Clear Sky Science · tr
Sağlık ve eğitim verileri kullanılarak iki aşamalı örnekleme altında makine öğrenmesine dayalı varyans tahmini
Gerçek dünya kararları için daha akıllı ortalamaların önemi
Doktorlar kan basıncını incelerken veya eğitimciler öğrenci notlarını takip ederken yalnızca ortalamayla ilgilenmezler; insanların bu ortalama etrafında ne kadar farklılaştığını da bilmek isterler. Bu yayılma, değişkenlik olarak adlandırılır ve bir deneye kaç hasta alınması gerektiğini, bir destek programının ne kadar büyük olması gerektiğini veya politika kararlarına ne kadar güvenilebileceğini belirler. Bu özeti hazırlayan makale, klasik örnekleme fikirlerini modern makine öğrenimi ile harmanlayarak bu değişkenliği daha hassas ölçmenin yeni, istatistiksel olarak sağlam bir yolunu sunuyor ve bunu sağlık ile eğitim verileri üzerinde test ediyor.
Bilginin eksik olduğu durumda yayılmayı ölçmek
İdeal bir dünyada araştırmacılar anket yapmadan önce bir nüfustaki her kişi hakkında yaş, çalışma alışkanlıkları, sağlık geçmişi gibi ek ayrıntılara sahip olurdu. Gerçekte ise bu bilgiler genellikle eksik olur veya toplaması pahalıdır. Yazarlar bu durumu ele almak için iki aşamalı örnekleme tasarımıyla çalışıyor. Birinci aşamada daha büyük ve nispeten ucuz bir örnek alınır ve yaş veya internet erişimi olup olmadığı gibi basit arka plan bilgileri kaydedilir. İkinci aşamada daha küçük bir alt örnek seçilir ve sistolik kan basıncı veya final sınav notu gibi daha maliyetli veya zaman alan çıktı ölçülür. Zorluk, bu iki bilgi katmanını kullanarak çıktının tüm nüfustaki gerçek değişkenliğini tahmin etmektir.
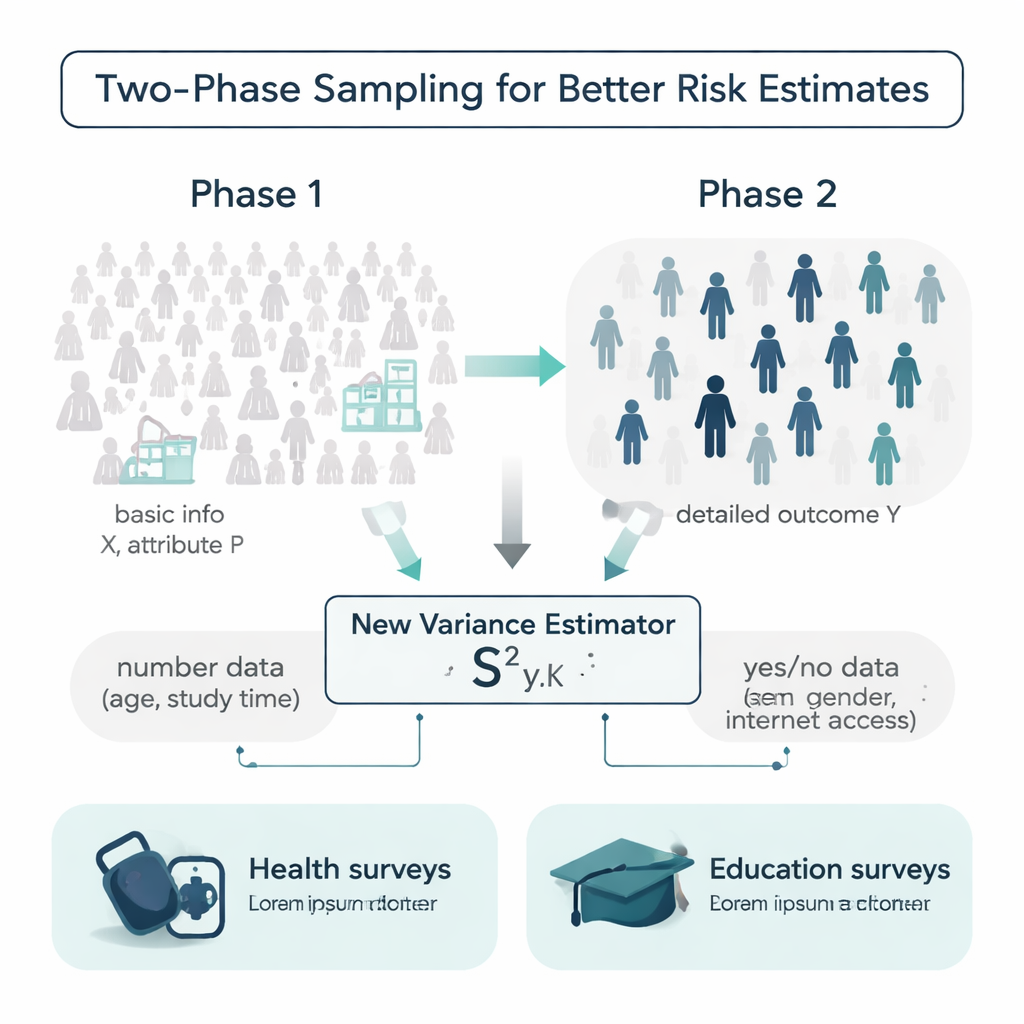
Hem sayısal hem ikili özellikleri kullanan yeni bir tahminci
Çoğu geleneksel değişkenlik ölçütü yalnızca çıktıya veya tek bir yardımcı değişkene dayanır ve genellikle verilerin uygun çan şeklinde dağıldığını varsayar. Yazarlar, aynı anda iki tür ek bilgiyi kullanan yeni bir varyans tahmincisi öneriyor: sayısal bir yardımcı (örneğin yaş veya haftalık çalışma süresi) ve evet/hayır niteliğinde bir özellik (örneğin cinsiyet veya internet erişimi). Bu birleşik “karışım” tahmincisinin davranışını matematiksel olarak gösteriyorlar ve önyargı ile ortalama kare hatası için formüller türetiyorlar — doğruluğun iki önemli ölçüsü. Makul koşullar altında tahmincinin etkin şekilde eğilimsiz olduğu ve beklenen hatasının yaygın olarak kullanılan rakip formüllerden daha küçük olduğu gösteriliyor; bu da aynı veri miktarından daha keskin belirsizlik tahminleri elde edilmesi gerektiği anlamına geliyor.
Çok sayıda veri dünyasında performansı test etmek
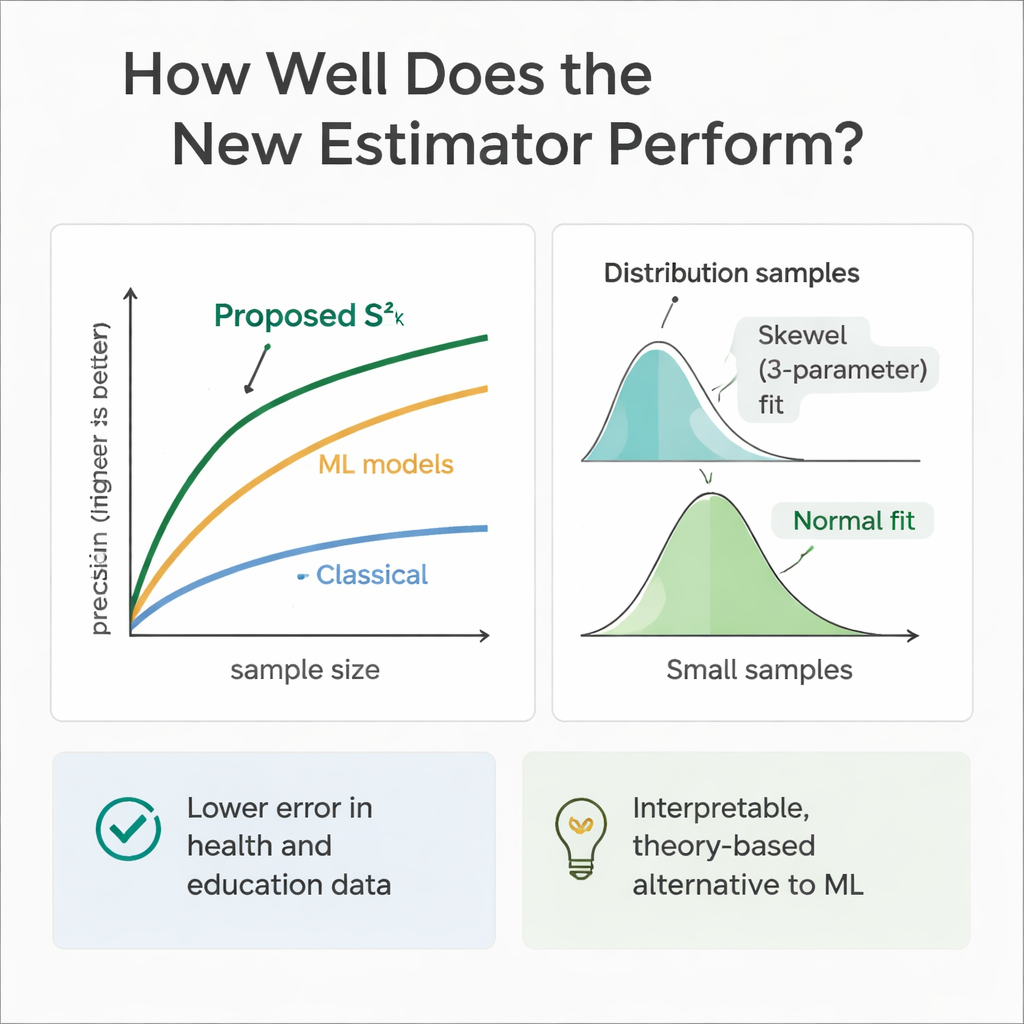
Kuramın pratiğe uyup uymadığını kontrol etmek için ekip kapsamlı bilgisayar denemeleri gerçekleştirdi. Yardımcı değişkenlerin ve çıktının simetrik (Normal ve Uniform) ile çarpık (Gamma ve Weibull) arasındaki çeşitli dağılımları izlediği nüfuslar simüle ettiler. Tekrarlanan örneklemeyle yeni tahmincinin hatasını, bir dizi yerleşik yöntemle ve farklı örneklem büyüklüklerinde karşılaştırdılar. Neredeyse her durumda, özellikle örneklem büyüklükleri arttıkça yeni yaklaşım çok daha yüksek göreli verimlilik gösterdi — klasik varyans tahmincisine göre hatayı sıklıkla yüzde 30 ila 70 oranında azalttı. Yazarlar ayrıca tahmincinin kendi örnekleme dağılımının nasıl davrandığını inceledi; mütevazı örnekler için üç parametreli esnek bir Weibull eğrisinin en iyi uyumu sağladığını, örneklem büyüklükleri büyük hale geldikçe dağılımın Normal şekline yaklaştığını buldular.
Kliniklerden ve sınıflardan gerçek veriler
Yöntem iki gerçek dünya vaka çalışmasına uygulandı. Sağlık veri setinde çıktı sistolik kan basıncıydı; sayısal yardımcı yaş ve ikili özellik ise cinsiyetti. Eğitim veri setinde çıktı final ders notu, yardımcı haftalık çalışma süresi ve özellik öğrencinin internete erişimi olup olmadığıydı. Her iki durumda da önerilen tahminci test edilen istatistiksel rakipler arasında en küçük ortalama kare hatayı üretti ve ortalama kan basıncı ile ortalama öğrenci performansı etrafındaki tahmini değişkenliği önemli ölçüde daralttı. Bu gelişme daha kesin güven aralıklarına ve gruplar veya müdahaleler arasındaki karşılaştırmalarda daha güvenilir sonuçlara dönüşüyor.
Makine öğrenimiyle karşılaştırması nasıl
Makine öğrenimi modelleri tahminde çok başarılı olduğu için yazarlar regresyon ağaçları, rastgele ormanlar ve destek vektör regresyonunu aynı simüle edilmiş sağlık ve eğitim senaryolarında eğittiler. Aynı yardımcı değişkenlerle beslenen bu modeller genelde saf tahmin doğruluğunda yeni tahminciye eşit veya biraz üstün performans gösterdiler. Ancak bunlar kara kutu gibi davranıyor: bilgiyi nasıl birleştirdiklerini izlemek zor ve geleneksel örnekleme çıkarımı için gereken temiz formüllerden yoksunlar. Öte yandan önerilen tahminci şeffaf ve örnekleme kuramına dayanıyor; bu da düzenleyici, klinik veya politika ortamlarında açıklanabilirliğin ham performans kadar önemli olduğu durumlarda savunulmasını kolaylaştırıyor.
Uygulamada anketlere ne anlamı var
Basitçe söylemek gerekirse, bu çalışma araştırmacıların örneklem büyüklüklerini dramatik şekilde artırmadan daha güvenilir yayılma ölçüleri elde edebileceğini gösteriyor; yapmaları gereken şey zaten topladıkları en az ekstra bilgiyi disiplinli şekilde kullanmak. İki aşamalı örnekleme planında sayısal bir faktörü (yaş veya çalışma süresi gibi) basit bir evet/hayır niteliğiyle (cinsiyet veya internet erişimi gibi) harmanlayarak yeni tahminci, uzun süredir kullanılan yöntemlerden daha keskin ve daha stabil varyans tahminleri veriyor. İleri düzey makine öğrenimi araçları karşılaştırma için yararlı kalmaya devam etse de bu yaklaşım pratik ve yorumlanabilir bir orta yol sunuyor; sağlık ve eğitim analistlerinin sınırlı verilerden daha sağlam sonuçlar çıkarmasına yardımcı oluyor.
Atıf: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Anahtar kelimeler: anket örneklemesi, varyans tahmini, makine öğrenimi, sağlık verileri, eğitim araştırması