Clear Sky Science · tr
Birleştirilmiş BERT ve GloVe gömme ile derin öğrenme kullanarak Urduca haberlerin doğruluğunu doğrulama
Urduca’da sahte haberleri tespit etmenin önemi
Pakistan’da ve dünya genelinde, artık daha çok insan haberlerini gazeteler veya televizyondan ziyade web siteleri ve sosyal medyadan alıyor. Bu değişim, özellikle dijital araçların sınırlı olduğu Urduca gibi ulusal dillerde yanlış hikâyelerin hızlıca yayılmasını her zamankinden daha kolay hâle getirdi. Bu çalışma, basit ama acil bir soruyla ilgileniyor: modern yapay zeka gerçek Urduca haberleri sahte olanlardan otomatik olarak ayırt edebilir mi; sıradan okuyucuların, gazetecilerin ve platformların yanıltıcı bilgiye karşı kendilerini korumasına yardımcı olabilir mi?
Çevrimiçi yanlış bilginin artan zorluğu
Yazarlar, uydurma başlıklar ve çarpıtılmış hikâyelerin kamuoyunu nasıl şekillendirebileceğini, siyasi gerilimleri nasıl körükleyebileceğini ve hatta insanların sağlıklarına ve maddi durumlarına zarar verebileceğini özetleyerek başlıyor. Birçok doğrulama sitesi ve araştırma projesi İngilizce’ye odaklanırken, Urduca gibi bölgesel diller sıklıkla geri planda kalıyor. Mevcut Urduca kaynaklar yalnızca birkaç bin haber maddesini içeriyor; birçok madde İngilizce’den çevrilmiş ve siyaset gibi dar konulara odaklanmış durumda. Bu, Pakistanlıların gerçekte okuduğu dilde şüpheli içeriği tanımak için güvenilir bilgisayar sistemleri eğitmeyi zorlaştırıyor.
Büyük bir Urduca haber derlemesi oluşturma
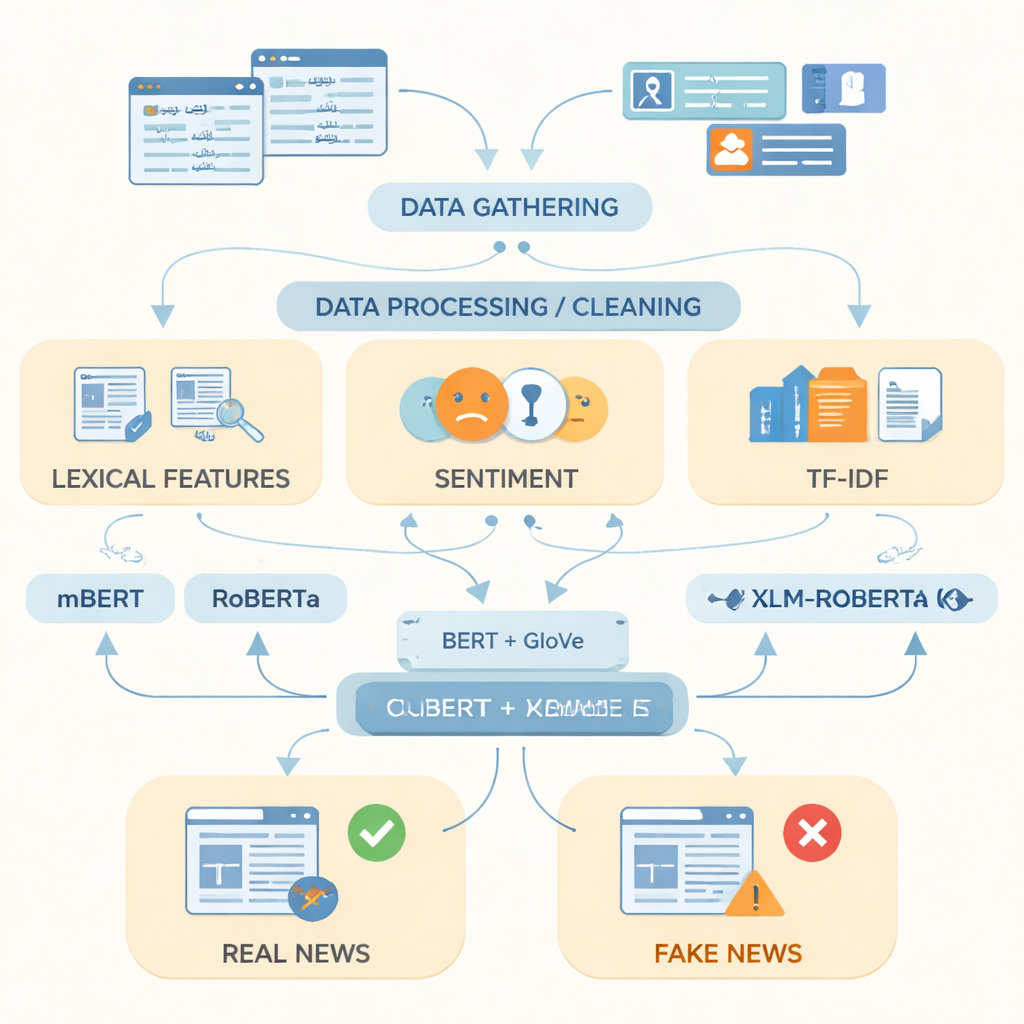
Bu eksikliği kapatmak için araştırmacılar, 2017–2023 yılları arasında saygın Pakistan haber siteleri ve çevrimiçi platformlardan toplanan 14.178 haber makalesini içeren, şimdiye kadarki en geniş Urduca sahte haber veri seti olduğunu belirttikleri bir koleksiyon derlediler. Haberler siyaset, sağlık, eğitim, iş, suç, spor ve çevre de dahil olmak üzere günlük yaşamın on beş farklı alanını kapsıyor. PolitiFact, FactCheck gibi doğrulama kaynakları ve özel haber API’leri kullanılarak, her öğe gerçek veya sahte olarak etiketlendi; kısmen doğru olanlar daha nüanslı raporlamayı yansıtmak için gerçek haberlerle aynı grupta toplandı. Ekip daha sonra metni kopyaların, web adreslerinin ve fazla noktalamanın kaldırılması, cümlelerin kelimelere ayrılması ve çok yaygın dolgu kelimelerinin temizlenmesi gibi işlemlerle düzenledi.
Bilgisayarlara sahte haberin nasıl göründüğünü öğretmek
Veriyi hazırladıktan sonra yazarlar, Urduca metni bir bilgisayar için en iyi nasıl temsil edeceklerini ele aldılar. Sık kullanılan kelimeler, dilin duygusal tonu ve terim sıklığı puanları gibi basit göstergeleri, iki güçlü kelime temsili tekniğiyle birleştirdiler. Bunlardan biri GloVe; bu yöntem her kelimeyi koleksiyon genelinde diğer kelimelerle birlikte görünme sıklığına göre sabit sayısal bir vektör olarak ele alıyor. Diğeri ise BERT tarzı modellere dayanıyor; bu yaklaşım her kelimeyi bulunduğu cümle bağlamında değerlendirip bağlama duyarlı bir anlam atıyor. Bu iki dil görüşünü tek, daha zengin bir temsilde birleştirerek sistem hem genel kalıpları hem de sahte ile gerçek hikâyeleri sıklıkla ayıran sözcük seçimlerindeki ince değişimleri yakalayabiliyor.
Gelişmiş dil modellerini teste sokmak
Araştırmacılar daha sonra bu temsilleri çok dilli metinler üzerinde eğitilmiş üç modern derin öğrenme modeline verdiler: mBERT, RoBERTa ve XLM-RoBERTa. Üçü de her makalenin gerçek mi yoksa sahte mi olduğunu tahmin etmek üzere Urduca veri seti üzerinde ince ayarlandı. Başarıları standart ölçütlerle değerlendirildi: doğruluk (doğru oldukları sıklık), kesinlik (bayraklanan sahtelerin gerçekten sahte olma oranı), duyarlılık (tüm sahte haberlerin ne kadarını yakaladıkları) ve kesinlik ile duyarlılığı dengeleyen F1-skoru. Her model güçlü performans gösterse de, birleştirilmiş BERT ve GloVe temsiliyle kullanılan XLM-RoBERTa en başarılı çıktı; test makalelerinin yaklaşık yüzde 96’sını doğru sınıflandırdı ve 0,956 F1-skoru elde ederek, daha küçük veri setleri veya daha basit yöntemler kullanan önceki Urduca sahte haber sistemlerinden daha iyi sonuç verdi.
Günlük okuyucular için anlamı
Uzman olmayanlar için mesaj net: yeterli kaliteli Urduca haber verisi ve doğru türde bir yapay zeka ile artık olası sahte hikâyeleri yüksek güvenilirlikle otomatik olarak işaretleyen araçlar geliştirmek mümkün. Çalışma, daha zengin dil temsillerinin ve çok dilli modellerin bilgisayarlara Urducanın farklı bölgelerde ve konu alanlarında nasıl yazıldığını çok daha iyi kavrama imkânı verdiğini gösteriyor. Mevcut çalışma yalnızca metne odaklanıyor ve henüz görselleri veya sosyal medya davranışlarını analiz etmiyor olsa da, diller ve medya türleri arasında çalışabilecek gelecekteki sistemler için sağlam bir temel oluşturuyor. Pratik açıdan, bu araştırma Pakistan’ı tarayıcı eklentileri, haber odası panoları veya insanların her gün kullandıkları dilde gerçeği kurgudan ayırmalarına yardımcı olacak sosyal medya filtreleri gibi uygulamalara bir adım daha yaklaştırıyor.
Atıf: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Anahtar kelimeler: sahte haber tespiti, Urduca, derin öğrenme, BERT ve GloVe, çevrimiçi yanlış bilgi