Clear Sky Science · tr
Akıllı öğrenme ortamları için öğrencilerin davranışlarının akıllı tanınması
Niçin daha akıllı sınıflar öğrencilerin ne yaptığını görmeli
Birçok sınıfta öğretmenler kimin derse uyum sağladığını, kimin kaybolduğunu ve kimin sessizce dikkat dışına çıktığını tahmin etmek zorundadır. Bu makale, yapay zekânın sıradan sınıf fotoğraflarından öğrencilerin okuma, yazma veya el kaldırma gibi ne yaptıklarını otomatik olarak nasıl tanıyabileceğini araştırıyor. Ham görüntüleri güvenilir sınıf etkinliği ölçülerine dönüştürerek sistem, zaman alıcı gözleme veya müdahaleci izlemeye dayanmadan öğretmenlere anlık katılım geri bildirimi sağlamayı amaçlıyor.
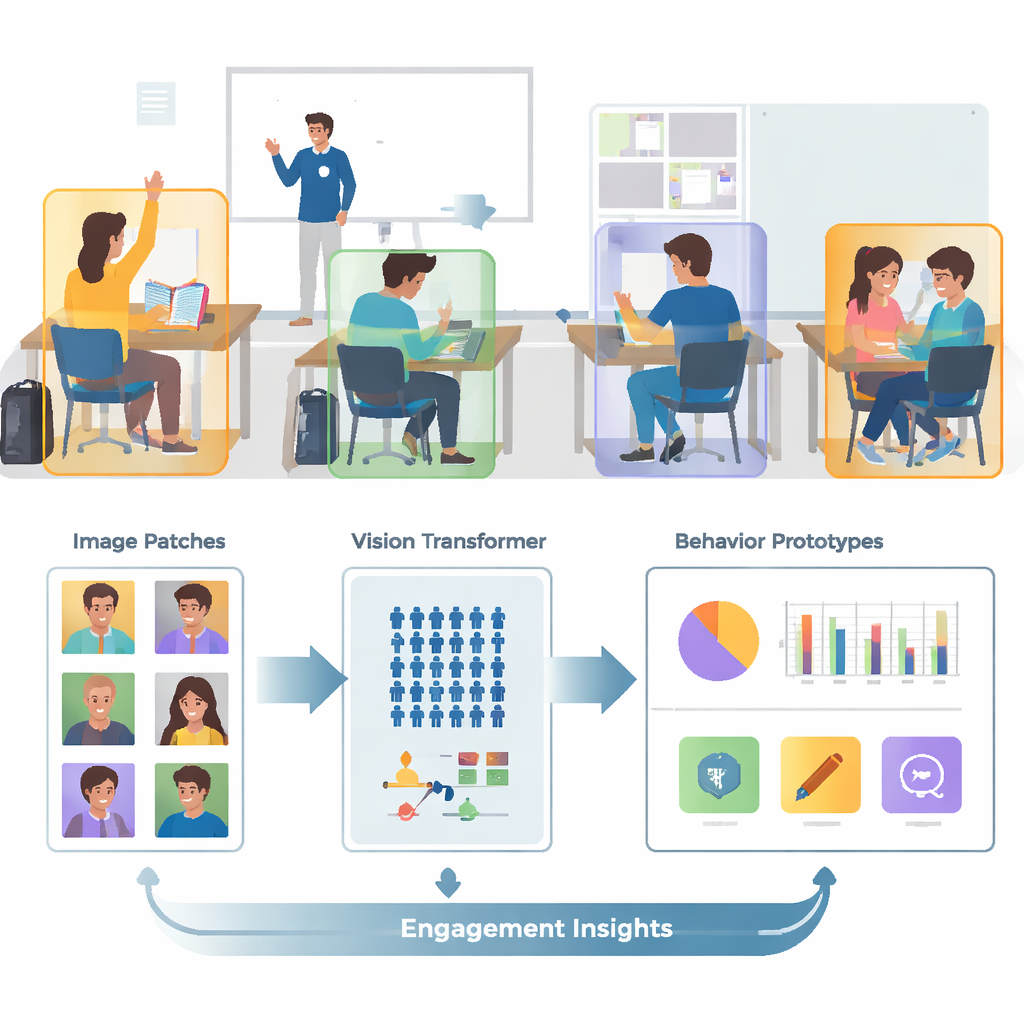
Dağınık fotoğraflardan odaklanmış kesitlere
Gerçek sınıflar kalabalık, hareketli ve görsel olarak şaşırtıcı olabilir. Tek bir görüntü onlarca öğrenciyi, örtüşen bedenleri ve duvarlar, ekranlar ve posterler gibi dikkat dağıtıcı arka plan öğelerini içerebilir. Yazarlar, el kaldırma, okuma, yazma, ayakta durma, konuşma veya kara tahtada etkileşim gibi belirli davranışlarla etiketlenmiş binlerce sınıf fotoğrafını içeren halka açık SCB‑05 görüntü koleksiyonuna dayanıyor. Sistemin tüm sahneleri bilgisayara vermek yerine önce her öğrenci veya öğretmen etrafındaki bölgeleri kırpmak için açıklama dosyalarını kullandığı bir ön işleme adımı var. Bu adım görsel dağınıklığın büyük kısmını kaldırır, böylece model duruş, el pozisyonu ve bir davranışı diğerinden ayıran diğer ipuçlarına odaklanabilir.
Yapay zekânın çok az örnekten yeni davranışları nasıl öğrendiği
Büyük engel, bazı sınıf davranışlarının veride yaygın (ör. okuma) iken bazılarının nadir (ör. sahnedeki kısa etkileşimler) olmasıdır. Her olası davranış için yeterli etiketli görüntü toplamak maliyetli ve gizlilik endişeleri doğurur. Bunu aşmak için yazarlar, modelin yalnızca birkaç örnekten yeni sınıfları tanıması üzere eğitildiği “az‑örnekle öğrenme” stratejisini kullanıyor. Eğitimi, her biri sadece birkaç davranış ve her davranış için birkaç örnek görüntü içeren çok sayıda küçük göreve göre düzenliyorlar. Her görev için sistem, o örneklerin içsel temsilini ortalayarak her davranış için basit bir “prototip” oluşturuyor. Yeni görüntüler daha sonra hangi prototipe en yakın olduklarına bakılarak sınıflandırılıyor; bu, veri az olsa bile modelin hızlı uyum sağlamasına imkân veriyor.
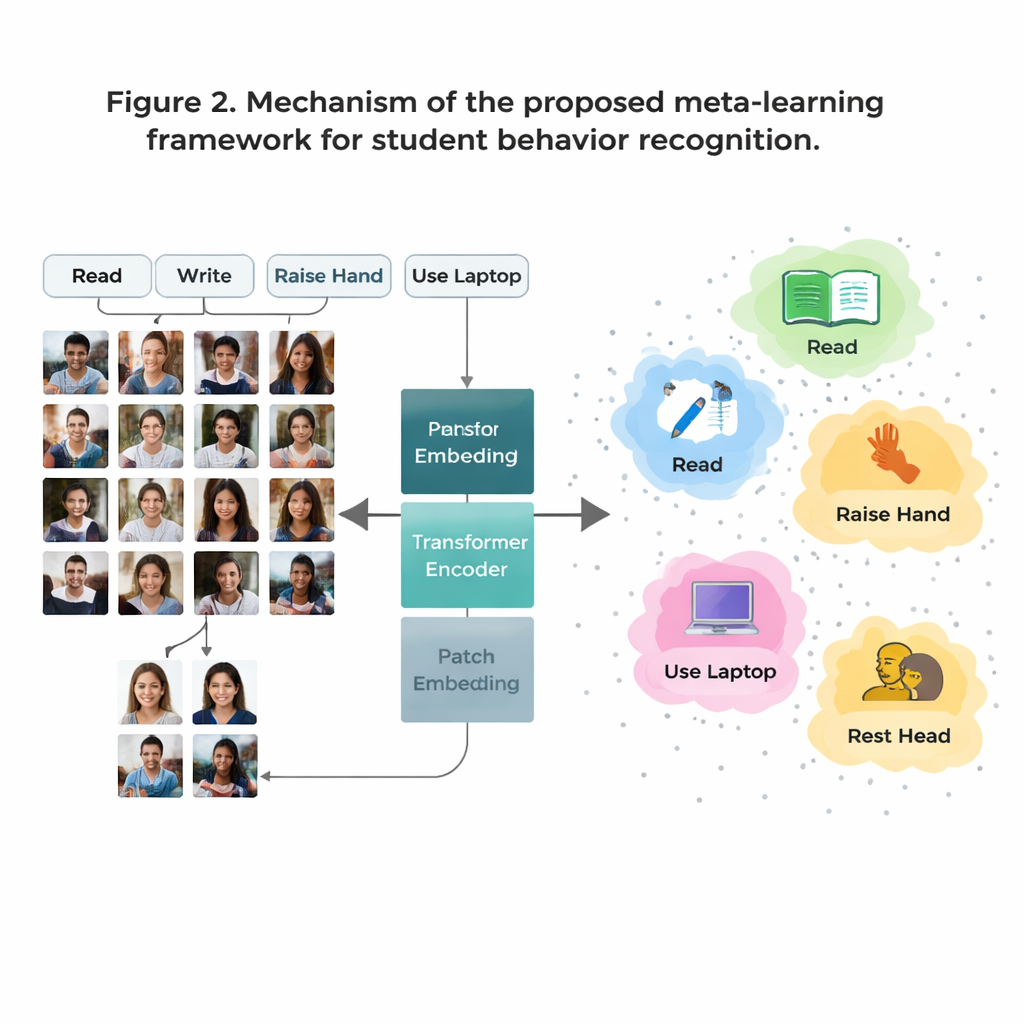
Sadece küçük ayrıntıları değil bütün sınıfı görmek
Konvolüsyonel sinir ağları olarak adlandırılan geleneksel görüntü sistemleri kenarlar veya dokular gibi küçük yerel desenlere odaklanma eğilimindedir. Bu, iki davranışın —ör. okuma ve yazma— yakından bakıldığında çok benzer görünmesi durumunda sınırlayıcı olabilir. Bu çalışmada bu eski ağlar, her görüntüyü yamalara bölen ve tüm yamaların birbirleriyle nasıl ilişkiliğini öğrenen bir Vision Transformer ile değiştiriliyor. Bu küresel bakış, sistemin ince duruş farklarını ve el kaldırma ile sınıfın önündeki öğretmen arasındaki ilişki gibi uzun menzilli ipuçlarını anlamasına yardımcı oluyor. Ekip ayrıca modeli aynı davranışın görüntülerini bir araya çekmeye ve birbirine benzeyen ama farklı davranışları ayırmaya zorlayarak geliştirdi; karıştırıcı “zor” örneklere ekstra ağırlık verildi. Bu, davranışların içsel haritasını daha temiz ve ayrılması daha kolay hale getiriyor.
Ne kadar iyi çalıştığı ve neden önemli olduğu
SCB‑05 kıyaslamasında önerilen yöntem yaklaşık %91 genel doğruluk ve dengesiz verileri hesaba katan daha zorlayıcı ölçümlerde güçlü puanlar elde ediyor. Okuma ve el kaldırma gibi yaygın davranışlar özellikle iyi tanınırken, kara tahta yazma gibi daha nadir davranışlar hâlâ daha zorlu kalıyor ama önceki sistemlere göre daha iyi performans gösteriyor. Modelin iç kümelerinin görsel incelemeleri, farklı davranışların sıkı, iyi ayrılmış gruplar oluşturduğunu gösteriyor; bu da yapay zekânın sınıf hareketlerinin ayırt edici “imzalarını” öğrendiğine işaret ediyor. Farklı kamera açıları ve düzenlere sahip başka bir sınıf veri kümesinde test edildiğinde performans sadece hafifçe düştü; bu da öğrenilen temsilin tek bir oda veya okula bağlı olmadığını düşündürüyor.
Öğretme ve öğrenme için bunun anlamı
Günlük ifadeyle, çalışma bilgisayarların her bir davranışın sadece birkaç örneğini görmüş olsalar bile durağan görüntülerden birçok önemli öğrenci davranışını güvenilir şekilde saptayabildiklerini gösteriyor. Bu tür sistemler öğretmenlerin yerini almak yerine kimlerin ilgili olduğunu, kimin sık sık yardım istediğini veya hangi etkinliklerin dikkati kaybettirdiğini izinsiz kimlik takibi yapmadan özetleyebilir. Gizlilik, adalet ve zaman içindeki video analizine yönelik daha fazla çalışma ile bu tür davranış‑farkındalıklı yapay zekâ, eğitimciler için daha duyarlı ve kapsayıcı öğrenme ortamları tasarlamada güçlü bir yardımcı olabilir.
Atıf: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Anahtar kelimeler: akıllı sınıf, öğrenci davranışı, bilgisayarlı görüntüleme, az örnekle öğrenme, görüş dönüştürücü (vision transformer)