Clear Sky Science · tr
Büyük dil modellerinin tıpta parametrik olmayan bilişsel tanısal modelleme kullanılarak ince ayrıntılı değerlendirilmesi
Gelecekteki doktor randevuları için bunun önemi
Konuşan ve yazan yapay zeka sistemleri olarak bilinen büyük dil modelleri, hızla araştırma laboratuvarlarından hastanelere kayıyor. Halihazırda doktorların karmaşık raporları okumasına, tedavi önerileri sunmasına ve tıbbi soruları yanıtlamasına yardımcı olabiliyorlar. Ancak bu sistemlerin çoğu testi, tek bir genel puan veriyor; tıpkı bir final sınavı notu gibi, bu tek puan tehlikeli kör noktaları gizleyebilir. Bu çalışma, bu puanların içini açıp modelin gerçekten hangi tıp alanlarını anladığını — ve nerelerde hâlâ hastaları riske atabileceğini — ortaya koymanın yeni bir yolunu gösteriyor.
Tek bir sınav puanının ötesine bakmak
Bugün tıbbi yapay zekânın çoğu, doktor lisanslama sınavlarını andıran sınavlarda kaç soruya doğru yanıt verdiğine göre değerlendiriliyor. Bu yaklaşım basit ama kaba. Bir model yüksek genel bir puan alırken kalp ritmi analizi veya karaciğer hastalıkları gibi hayati bir alanda hâlâ zayıf olabilir. Gerçek kliniklerde bu tür boşlukların hayat-kurtaran veya hayat-tehlikesi yaratıcı sonuçları olabilir. Yazarlar, tıpta yapay zekânın güvenli kullanımının tek, yanıltıcı olabilecek bir not vermek yerine ayrıntılı bir beceri profili çıkarabilen daha derin, ince ayrıntılı bir değerlendirme gerektirdiğini savunuyorlar.

Tıbbi bilgiyi test etmenin daha akıllı bir yolu
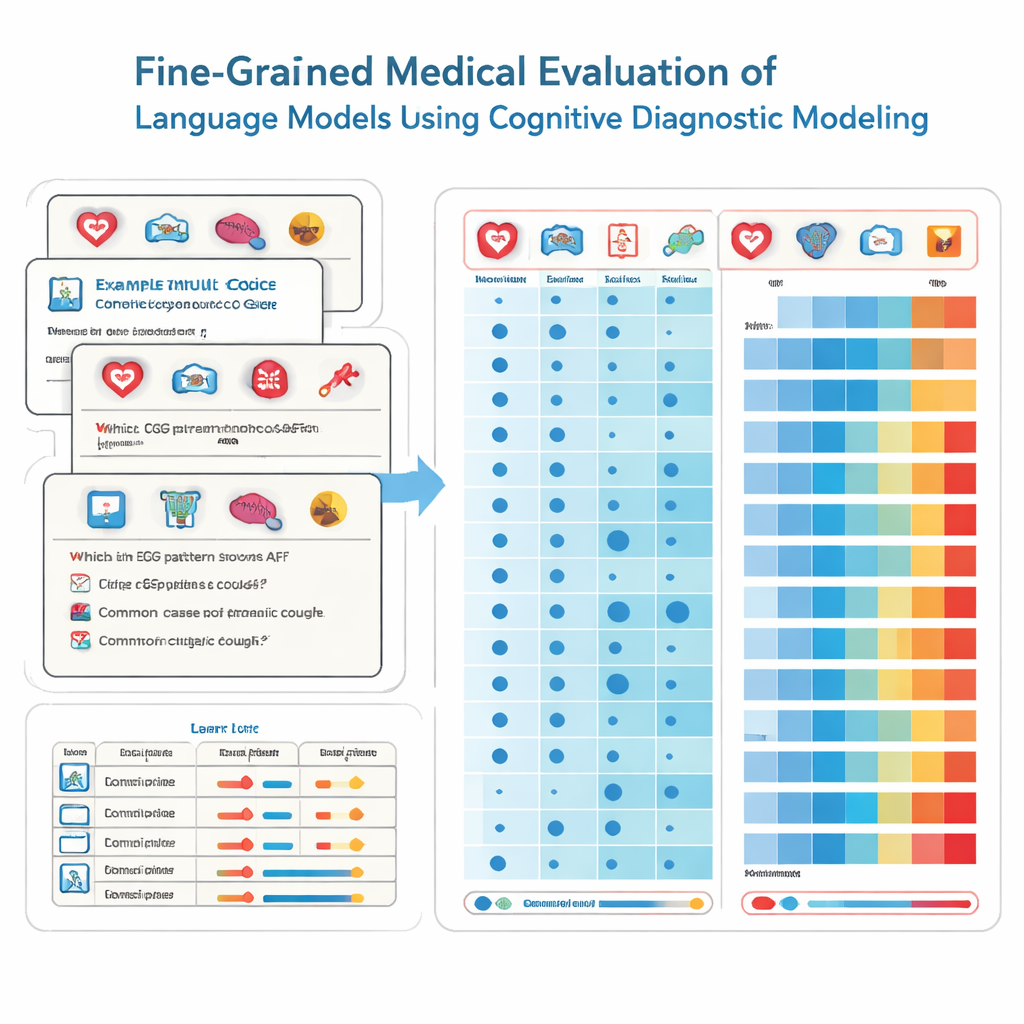
Bunu başarmak için araştırmacılar eğitim psikolojisinden bilişsel tanısal değerlendirme adlı araçları ödünç alıyor. Her sınav sorusunu aynı muğlak yeteneği ölçüyormuş gibi ele almak yerine bu yöntem tıbbi bilgiyi kardiyoloji, radyoloji veya acil bakım gibi belirli yapı taşlarına ayırıyor. Her çoktan seçmeli soru, hangi beceri karışımını gerektirdiğiyle etiketleniyor. Parametrik olmayan bir istatistiksel teknik kullanılarak ekip, bir modelin binlerce böyle soruya verdiği yanıtları ideal yanıt kalıplarıyla karşılaştırıyor. Buradan, bir modelin her temel beceriyi “kazanıp kazanmadığını” çıkarıyorlar; tıpkı detaylı bir karne gibi hangi konularda güçlü veya zayıf olduğunu gösteren bir rapor ortaya çıkıyor.
41 yapay zekâ modelini tıbbi sınava sokmak
Araştırma ekibi, hem ticari sistemleri hem de açık kaynak modellerini içeren 41 yaygın kullanılan dil modelini Çin ulusal tıp sınav veritabanından özenle seçilmiş 2.809 soruda test etti. Bu sorular 22 tıbbi alt alanı kapsıyor ve hekimlik lisans sınavına girecek öğrencilere yönelik olarak tasarlanmış. Her sorunun tek doğru yanıtı var ve uzmanlar tarafından hangi uzmanlıkları ilgilendirdiğini gösterecek şekilde etiketlenmiş. Tanısal yöntemlerini kullanarak araştırmacılar, her model için bu 22 tıbbi niteliğin kaçını etkin biçimde benimsediğini — sadece kaç soruyu tesadüfen doğru cevapladığını değil — tahmin ettiler.
Güçlü genel bilgi, ama keskin kör noktalar
Sonuçlar hem etkileyici hem de endişe verici. En iyi performans gösteren modeller, bazı önde gelen ticari sistemler gibi, çoğu soruyu doğru yanıtladı ve 22 tıbbi alandan 20’sinde yetkinlik gösterdi. Tüm modeller arasında performans birçok yaygın uzmanlıkta mükemmeldi; kardiyoloji, dermatoloji ve endokrinoloji de dahil olmak üzere 15 alanda tam yetkinlik elde edildi. Yine de ince ayrıntılı analiz bazı alanlarda çarpıcı boşlukları ortaya koydu. Radyoloji çok daha düşük yetkinlik oranlarıyla geride kaldı ve iki alt alan—EKG & hipertansiyon & lipitler ile karaciğer bozuklukları—hiçbir model tarafından benimsenmemişti. Önemli olarak, bazı daha küçük modeller aynı benimsenmiş becerilere daha büyük modellerle eşlik etti; bu, yalnızca model boyutunun geniş, güvenilir tıbbi bilgi sağlama garantisi olmadığını gösteriyor.
Doğru işi yapmak için doğru aracı seçmek
Bu ayrıntılı profiller önemli çünkü çok benzer genel puanlara sahip modellerin güçlü ve zayıf yön desenleri çok farklı olabilir. Bir sistem nörolojide güçlü ama farmakolojide zayıf olabilirken, bir başkası tam tersi deseni gösterebilir. Hastane yöneticileri için bu, yalnızca başlık sınav puanına veya parametre sayısına bakarak bir yapay zekâ asistanını güvenle seçemeyecekleri anlamına geliyor. Bunun yerine, her modeli belirli klinik görevlerle eşleştirmek ve modelin zayıf olduğu yüksek riskli alanlarda insan uzmanlarının yapay zekâ çıktısını çift denetleyeceği iş akışları tasarlamak için bu çalışmadaki gibi tanısal sonuçlara ihtiyaç var.
Hastalar ve klinisyenler için bunun anlamı
Düz anlatımla, çalışma tıbbi sınavlarda yüksek bir “not” almanın bir yapay zekâ sisteminin tıbbın tüm alanlarında güvenli kullanımını garanti etmediği sonucuna varıyor. Yeni yaklaşım, yapay zekânın kendisi için yapılan kapsamlı bir sağlık kontrolü gibi çalışıyor; hangi “organların”—bu durumda tıbbi uzmanlıkların—sağlıklı olduğunu ve hangilerinin dikkat gerektirdiğini ortaya koyuyor. EKG yorumu ve karaciğer hastalıkları gibi kritik alanlardaki gizli boşlukları açığa çıkararak yöntem, hastanelere, düzenleyicilere ve geliştiricilere pratik bir yol haritası sunuyor: modellerin yalnızca güçlü oldukları alanlarda kullanılmasını sağlamak, zayıflıkların sürdüğü yerlerde insanları işin içinde tutmak ve gelecekteki eğitimi en riskli kör noktalara odaklamak. Yazarlar, bu tür ince ayrıntılı değerlendirmenin yardımcı olmanın ötesinde; hasta bakımında yapay zekâya güvenmeden önce zorunlu olduğunu savunuyorlar.
Atıf: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Anahtar kelimeler: tıbbi yapay zeka, büyük dil modelleri, klinik güvenlik, model değerlendirmesi, tanısal test