Clear Sky Science · tr
Performans boşluğunu kapatmak: Japonca tıbbi KİB (PHI) çıkarımı için yerel LLM’lerin sistematik optimizasyonu
Hasta gizliliği açısından bunun önemi
Hastaneler, bakım ve araştırmayı iyileştirebilecek çok sayıda tıbbi not barındırır; ancak bu kayıtlar isimler, adresler ve tarihler gibi hassas ayrıntılarla doludur. Güçlü bulut tabanlı yapay zekâ sistemleri bu bilgileri gizlemede çok iyidir, fakat birçok hastanenin ham hasta verilerini dış sunuculara göndermesine izin verilmez. Bu çalışma, dikkatli ayarlamalarla hastane içinde tamamen çalışan daha küçük yapay zekâ modellerinin, lider bulut sistemlerinin performansına şaşırtıcı derecede yaklaşabileceğini gösteriyor — böylece hasta verilerini kurum içinde tutarken yapay zekâ kullanımına olanak sağlayan bir yol sunuyor.
Gizlilik ve ilerleme ikilemi
Günümüzün büyük dil modelleri, tıbbi metinlerden korunan sağlık bilgilerini (PHI) güvenilir şekilde tespit edip kaldırabiliyor ve genellikle %90’ın üzerinde doğruluk sağlıyor. Ancak düzeltilmemiş hasta notlarını bulut hizmetlerine göndermek, HIPAA, GDPR ve Japonya’nın APPI’si gibi düzenlemeler kapsamında yasal ve etik endişeler doğuruyor. Birçok kurum, bilgilerin kendi bilgisayarlarını asla terk etmemesi anlamına gelen tam “veri egemenliği” talep ediyor. Bugüne kadar, kurum içi donanımda çalışabilen yerel modeller genellikle çok daha fazla tanımlayıcıyı kaçırıyordu; bu da hastaneleri bir ödünleşime zorluyordu: bulutta güçlü analizler ya da daha katı gizlilikle daha zayıf araçlar. Yazarlar, bu farkın gerçek dünya klinik kullanımı için yeterince kapatılıp kapatılamayacağını araştırmayı amaçladı.
Daha akıllı yerel yapay zekâ için aşamalı bir oyun planı
Ekip, Japonca radyoloji raporlarında PHI kaldırma performansını kademeli olarak iyileştirmek için beş adımlı bir optimizasyon çerçevesi tasarladı. Hastane güvenliğini taklit etmek üzere izole, internetsiz bir bilgisayarda çalıştırılan çeşitli boyutlarda 14 farklı modelle başladılar. Gerçekçi ama tamamen kurgusal 160 dikkatle hazırlanmış sentetik rapor kullanarak her modelin isimler ve kimlik numaralarından tarihlere ve bölümlere kadar sekiz tür tanımlayıcıyı ne kadar iyi bulup ayırdığını ölçtüler. İlk temel testin ardından daha yararlı genel istemler (prompt) oluşturuldu, sonra her modelin özelliklerine göre özelleştirilmiş talimatlar eklendi, otomatik bir “kendi kendini kontrol ve düzelt” döngüsü ilave edildi ve son olarak en iyi adaylar ayrılmış rapor seti üzerinde test edildi. 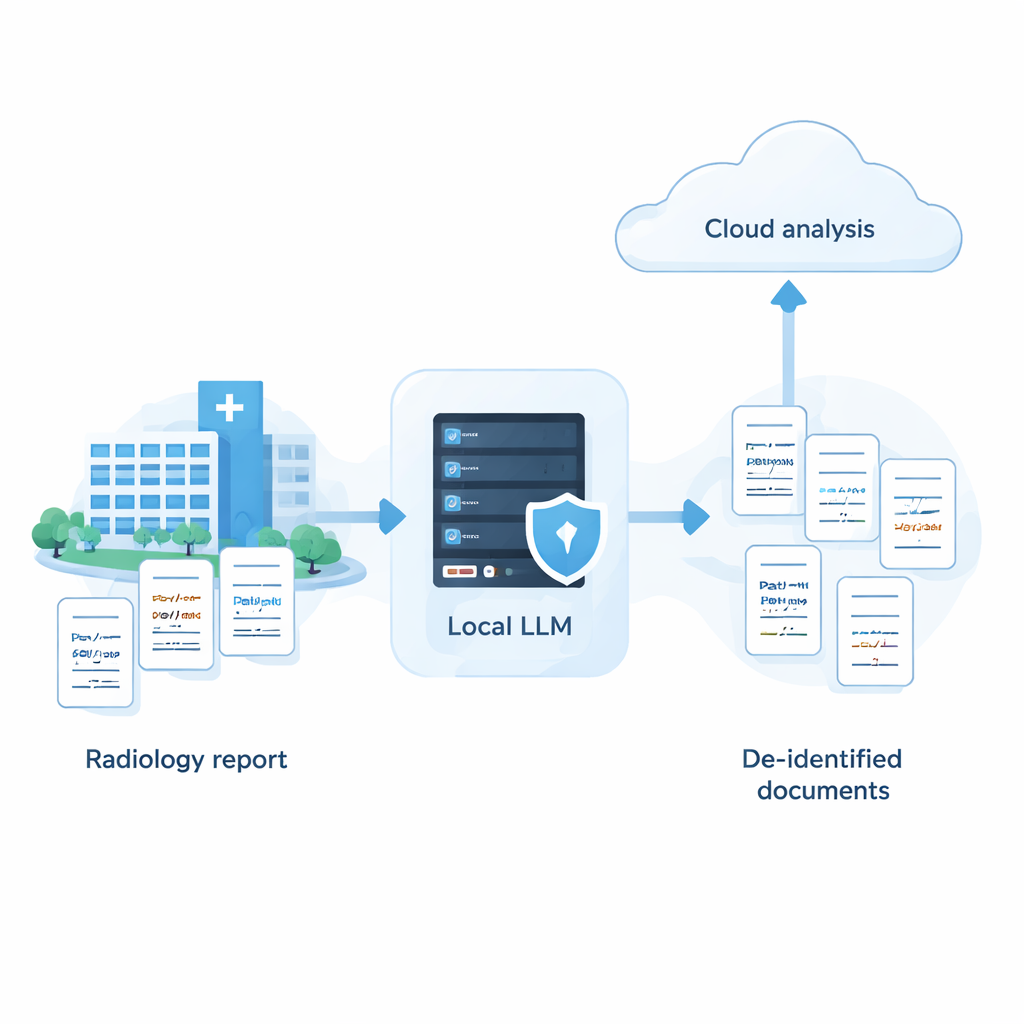
Bulut düzeyine yaklaşmak
Bu aşamalı süreçte araştırmacılar, ham model boyutunun başarının anahtarı olmadığını keşfettiler; çok büyük bazı sistemler hâlâ zayıf performans gösteriyordu. Bunun yerine, en umut verici modeller dikkatli talimat tasarımı ve hata analizine iyi yanıt verenler oldu. Orta boy bir sistem olan Mistral-Small-3.2, özel istemler ve modelin kendi çıktısını gözden geçirip seçici şekilde düzelttiği bir öz‑düzeltme adımının ardından açık ara kazanan haline geldi. Son 60 test vakasında bu optimize yerel kurulum 100 üzerinden 91,54 puan aldı — lider bulut modelinin 93,56 puanının yaklaşık %97,8’i — ve biçimlendirme kurallarına mükemmel uydu. Pratikte kalan fark klinik olarak önemsiz bulundu. Temel maliyeti hızdı: yerel işlem tipik bir rapor için yaklaşık 25 saniye sürerken bulutta bu süre 2 saniyenin altındaydı; ancak bu rutin, acil olmayan toplu işler için kabul edilebilir bulundu. 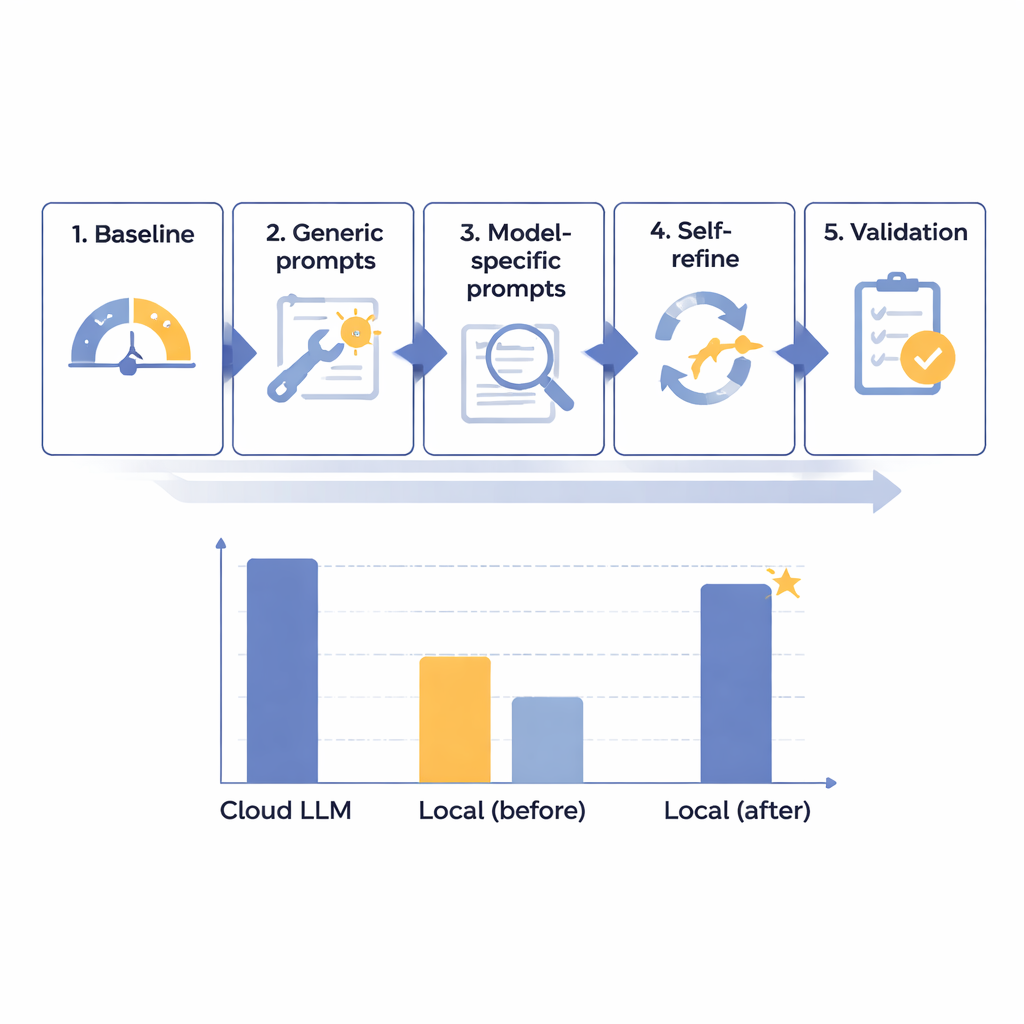
Öz-düzeltme için şaşırtıcı bir eşik
En ilgi çekici bulgulardan biri, yazarların 100 puanlık ölçeğinde yaklaşık 87–88 puan civarında bir dönüm noktası gibiydi. Başlangıçta bu seviyenin altında puan alan modeller — Mistral-Small-3.2 gibi — öz‑düzeltme döngüsünden büyük ölçüde faydalandı ve kendi hatalarının küçük bir kısmını düzelterek neredeyse yedi puan kazandı. Zaten bu eşikten yüksek puanla başlayan modeller ise neredeyse hiç gelişme göstermedi ve bazen doğru cevapları “düzeltmeye” çalışarak emek israfına neden oldu. Bu, gelişmiş optimizasyon araçlarının iyi ama mükemmel olmayan modeller için ayrılmasının daha verimli olduğunu, hastanelerin hesaplama gücü ve personel zamanını en çok işe yarayan yerlere yönlendirmesini sağlayabileceğini öne sürüyor. Yazarlar, bu eşik değerinin yalnızca iki modele dayandığını ve doğrulanması gerektiğini belirtiyor; yine de dağıtım planlaması için erken bir başparmak kuralı sunuyor.
Hastaneler ve hastalar için anlamı
Çalışma, hastanelerin güçlü gizlilik ile güçlü yapay zekâ arasında seçim yapmak zorunda olmadığını savunuyor. Sistematik bir yaklaşımla — çok sayıda modeli taramak, istemleri modellerin güçlü ve zayıf yönlerine göre ayarlamak ve akıllı bir kendi kendini gözden geçirme adımı eklemek — tamamen yerel bir sistemin tıbbi metinlerden hassas bilgileri kaldırmada en iyi bulut hizmetlerinin doğruluğuna yaklaşmasının mümkün olduğu gösterildi. Pratikte bu, hibrit bir stratejinin kapısını açıyor: PHI hastane sahipliğindeki makinelerde güvenle temizleniyor ve yalnızca isimleri ve diğer tanımlayıcıları kaldırılmış anonimleştirilmiş raporlar daha ileri analiz için buluta gönderiliyor. Bugüne kadar yapılan çalışma sentetik Japonca radyoloji raporlarına dayandığından, gerçek dünya verileri ve diğer diller üzerinde test edilmesi gerekiyor; yine de bu, hasta güveni ve gizliliğini merkezde tutarak yapay zekâyı kullanmak isteyen kurumlar için uygulanabilir bir yol haritası sunuyor.
Atıf: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Anahtar kelimeler: tıbbi kimliksizleştirme, hasta gizliliği, yerel dil modelleri, sağlık hizmetleri yapay zekâsı, radyoloji raporları