Clear Sky Science · tr
Hastayla konuşmalarda LLM’lerin tanısal sorgulama verimliliğini değerlendirmek için bir ölçüt
Akıllı tıbbi soruların önemi
Bir doktora gittiğinizde duyduğunuz ilk tanı nadiren tek bir belirttiğiniz semptomdan gelir. Bunun yerine hekimler, zamanlama, şiddet, ilişkili sorunlar gibi bir dizi takip sorusu sorarak nelerin yanlış olabileceğini kademeli olarak daraltır. Günümüzün yapay zekâ sistemleri ne kadar güçlü olursa olsun, çoğu hâlâ çoktan seçmeli sınavlarmış gibi test ediliyor; gerçek insanlarla konuşuyormuş gibi değil. Bu makale, büyük dil modellerinin (LLM’ler) “meraklı doktor” rolünü ne kadar iyi oynayabildiğini—doğru teşhise verimli biçimde ulaşmak için doğru soruları doğru sırayla seçmeyi—değerlendirmek üzere Q4Dx adında yeni bir yaklaşım tanıtıyor.
Sınav sorularından gerçek konuşmalara
Mevcut çoğu tıbbi yapay zekâ testi modellere ders kitabı tarzında, tam olarak tanımlanmış vakalar sunar ve onlardan bir tanı seçmeleri istenir. Bu, sistemin “ne bildiğini” gösterir ama hasta detayları unutuyorsa veya günlük dilde semptomları tarif ediyorsa dağınık, gerçek dünya bir konuşmada nasıl davranacağını göstermez. Yazarlar bunun ciddi bir kör nokta olduğunu ileri sürüyor. Kliniklerde bilgi yavaş ve sık sık belirsiz biçimde ortaya çıkar; iyi bir klinisyenin yeteneği, bildikleri kadar ne sorduklarına da bağlıdır. Q4Dx, odağı statik soru-cevaptan zaman içinde soru sorma stratejisine kaydırarak bu boşluğu kapatmak için tasarlandı.
Gerçekçi hasta öyküleri oluşturmak
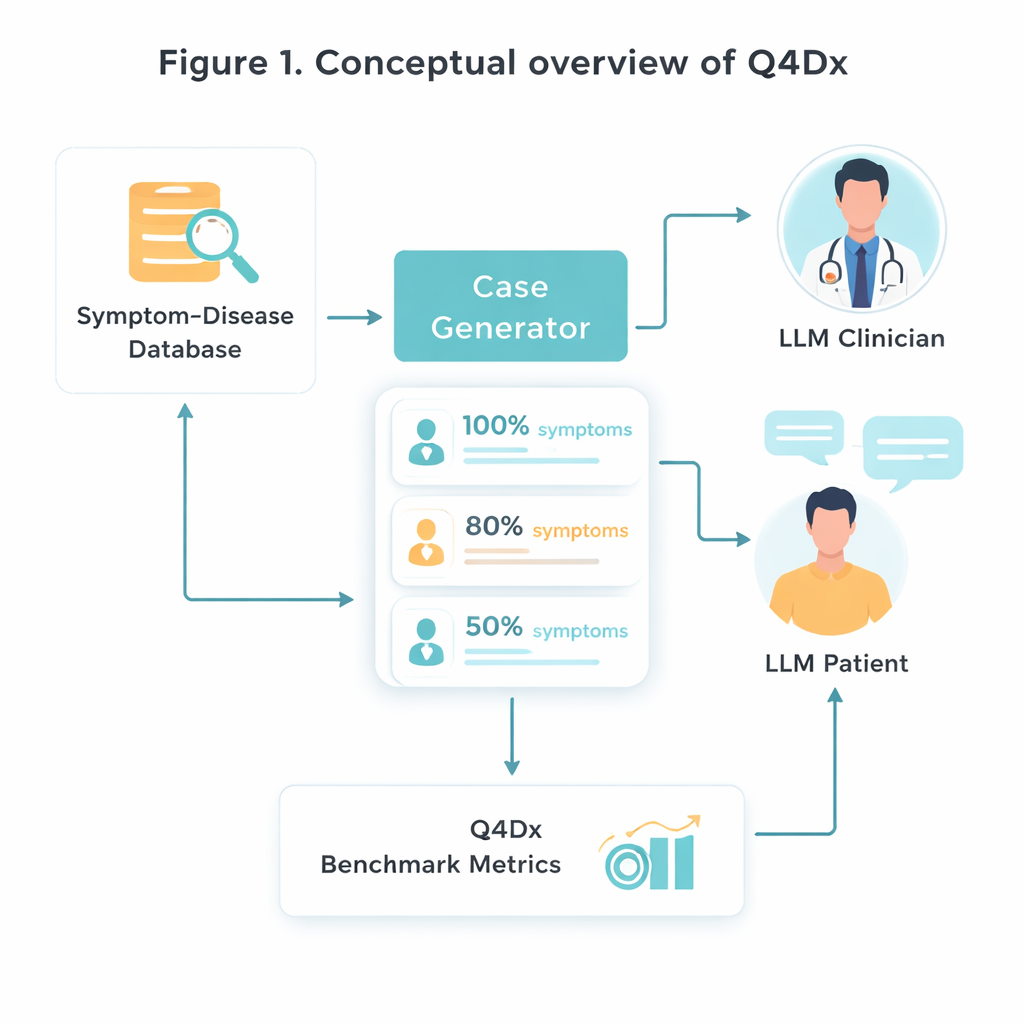
Bu yeni test ortamını oluşturmak için araştırmacılar, belirli hastalıkları karakteristik semptom setleriyle ilişkilendiren küratörlü bir tıbbi kaynaktan başlıyor. Bu türden 100 hastalık–semptom çiftini rastgele seçiyorlar ve sonra steril semptom listelerini klinikte bir kişinin gerçekten anlatabileceği doğal görünümlü hasta kendi‑anlatımlarına dönüştürmek için bir yapay zekâ modeli kullanıyorlar. Her tam vakadan, önemli semptomların yalnızca yaklaşık yüzde 80’i veya yüzde 50’sinin belirtildiği daha kısa versiyonlar üretiyorlar. Bilginin bu kontrollü “gizlenmesi”, önemli ipuçları eksik ya da yalnızca ima edildiğinde farklı modellerin nasıl uyum sağladığını incelemeye olanak tanıyor. Semptom örtüşmesi üzerine yapılan kontroller, kısa versiyonların sadece daha az kelime içermediğini, kullanılabilir bilgiyi gerçekten azalttığını doğruluyor.
Simüle edilmiş doktor–hasta diyaloğu
Q4Dx’in kalbi, iki yapay zekâ ajanı arasında gerçekleşen geniş bir simüle konuşma koleksiyonudur. Bir tanesi hasta rolünü oynar; altında yatan hastalığa ve tam semptom setine tam erişimi vardır. Diğeri doktor rolündedir: başlangıçta yalnızca kısmi, muhtemelen belirsiz bir vaka açıklaması görür ve sırada ne soracağına karar vermelidir. Her hasta yanıtından sonra doktor ajanı geçici bir teşhis yapar ve düşüncesinin nasıl evrildiğine dair adım adım bir iz oluşturur. Tüm sorular, cevaplar ve ara tahminler kaydedilerek kıyaslama yalnızca modelin doğru olup olmadığını değil, oraya nasıl vardığını da yakalar. Bu yapay zekâ tarafından üretilen soru dizileri, mükemmel tıbbi gerçek olarak değil, gelecekteki modellerin ve hatta insan stajyerlerin karşılaştırılabileceği tutarlı bir ölçüt olarak referans stratejiler şeklinde kullanılır.
Sadece doğru cevapları değil, iyi soruları ölçmek
Performansı değerlendirmek için yazarlar üç basit ama tamamlayıcı ölçüt tasarlıyor. Sıfır‑Atış Tanısal Doğruluk (Zero‑Shot Diagnostic Accuracy, ZDA): modele vakayı tamamen baştan verirseniz doğru hastalığı hemen söyleyebiliyor mu? Doğru Teşhise Ortalama Soru Sayısı (Mean Questions to Correct Diagnosis, MQD) verimliliği yansıtır: modele ilk kez doğru teşhise ulaşana kadar ortalama kaç hasta sorusu gerekir (en fazla beş soru sınırıyla)? Sorgulama Dizisi Verimliliği (Interrogation Sequence Efficiency, ISE) ise sorgulama yolunun kalitesine bakar—modelin seçtiği soruların anlam olarak referans dizisine ne kadar benzediğini değerlendirir. Bu ölçütleri kullanarak ekip, güçlü bir genel amaçlı modelin (GPT‑4.1) eksiksiz bilgiyle yaklaşık yarı zamanında doğru teşhis koyduğunu, ancak semptomlar gizlendiğinde doğruluğunun düştüğünü gösteriyor. Aynı zamanda, etkileşimli oturumları genellikle sadece birkaç iyi seçilmiş sorudan sonra başarılı oluyor ve soruları ardışık turlarda uzman‑benzeri stratejilerle daha uyumlu hale geliyor.

Geleceğin tıbbi yapay zekâsı için anlamı
Uzman olmayanlar için bu çalışmanın mesajı açıktır: tıpta akıllıca soru sormak, doğru cevaplara sahip olmak kadar önemlidir ve yapay zekâ her ikisi açısından da değerlendirilmelidir. Q4Dx tam olarak bunu yapmaya yönelik tekrar kullanılabilir, herkese açık bir çerçeve sunuyor. Değişken miktarda eksik bilgi içeren gerçekçi hasta öyküleri, ayrıntılı konuşma izleri ve doğruluk ile verimliliğin net ölçümleri sağlayarak bu kıyaslama, araştırmacıların farklı yapay zekâ sistemlerini karşılaştırmasına ve kontrollü koşullar altında insan klinisyenlerle bile rekabet etmelerine imkân tanıyor. Zamanla Q4Dx gibi araçlar daha güvenli, daha güvenilir klinik asistanların eğitilmesine ve doktorların ile öğrencilerin tanı görüşmesi öğrenimini iyileştirmeye yardımcı olabilir—nihayetinde gerçek hastalar için daha iyi bakımı destekleyebilir.
Atıf: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Anahtar kelimeler: tıbbi yapay zeka, tanısal akıl yürütme, klinik diyalog, büyük dil modelleri, sorgulama stratejisi