Clear Sky Science · tr
MQADet: multimodal soru-cevap ile açık-vokabüler nesne algılamayı geliştirmeye yönelik tak-çalıştır paradigma
Neden daha akıllı nesne bulucular önemli?
Telefonlar, otomobiller, ev robotları ve arama motorları giderek daha fazla resimlerde nesneleri bulabilen yazılımlara dayanıyor: bir çocuğun caddeyi geçmesi, masadaki kayıp anahtarınız veya raftaki belirli bir ürün. Ancak bugünün çoğu sistemi yalnızca “köpek” veya “araba” gibi kısa, basit etiketleri anlıyor. “Kırmızı tasmalı, kanepe minderi arkasında yatan küçük köpek” diye sorduğunuzda genellikle kafaları karışıyor. Bu makale, mevcut nesne bulma sistemlerini temel modelleri yeniden eğitmeden bu tür zengin, ayrıntılı betimlemeleri anlayacak şekilde yükseltmenin bir yolunu—MQADet’i—tanıtıyor.
Sabit listelerden açık uçlu anlayışa
Geleneksel nesne algılayıcılar, popüler COCO veri kümesindeki 80 günlük eşya gibi sabit kategori listeleri üzerinde eğitilir. Nesne bu kategorilerden birine ait olduğu ve istek kısa ve net olduğu sürece iyi çalışırlar. Ancak gerçek dünya düzensizdir. İnsanlar uzun ifadeler, ince nitelikler ve “kamyonun arkasında duran sarı yelekli adam” gibi ilişkiler kullanarak referans verir. Yeni nesil “açık-vokabüler” algılayıcılar görüntüleri metinle bağlayarak sabit listelerden kurtulmaya çalışıyor, fakat yine de karmaşık ifadeler ve eğitim verilerinde nadiren görülen, uzun kuyruklu kategorilerle zorlanıyorlar. Ayrıca gelişmek için çok fazla hesaplama gücü ve veriye ihtiyaç duyuyorlar.
Dil modellerinin aramaya rehberlik etmesine izin vermek
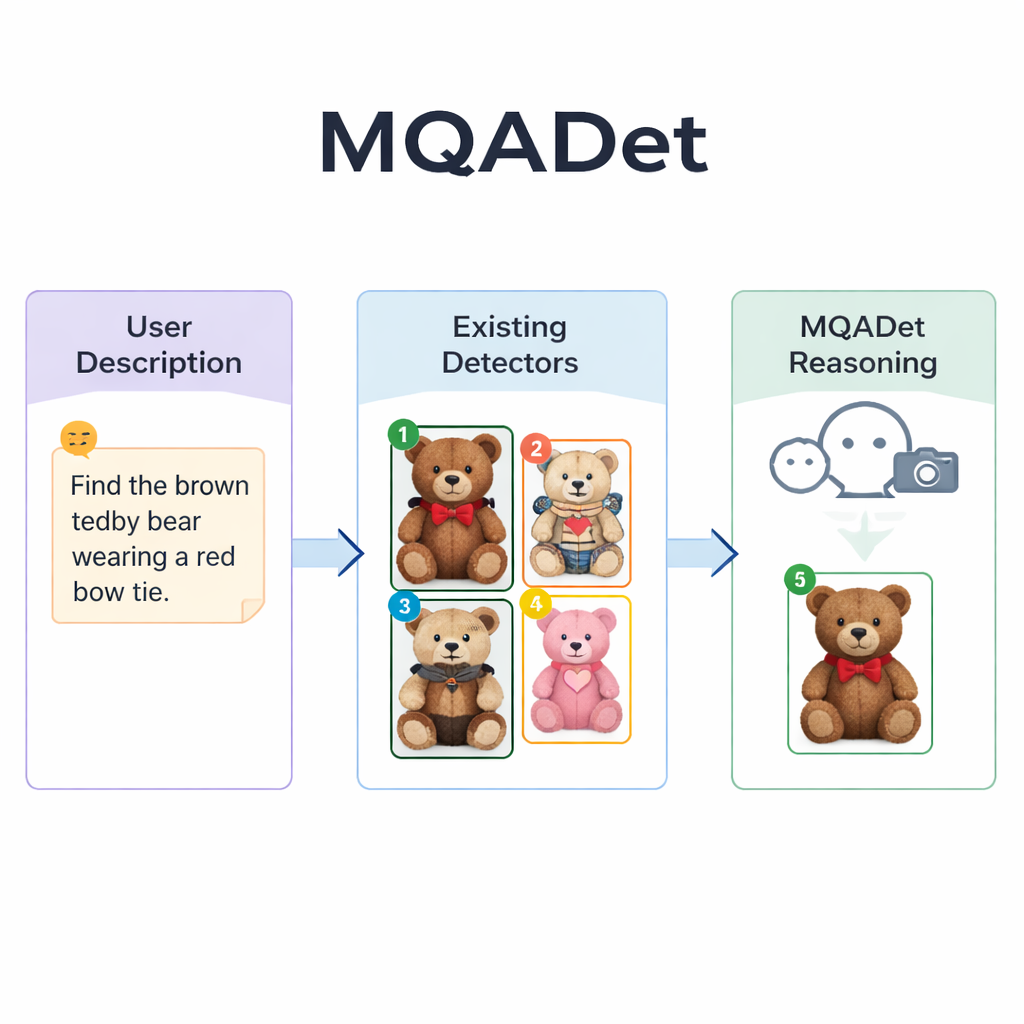
MQADet, bu sorunları mevcut algılayıcıların üzerine yerleştirilmiş—görüntüye bakabilen ve metin okuyabilen—multimodal büyük dil modeli kullanarak üç aşamalı bir soru-cevap süreciyle ele alır. İlk aşama olan Metin-Farkında Konu Çıkarma, kullanıcının tüm cümlesini okur ve uzun bir açıklamadan “şemsiye” veya “yaya” gibi gerçek hedefleri çıkarır. Bu, bir kişinin sahneyi taramadan önce cümledeki ana isimleri hızla belirlemesine benzer. Önemli olarak, bu aşama dil modelinin doğal dili güçlü şekilde kavramasından yararlandığı için yalnızca tek kelimeler yerine uzun, betimleyici ifadelerle başa çıkabilir.
Görüntüde aday nesneleri işaretleme
İkinci aşamada, Metin-Yönlendirmeli Multimodal Nesne Konumlandırma, MQADet bu çıkarılmış konuları ve görüntüyü mevcut bir açık-vokabüler algılayıcıya—örneğin Grounding DINO, YOLO-World veya OmDet-Turbo—verir. Algılayıcı, her konu için görüntüde olası birkaç konum önerir, her adayın etrafına bir kutu çizer ve kutunun içine basit bir sayı yerleştirir. Sonuç tüm makul seçenekleri gösteren “işaretlenmiş bir görüntü” olur. Önemle belirtmek gerekirse, MQADet bu algılayıcıları yeniden eğitmez; onları oldukları gibi kullanır. Bu yaklaşımı tak-çalıştır yapar: daha iyi bir algılayıcı çıktığında, ek veri veya ayar gerektirmeden boru hattına takılabilir.

En iyi eşleşmeye akıl yürütmeyle ulaşmak
Üçüncü aşama, MLLM’lerin Yönlendirdiği Optimal Nesne Seçimi, son kararı dil modeli için çoktan seçmeli bir soruya dönüştürür: orijinal açıklama ve numaralandırılmış kutularla işaretlenmiş görüntü verildiğinde hangi sayı metne en iyi uyar? Model hem ayrıntılı ifadeyi hem görsel düzeni gördüğü için desenler, renkler, “solda” gibi mekânsal ilişkiler ve nesneler arasındaki etkileşimler gibi ince ipuçlarını değerlendirebilir. Yazarlar, bu akıl yürütme adımını kaldırmanın doğruluğu ciddi şekilde düşürdüğünü göstererek önemini vurguluyor. Bu üç aşamalı tasarımı kullanarak MQADet, uzun, doğal cümleler içeren dört zorlu değerlendirmede doğruluğu artırdı ve genellikle mevcut algılayıcıların performansını iç ağırlıklarını değiştirmeden yüzde 10–40 oranında iyileştirdi.
Günlük teknoloji için anlamı
Uzman olmayan biri için temel mesaj, nesne algılayıcıları baştan inşa etmeden onları daha akıllı hale getirebileceğimizdir. MQADet, mevcut sistemlerin üzerine oturan zeki bir asistan gibi davranarak zengin insan betimlemelerini yorumlamalarına ve karmaşık sahnelerde doğru nesneyi seçmelerine yardımcı olur. Bu, görsel aramayı, yardımcı araçları ve otonom makineleri insanların doğal konuşma biçimi—ayrıntılı, nüanslı ve bağlam dolu—ile başa çıkarken daha güvenilir hale getirebilir ve görsel dünya ile daha sezgisel, dil odaklı etkileşime yol açabilir.
Atıf: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Anahtar kelimeler: açık-vokabüler nesne algılama, multimodal büyük dil modelleri, görsel soru-cevap, bilgisayarla görme, görüntü anlama