Clear Sky Science · tr
Heterojen CNN-dönüştürücü kodlaması ve çapraz boyutsal semantik füzyon ile uzun menzilli derinlik tahmininin iyileştirilmesi
Tek Gözle Derinliği Görmek
Modern robotlar, sürücüsüz otomobiller ve drone’lar genellikle nesnelerin ne kadar uzakta olduğunu anlamak için pahalı 3B sensörlere güvenir. Bu çalışma sıradan renkli kameraların —akıllı telefonlardaki gibi— çok daha ileri itilebileceğini gösteriyor: yazarlar bir bilgisayarın tek bir fotoğraftan derinliği çıkarması için yeni bir yol tasarlıyor ve sahnenin en zor kısmına odaklanıyorlar—uzak mesafe, burada engeller çok küçük, bulanık ve kolayca yanlış değerlendirilebiliyor.
Uzak Nesnelerin Neden Bu Kadar Zor Değerlendirildiği
Tek görüntüden derinlik, monoküler derinlik tahmini olarak adlandırılır ve bir tür görsel hiledir. Yakın nesneler birçok piksel kaplar ve keskin dokulara sahiptir, bu yüzden günümüz sinir ağları kısa ve orta mesafede zaten iyi performans gösterir. Ancak daha uzak mesafede arabalar birkaç piksele küçülür ve yol işaretleri perdeye veya puslu görünüme karışır. Standart konvolüsyonel sinir ağları ince yerel ayrıntıları fark etmekte iyidir ancak bir caddenin bütünü gibi geniş bağlamı kavramakta zorlanır. Daha yeni Dönüştürücü (Transformer) modeller global bağlamı iyi görür, ancak ince kenarlar ve dokular konusunda daha az hassastır. Sonuç olarak, her iki yöntem ailesi de güvenli navigasyonun en çok güvenilir tahminlere ihtiyaç duyduğu noktada —uzun mesafede— hata yapma eğilimindedir.
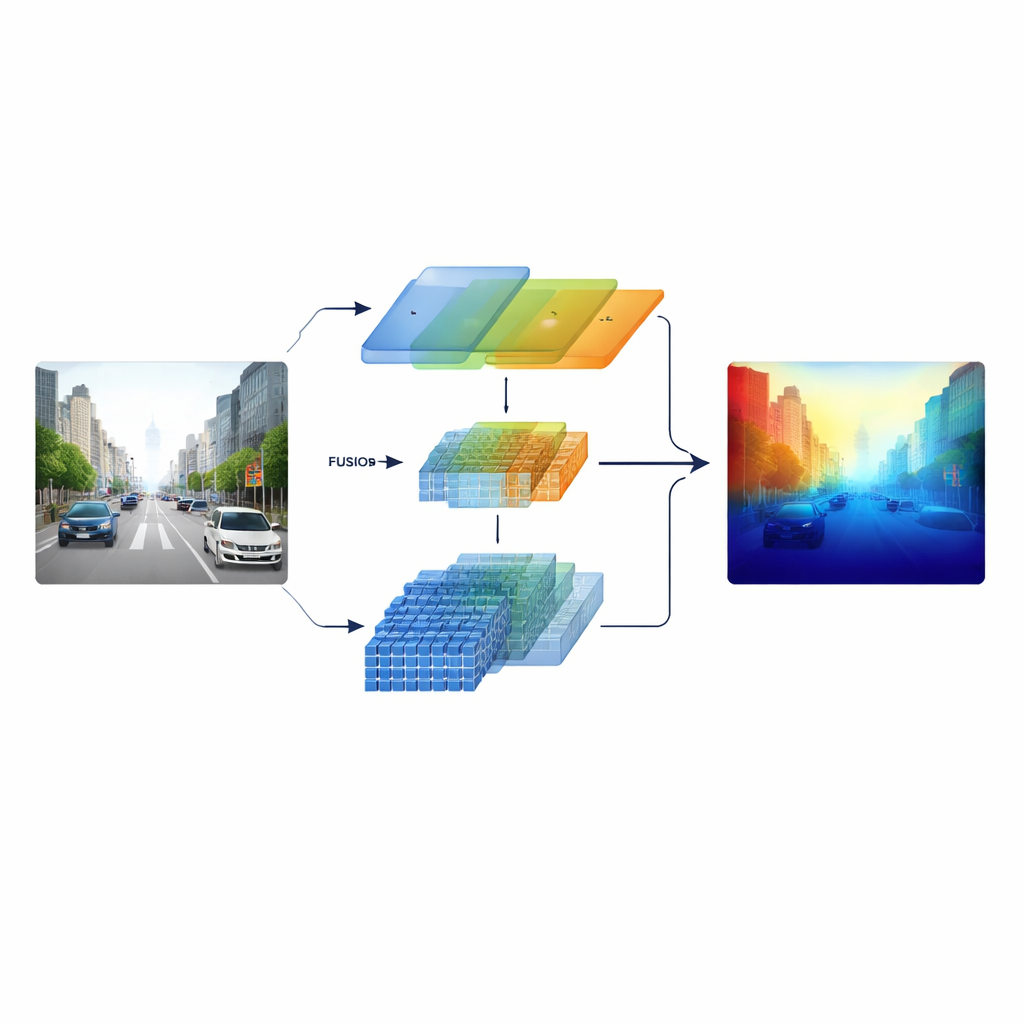
İki Görüş Biçimini Harmanlamak
Araştırmacılar bunu, iki farklı görsel işleme türünü paralel olarak çalıştıran "heterojen" bir kodlayıcı inşa ederek çözüyor. Bir dal, şerit işaretleri, direkler ve nesne kenarları gibi net yerel desenlerde uzmanlaşmış klasik ResNet tarzı bir konvolüsyonel ağa dayanıyor. Diğer dal ise Swin Transformer kullanıyor; bu model görüntü genelinde yol koridorunun düzeni veya uzak binaların silueti gibi uzun menzilli bağlantıları yakalamaya yönelik tasarlanmış. Bu iki görünümü sadece sonunda birleştirmek yerine, sistem her iki daldan çok ölçekli özellikleri tutuyor ve bunları dikkatle tasarlanmış bir füzyon aşamasına besliyor, böylece ince yapı ve geniş bağlam birbirini baştan sona bilgilendiriyor.
Kanallar, Uzay ve Ölçeklerin Ötesinde Geçiş
Modelin merkezinde, iki bilgi akışı için zeki bir toplantı odası gibi davranan Çapraz-boyutsal Semantik Füzyon (Cross-dimensional Semantic Fusion) modülü var. Önce hangi kanalların—öğrenilmiş farklı görsel desen türlerinin—daha fazla dikkat hak ettiğine karar veriyor; ayrıntılı dokular ile yüksek seviyeli sahne ipuçları arasındaki sinyalleri dengeliyor. Sonra yatay ve dikey yönlere ayrı ayrı bakıyor; bunlar yollar, binalar ve ağaçlarla dolu sahnelerde özellikle anlamlıdır, görüntü boyunca uzanan önemli yapıların vurgulanmasını sağlıyor. Nihayetinde sığ, ayrıntı açısından zengin özellikleri daha derin, daha soyut olanlarla birkaç ölçek boyunca karıştırıyor. Öğrenilebilir bir ağırlıklandırma adımı, ağın her bölge için hangi dala ne kadar güveneceğine karar vermesini mümkün kılıyor; böylece uzak, küçük nesneler yakın sahne tarafından boğulmuyor.
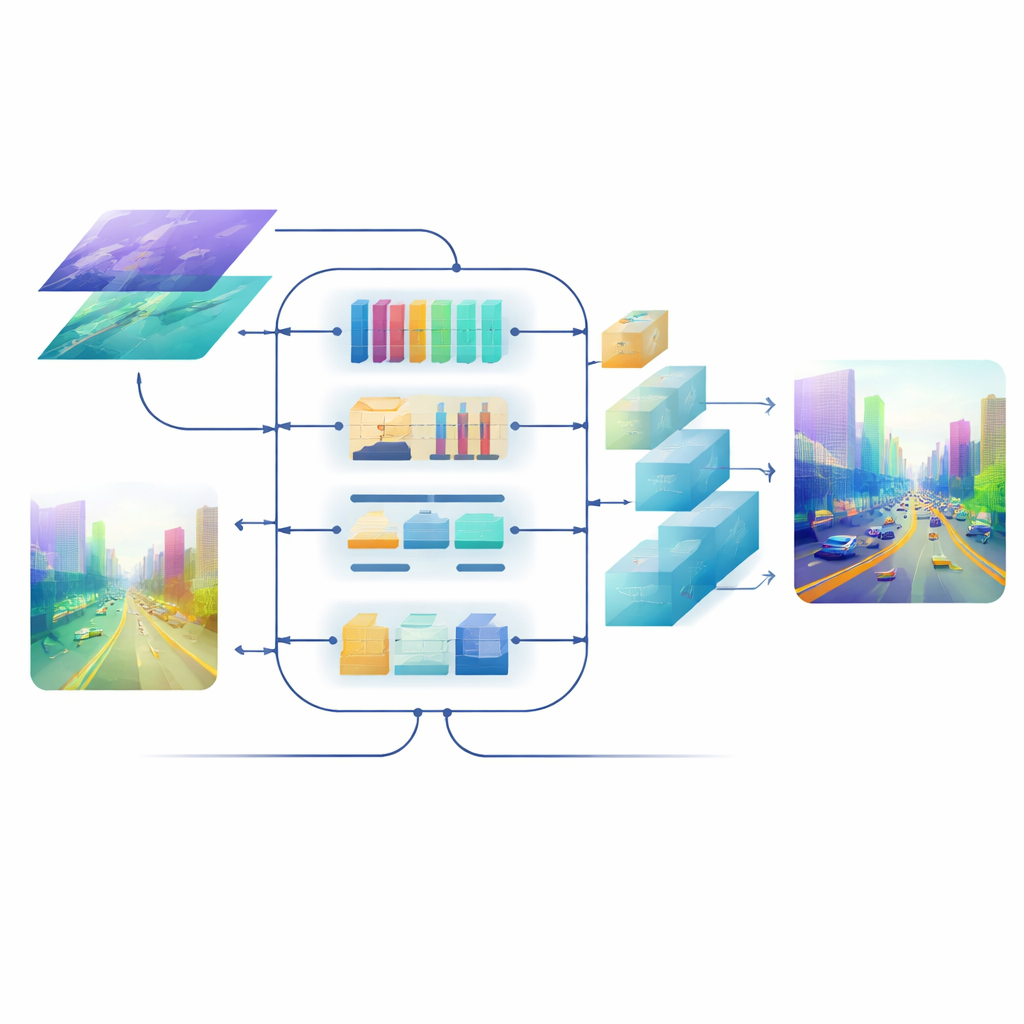
Nihai Görüntüyü Keskinleştirmek
İyi füzyonlanmış özellikler olsa bile, bunları tam çözünürlüklü bir derinlik haritasına geri dönüştürmek kenarları bulanıklaştırabilir ve ince yapıları silebilir. Bunu önlemek için ekip dikkat odaklı bir çözücü (decoder) tasarlıyor. Yukarı örnekleme blokları, haritayı bağlamı kaybetmeden büyütmek için hafif, derinlik-eğe konvolüsyonları kullanıyor ve çok ölçekli bir öz-dikkat (self-attention) mekanizması, dikkat hesaplamasını verimli kılmak için özellik kanallarını grupluyor. Bu adım her ölçekte derinlik tahminlerini inceleştirirken hesaplamayı da kontrol altında tutuyor. Sonuç, nesne kenarlarının —uzaktaki bir bisikletlinin dış hattı veya ranzanın basamakları gibi— keskin kaldığı, pürüzsüz ve tutarlı bir derinlik alanı oluyor.
Gerçek Dünyada Ne Kadar İyi Çalışıyor
Yöntem birkaç standart veri kümesinde test ediliyor. Sürüş sahnelerinin geniş bir koleksiyonu olan KITTI’de model çoğu yaygın ölçütte son derece iyi doğruluk elde ediyor ve kritik olarak, belirlenmiş uzun menzil bölgelerinde en düşük hatayı veriyor. Ayrıca nesnelerin etrafında daha temiz derinlik sınırları üretiyor. İç mekan sahnelerini içeren NYU Depth V2 ve SUN RGB-D kıyaslamalarında aynı model başarılı biçimde genelleme yaparak mobilyaları ve oda düzenlerini ikna edici 3B nokta bulutları halinde yeniden yapılandırıyor. Bileşenleri kaldırıp yer değiştiren sistematik testler (ablation çalışmaları), hibrit kodlayıcıdan füzyon modülüne ve çözücünün dikkat bloğuna kadar önerilen her parçaın performansı ölçülebilir şekilde artırdığını gösteriyor; bu özellikle uzak ve düşük doku alanlar için geçerli.
Günlük Teknoloji İçin Anlamı
Basitçe söylemek gerekirse, bu çalışma bir sinir ağına hem bir büyüteç hem de geniş açılı bir lensi aynı anda kullanmayı ve bunları akıllıca birleştirmeyi öğretiyor. Yerel ayrıntılar ile küresel sahne anlayışı arasındaki dengeyi daha iyi kurarak önerilen çerçeve, tek bir kameranın yolun veya bir odanın ötesindeki derinliği ne kadar iyi tahmin edebildiğini önemli ölçüde geliştiriyor. Bu da robotları, araçları ve dronları daha ucuz sensörlerle donatmayı daha pratik hale getirirken onlara yine de zengin bir 3B dünya algısı kazandırıyor—daha güvenli, daha yetenekli ve daha uygun maliyetli otonom sistemlere doğru atılmış önemli bir adım.
Atıf: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Anahtar kelimeler: monoküler derinlik tahmini, bilgisayarlı görü, dönüştürücü ve CNN füzyonu, otonom sürüş, 3B sahne yeniden yapılandırma