açıklamaların Gürültü Altında Ne Kadar Dayandığını Test Etmek
Yazarlar, kural tabanlı açıklamaların etiketler kademeli olarak bozulduğunda ne kadar sağlam kaldığını değerlendirdiler. Sağlık, bankacılık, karaciğer hastalığı ve hatta sayılar teorisinden dört farklı veri seti kullandılar; hepsi evet–hayır tahmin görevleri olarak düzenlendi. Üç kural öğrenme yöntemi karşılaştırıldı: iki popüler, hızlı algoritma (IREP ve RIPPER) ve özellikle çok basit, insan-benzeri kural setleri üretmeyi amaçlayan daha hesaplayıcı yoğun bir yaklaşım olan Human Knowledge Models (HKM). Her yöntem için araştırmacılar, eğitim etiketlerinin rastgele ve giderek artan bir kesimini ters çevirerek—neredeyse kusursuz temiz veriden neredeyse tamamen anlamsız hale kadar—modelleri tekrarlı şekilde eğitti. Paralel olarak iki şeyi izlediler: modellerin temiz bir test setinde hâlâ ne kadar iyi tahmin yaptığı ve öğrenilmiş kuralların gürültüsüz verilerdekilerle ne kadar değiştiği.
Doğruluk Sabit, Mantık Dalgalanıyor
Dışarıdan bakınca sonuçlar kullanıcıları yanlış bir güven duygusuna kaptırabilir. Orta düzey gürültü seviyelerinde, özellikle HKM yönteminde, yaygın F1 skoru ile ölçüldüğünde tahmin performansı görece stabil görünüyordu. Ancak kural setlerine daha yakından bakıldığında farklı bir tablo çıktı. Kural topluluklarını karşılaştıran bir benzerlik ölçüsü kullanıldığında, yazarlar mütevazı miktarlardaki etiket gürültüsünün bile orijinal ile gürültülü açıklamalar arasındaki örtüşmeyi hızla aşındırdığını buldular. Başka bir deyişle, model birçok durumda hâlâ doğru olabilir, ancak giderek farklı nedenlerle. Daha karmaşık kural setleri özellikle kırılgandı: bir kuraldaki koşul sayısı arttıkça, verideki küçük değişiklikler bu kuralları daha kolay parçalayabiliyor veya yerine koyabiliyor ve yorumlanabilirlik kararlılığını hızla azaltıyordu.
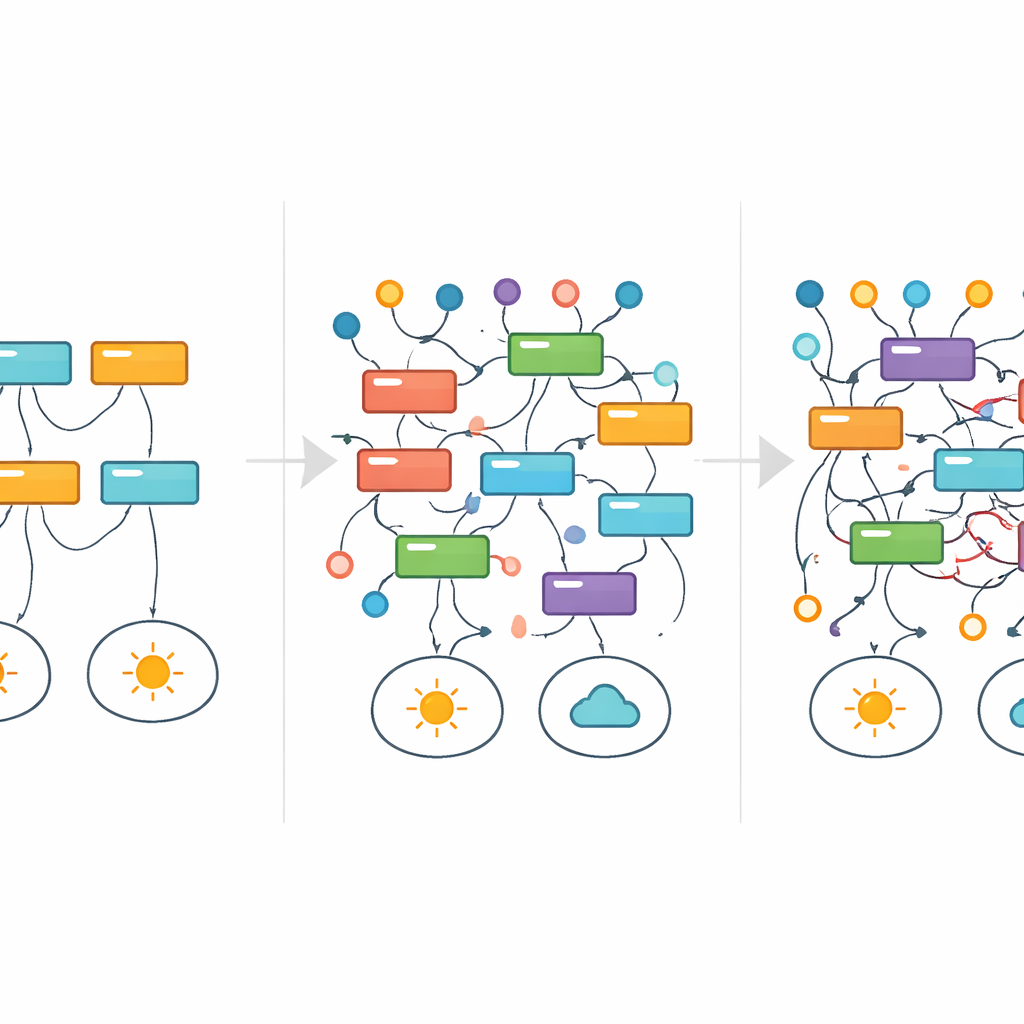
Kuralların Ortaya Çıkışı ve Kayboluşunu İzlemek
Bireysel açıklamaların gürültü arttıkça nasıl hayatta kaldığını veya başarısız olduğunu görselleştirmek için araştırmacılar tıptan bir araç ödünç aldılar: sağkalım analizi. Bir hastanın zamana bağlı sağkalımını izlemek yerine, etiket gürültüsü arttıkça belirli bir kuralın en iyi modeller arasında ne kadar süre görünmeye devam ettiğini izlediler. Nazikçe solmak yerine, birçok kural girip çıktı—aynı temel görev için bile farklı gürültü seviyelerinde tamamen farklı açıklamaların baskın olabileceğinin bir işareti. Örneğin basit bir sayının bölünebilirliği veri setinde, temiz ve matematiksel olarak doğru kurallar kademeli olarak daha geniş yaklaşımlarla ve nihayetinde bozulmuş etiketlere hâlâ uyan karmaşık, görünüşte rastgele desenlerle değiştirildi. Bu sürecin büyük bir bölümünde başlık performans metrikleri açıkça bir sorun olduğunu göstermedi.
YZ’ye Güvenenler İçin Bunun Anlamı
Temel mesaj, “güvenilir” YZ’nin yalnızca doğrulukla değerlendirilemeyeceğidir. Mantığını insan tarafından okunabilir kurallar halinde sunan modeller bile, öğrendikleri etiketler kusurlu olduğunda sessizce muhakemesini değiştirebilir—ki bu çoğu gerçek dünya veritabanında tam da görülen durumdur. Yazarlar, geliştiriciler ve düzenleyicilerin açıklama kararlılığını doğruluk ve adaletle birlikte birinci sınıf bir gereksinim olarak ele alması gerektiğini savunuyor. Bir modelin açıklamalarının gürültü altında ne kadar tutarlı kaldığını doğrudan ölçen yeni metrikler ve kullanıcıları yorum kaymasına karşı uyaran araçlar, sistemlerin dünyayı anlatma biçiminin tahminleri kadar güvenilir olmasını istiyorsak olmazsa olmaz olacaktır.
Atıf: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Anahtar kelimeler: açıklanabilir YZ, etiket gürültüsü, model yorumlanabilirliği, kural tabanlı modeller, yorum kayması