Clear Sky Science · tr
Çekirdek ortalama eşleştirmesi, mekansal dağılım kaymalarında risk tahminini geliştirir
Neden değişen haritalarda model riskini değerlendirmek önemli
Makine öğrenmesi modelleri türlerin nerede yaşayacağını, tümörlerin doku içindeki düzenini veya kirliliğin nasıl yayıldığını tahmin etmek için giderek daha fazla kullanılıyor. Ancak bu modellerin eğitildiği veriler sıklıkla çok belirli yerlerde toplanır—şehirler, hastaneler veya kolay erişilebilen saha alanlarının yakınındaki yoğun örneklemeler—oysa modeller çok daha geniş ve farklı bölgelerde uygulanır. Verinin geldiği yer ile tahminlerin yapıldığı yer arasındaki bu uyumsuzluk, modellerin gerçekte olduğundan daha güvenli ve daha doğru görünmesine yol açabilir. "Çekirdek ortalama eşleştirmesi, mekansal dağılım kaymalarında risk tahminini geliştirir" adlı makale sezgisel olarak basit bir soruyu soruyor: dünya eğitim verilerinizden farklı göründüğünde, modeliniz ne kadar yanlış olabilir ve bunu nasıl anlayabilirsiniz?
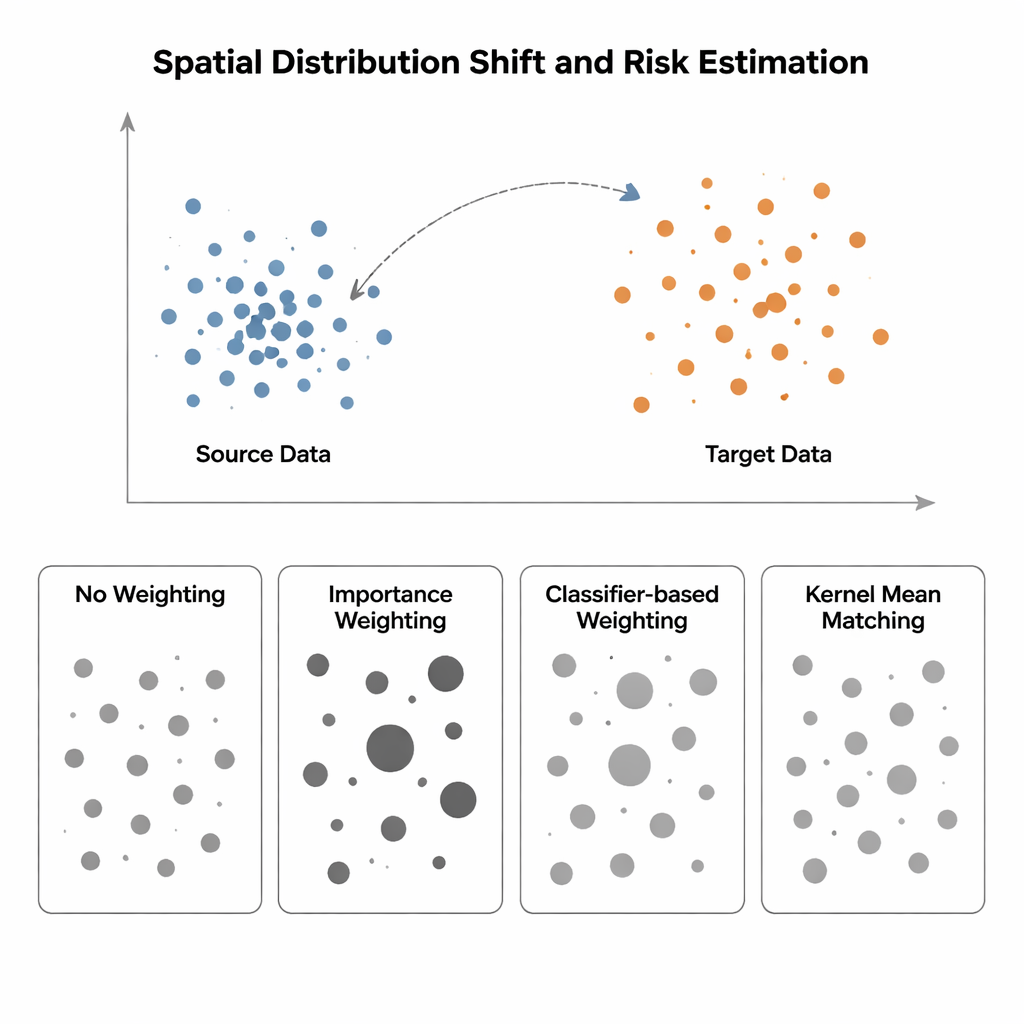
Eğitim ve test farklı dünyalarda olduğunda
İstatistikte bir modelin "riski", yeni ve görülmemiş veriler üzerindeki beklenen hatasıdır. Çapraz doğrulama veya rastgele bir test setini ayırma gibi standart değerlendirme yöntemleri, eğitim ve test verilerinin aynı dağılımdan geldiğini sessizce varsayar. Mekansal veriler bu varsayımı bozar. Çevresel gradyanlar, kümeleşmiş örnekleme ve değişen iklimler, bir modeli eğittiğimiz koşulların onu dağıttığımız koşullardan keskin şekilde farklı olabileceği anlamına gelir. Örneğin, tür gözlemleri genellikle yollara yakın yoğunlaşırken, koruma kararları uzak alanları ilgilendirir; tümör örnekleri doku içinde bir bölgeden alınabilir ama tahminlere başka yerlerde ihtiyaç duyulur. Bu tür durumlarda geleneksel risk tahminleri genellikle fazla iyimser olur ve bir modelin yeni konumlarda ne kadar kötü başarabileceğini gizler.
Eski araçlar mekansal önyargıyla mücadelede zorlanıyor
Çalışma, giriş dağılımı "kaynak" bölgeden (etiketlerin bilindiği) "hedef" bölgeye (etiketlerin kıt veya eksik olduğu) kaydığında model riskini tahmin etmek için dört yöntemi karşılaştırıyor. En basit yöntem olan Ağırlıksız (No Weighting), mevcut veriler üzerindeki ortalama hatayı ölçer ve kaynak ile hedefin benzer olduğunu varsayar—mekansal önyargınin olduğu durumlarda bu varsayım çöküyor. Önem Ağırlıklandırması (Importance Weighting) bunu, her bir kaynak örneğini hedefe göre ne kadar yaygın olduğuna göre ölçeklendirerek düzeltmeye çalışır. Teoride bu doğru riski geri getirir, ancak pratikte yüksek boyutlu olasılık yoğunluklarını tahmin etmeyi gerektirir. Kaynak veriler sıkı kümelenmiş ve hedef veriler daha yaygınsa—mekansal ekoloji veya tıbbi görüntülemede tipik bir durum—bu yoğunluk tahminleri güvensiz hale gelir ve birkaç örneğe aşırı büyük ağırlıklar verilir, bu da risk tahminini vahşice kararsız kılar. Kaynak ile hedef noktaları ayırt etmek için bir sınıflandırıcı eğitip bu olasılıkları ağırlıklara dönüştüren sınıflandırıcı tabanlı yaklaşımlar ise açıkça yoğunluk tahmini yapmaktan kaçınır ama genellikle sınıflandırma doğruluğunu, dağılım uyumunu değil optimize ettikleri için hatalı kalibre edilmiş riskler üretirler.
Farklı bir yol: dağılımları doğrudan eşleştirmek
Yazarlar, yoğunluk tahmini yapmayı tamamen atlayan bir yaklaşım olan Çekirdek Ortalama Eşleştirmesi'ni (KMM) savunuyor. Her noktanın kaynak ve hedef dağılımları altında ne kadar olası olduğunu hesaplamaya çalışmak yerine, KMM kaynak örnekler üzerinde öyle ağırlıklar arar ki bunların esnek bir çekirdek-tanımlı özellik uzayındaki ortalama "imzası" hedef örneklerin imzasıyla eşleşsin. Sezgisel olarak, her kaynak noktasının etkisini gerer veya sıkıştırır; böylece birlikte alındığında ağırlıklı kaynak bulutu hedef bulutu andırır. Bu ağırlıklar bulunduğunda, risk kaynak hata oranlarının ağırlıklı ortalaması olarak tahmin edilir. Tamamlayıcı bir araç olan Yerel Korelasyon Fonksiyonu ise verilerin mekânda ne kadar kümelendiğini nicelendirir; bu, yeniden ağırlıklandırmanın yardımcı olma olasılığının yüksek olduğu durumları belirtmek için bir tanı aracıdır.
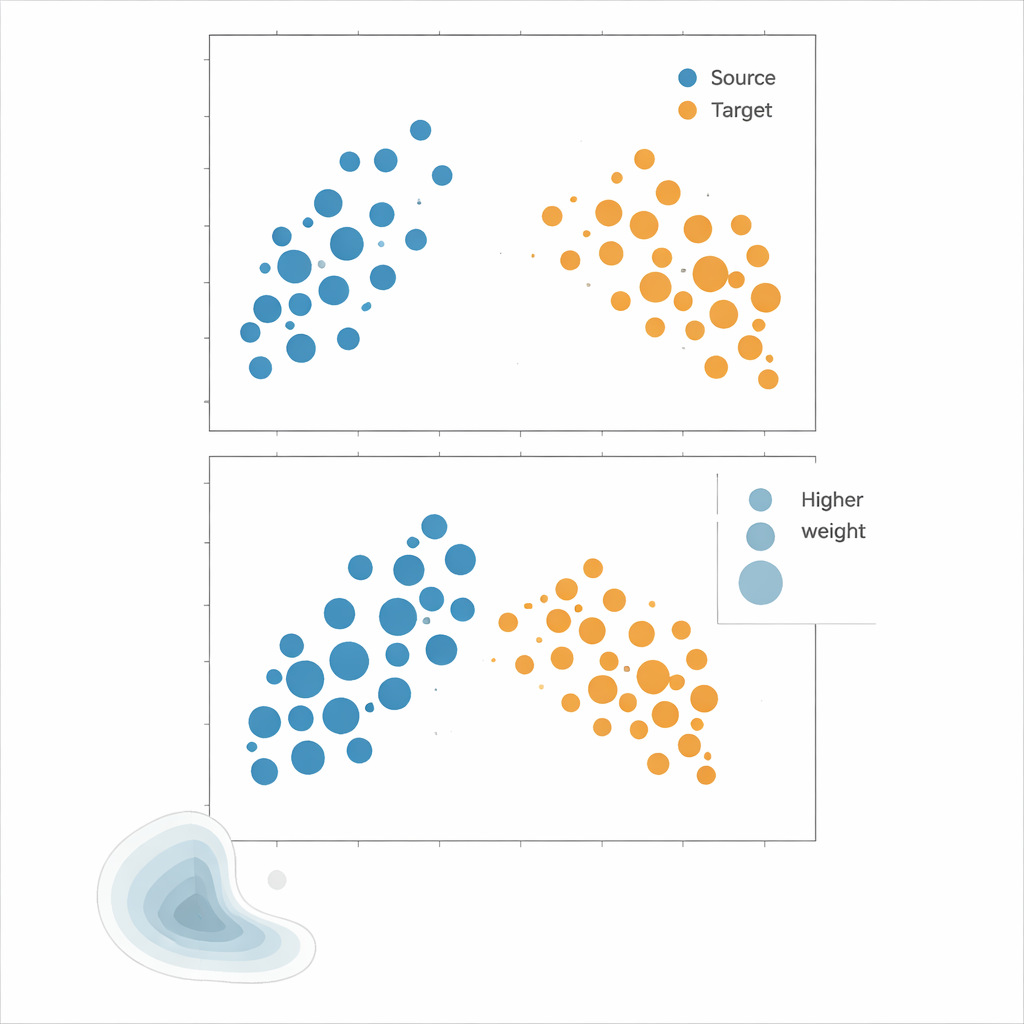
Yöntemleri teste koymak
Hangi stratejinin en iyi olduğunu görmek için yazarlar hem sentetik hem gerçek dünya verileri üzerinde kapsamlı deneyler yapıyor. Sentetik "manzaralar" yayılımı, şekli ve alan kapsaması hassas biçimde kontrol edilebilen Gauss kümelerinin karışımlarından inşa edilir; böylece alanın bir kısmını kırpma, özellikler arasındaki korelasyon desenlerini değiştirme veya sıkı kümelenmiş ile neredeyse uniform nokta desenleri arasında geçiş yapma gibi yapılandırılmış testler gerçekleştirmek mümkün olur. Gerçek veri setleri arasında iklim ve konumla tanımlanan Kuzey Avrupa bitki türü gözlemleri ve tümör içindeki bağışıklık hücrelerinin mekânsal düzenleri bulunur. Bu senaryoların tümünde modeller kümeleşmiş kaynak veriler üzerinde eğitilir ve daha az kümelenmiş hedef verilerde değerlendirilir, yaygın örnekleme önyarglarını taklit eder. Performans birkaç hata metriğiyle değerlendirilir ve her yöntemin tahmin ettiği riskin hedef üzerindeki gerçek hatayı ne kadar yakından izlediği üzerine odaklanılır.
Karışık, yüksek boyutlu alanlarda daha güvenilir risk
Hemen hemen tüm sentetik düzenekler ve gerçek veri setleri boyunca KMM en doğru ve stabil risk tahminlerini sunuyor. Ortalama mutlak yüzde hatayı alternatiflere göre yaklaşık %12 ile %87 arasında azaltıyor ve kritik olarak yüksek boyutlarda önem ağırlıklandırmasının başına gelen "ağırlık patlaması"ndan kaçınıyor. Zorlu tümör hücresi düzenlerinde, örneğin önem ağırlıklandırması birkaç bin yüzdeyi aşan hatalara yol açabilirken KMM yönetilebilir sınırlar içinde kalıyor. Sınıflandırıcı tabanlı yeniden ağırlıklandırma genellikle basit yöntemlerden daha iyi sonuç veriyor ama hâlâ KMM'nin gerisinde kalıyor; bu da onun ayrıştırma (discrimination) üzerine odaklanıp sadık bir dağılım eşleştirmesi yapmamasından kaynaklanıyor. Bu sonuçlar, verilerin kümelendiği, önyargılı ve yüksek boyutlu olduğu mekansal uygulamalar için KMM'nin model tahminlerine ne kadar güvenileceğini ölçmede ilkeli bir yol sunduğunu gösteriyor.
Gerçek dünya kararları için anlamı
Ekoloji, çevre bilimi veya biyomedikal alanda makine öğrenmesi kullanan uzman olmayanlar için mesaj açık: dağıtım bölgeniz verilerinizin geldiği yerden farklıysa standart test skorları tehlikeli biçimde yanıltıcı olabilir. Çekirdek Ortalama Eşleştirmesi, eğitim örneklerinin etkisini yeniden dengelleyerek istatistiksel olarak ilgi duyduğunuz yerleri veya dokuları andırmalarını sağlayan bir düzeltme yöntemi sunar. Çalışma, bu yaklaşımın şiddetli mekansal önyargı ve çok sayıda girdi değişkeni altında bile daha dürüst model hata tahminleri verdiğini gösteriyor. Pratikte bu, modeller arasında seçim yaparken daha güvenilir rehberlik ve tahminlerin güvenilir olduğu ile dikkatli olunması gereken yerler konusunda daha net bir tablo anlamına gelir.
Atıf: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Anahtar kelimeler: dağılım kayması, mekansal modelleme, çekirdek ortalama eşleştirmesi, model risk tahmini, ekolojik ve biyomedikal veriler