Clear Sky Science · tr
Uzay donanımı arıza raporlamasında taksonomik modelleme ve sınıflandırma
Uzay Uçuşu Arızalarında Desen Bulmak
Her uzay görevi, cıvatalardan ve kablolardan yaşam destek sistemlerine kadar sayısız donanım parçasının kusursuz çalışmasına dayanır. Bir şey ters gittiğinde mühendisler ayrıntılı uyumsuzluk raporları tutar, ancak NASA’nın artık 54.000’den fazla böyle kaydı var—bunların tek tek okunması insan gücüyle mümkün değil. Bu çalışma, modern dil ve makine öğrenimi araçlarının o metin yığınını nasıl düzenli bilgiye dönüştürebileceğini gösteriyor; böylece mühendisler arızalardaki örüntüleri tespit edebiliyor, tasarımları iyileştirebiliyor ve astronotları daha güvende tutabiliyor.
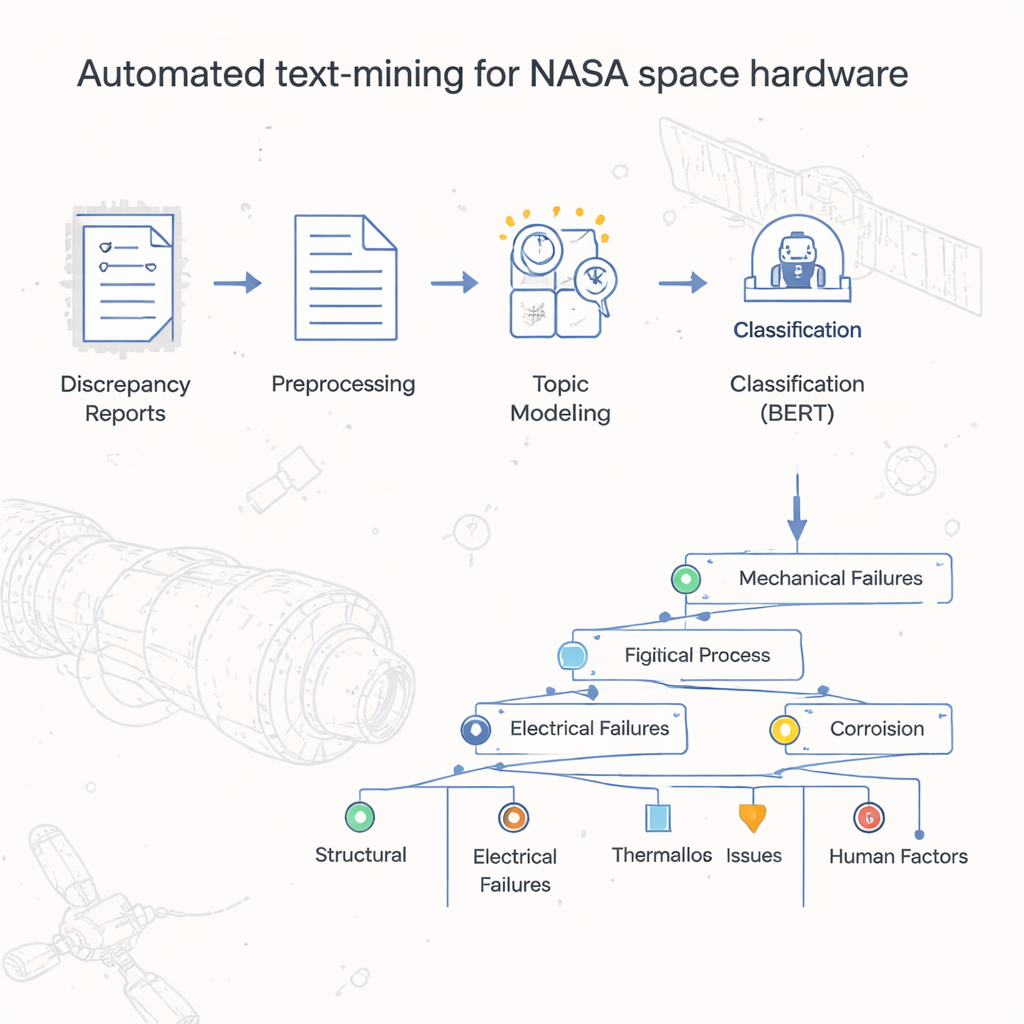
Rapor Yığınlarından Düzenlenmiş İçgörüye
On yıllardır NASA’nın Johnson Uzay Merkezi, donanım arızası ve uyumsuzluk raporlarını dijital belgeler olarak sakladı; tıpkı eski kağıt formların taranmış halleri gibi. Temel elektronik tablo sayımları hangi resmi kusur kodlarının daha sık göründüğünü ortaya koyuyordu, fakat asıl hikâye—sorunlara yol açan özgül nedenler, adımlar ve koşullar—serbest biçimli metin alanlarının içinde gömülüydü. 54.000’den fazla kaydı elle okumak ve sınıflandırmak zaman açısından imkânsız olurdu. Yazarlar, bu raporları otomatik olarak sınıflandırıp gruplandıracak; uzay donanımının günlük uygulamada nasıl arıza yaptığını yakalayan bir tür “harita” ya da taksonomi oluşturacak bir yöntem geliştirmeyi amaçladılar.
Mühendislik Dilini Bilgisayarlara Öğretmek
Ekip önce her rapordaki metni bilgisayarların etkin şekilde işleyebilmesi için temizledi. Gürültü yapan rastgele semboller ve sayılar çıkarıldı, cümleler tek tek kelimelere ayrıldı ve daha basit kök biçimlere dönüştürüldü (örneğin “sızdı” ve “sızıyor” gibi formlar “sızıntı”ya indirgenebilir). “Ve” ya da “the” gibi az anlam taşıyan yaygın kelimeler filtrelendi. Metin standartlaştırıldıktan sonra, araştırmacılar onu makine öğrenimi algoritmalarının kullanabileceği sayılara çevirdiler; kelimelerin ne sıklıkla göründüğünü ve bir belgeyi ne kadar karakterize ettiklerini yakalayan yerleşik teknikler kullanıldı. Bu temel çalışma, genel dil görevleri için geliştirilmiş güçlü araçların uzay donanımı raporları gibi yüksek uzmanlık gerektiren bir alana uygulanmasına olanak verdi.
Arıza Türlerinden Bir Ağaç Kurmak
Projenin merkezinde yazarların LDA-BERT adını verdikleri iki aşamalı bir model var. İlk adım olan Latent Dirichlet Allocation (LDA), binlerce rapor boyunca birlikte görünme eğiliminde olan kelime örüntülerini bularak otomatik olarak temalar—yani konular—keşfeder. Tek bir rapor birden fazla konuyu karıştırabilir; bu, gerçek hayatta bir donanım sorununun birden çok etkene bağlı olabileceğini yansıtır. İkinci adımda modern bir dil modeli olan BERT, bu konuların raporları ne kadar iyi ayırdığını kontrol edip iyileştirir. LDA konularını geçici etiketler olarak ele alıp BERT’i bunları tahmin edecek şekilde eğiterek, araştırmacılar kararlı ve doğru sınıflandırmalar veren konu sayısını ve kombinasyonunu belirleyebildiler. Ardından her konuyu kümeleme ve istatistiksel kontrollerle alt konulara böldüler; böylece geniş kusur kodlarından detaylı süreç düzeyi etiketlere kadar dallanan bir taksonomi inşa ettiler.
Taksonomileri Eyleme Dönüştürmek
Taksonomi kurulduktan sonra ekip bunu paneller ve etkileşimli araçlarla görselleştirdi. Ağacın her dalı ve alt dalı raporlardaki diğer bilgilerle ilişkilendirilebiliyordu: bir sorunun ilk ne zaman not edildiği, kapatılmasının ne kadar sürdüğü, hangi organizasyonun sorumlu olduğu ve hangi nihai kararın verildiği gibi. Zaman serisi çizimleri, inceleme gözden kaçırmaları ya da tolerans verisi sorunları gibi belirli problem türlerinin yıllar içinde daha yaygınlaşıp yaygınlaşmadığını gösterdi. Kelime haritaları, her kümede kullanılan dile hızlı bir bakış sunarak her raporu okumaya gerek bırakmadı. Bu görünümler, yöneticilerin yüksek trendli ve yüksek etkili süreç arızalarına odaklanmasına yardımcı olur; eğitim, prosedür değişiklikleri veya tasarım güncellemelerini en çok etkisi olacak alanlara yönlendirir.
Otomatik Kök Neden Aramanın Sınırları
Araştırmacılar ayrıca etiketlemenin ve trend tespitinin ötesine geçip metinden doğrudan neden-sonuç ilişkileri çıkarma girişimlerini de incelediler. INDRA-Eidos gibi sistemleri ve spaCy dil kütüphanesiyle oluşturulmuş özel kural setlerini test ettiler. Bu araçlar bazı neden-sonuç çiftlerini çıkarıp bunları etkileşimli ağlar şeklinde görselleştirebilse de, önerilen bağlantıların birçoğu kullanışlı olmaktan çok belirsiz veya kafa karıştırıcıydı. Uygulamada modeller zorlandı çünkü orijinal raporlar genellikle kök nedenleri açıkça belirtmiyordu; mühendisler bunları ima ediyor veya daha sonraki soruşturmaya bırakıyordu. Çalışma, kök neden keşfini güvenilir şekilde otomatikleştirmenin, muhtemel nedenler için açık alanlar gibi daha zengin veri girişleri ve bu tek analiz için haklı gösterilemeyecek kadar maliyetli, son derece uyarlanmış model eğitimi gerektireceği sonucuna varıyor.
Gelecek Görevler İçin Neden Önemli
Büyük, yapılandırılmamış bir arıza raporu arşivini açık, katmanlı bir taksonomiye dönüştürerek bu çalışma NASA’ya donanım sorunlarının zaman içinde nasıl ve neden ortaya çıktığını izlemenin pratik bir yolunu sunuyor. Yöntemler henüz derin kök neden analizinde insan yargısının yerini alamasa da, çok büyük metin hacimlerini tarayıp sorunların nerede kümelendiğini ve hangi süreç türlerinin yer aldığını vurgulamada başarılılar. Bu tür erken uyarı ve yapılandırılmış içgörü, mühendislik ekiplerinin dikkatini hedeflemelerine, prosedürleri iyileştirmelerine ve daha dayanıklı sistemler tasarlamalarına yardımcı olabilir—Ay, Mars ve ötesine yapılan görevleri daha güvenli ve daha güvenilir kılmaya yönelik somut adımlar.
Atıf: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Anahtar kelimeler: uzay donanımı arızaları, doğal dil işleme, konu modelleme, mühendislik risk analizi, NASA uyumsuzluk raporları