Clear Sky Science · tr
Havadan görüntü sınıflandırması için dikkat mekanizmalı hibrit ResNet50-görsel transformer modeli
Neden gökyüzündeki daha akıllı gözler önemli?
Drone’lar ve uydulardan elde edilen havadan fotoğraflar artık afet müdahalesini, şehir planlamasını, tarımı ve hatta trafik kontrolünü yönlendiriyor. Ancak bilgisayarlara bu yukarıdan görülen karmaşık, yoğun görüntüleri anlamayı öğretmek hâlâ zor. Bu çalışma, binalar, arabalar, ağaçlar ve yollar gibi drone fotoğraflarındaki on nesne türünü önceki yöntemlerden daha yüksek doğrulukla tanımak için görüntüyü “görmenin” farklı yollarını birleştiren iki yeni yapay zeka modeli sunuyor. Yaklaşım, havadan otomatik izleme işlemlerini daha hızlı, daha güvenilir ve gerçek dünya uygulamalarında daha kolay kullanılabilir hale getirebilir.
Dünyaya yukarıdan bakmanın zorlukları
Havadan çekilmiş görüntüler, telefonla çektiğimiz sıradan fotoğraflardan farklıdır. Nesneler daha küçüktür, tuhaf açılarda görülebilir ve sık sık birbirine yakın yerleşmiştir. Bir arabanın ağacın arkasında kısmen gizlenmesi, dar bir patika veya heyelan sonrası yığın hâlindeki molozlar, insan için bile hızlıca fark edilmesi zor olabilir. Buna karşın hükümetler, acil müdahale ekipleri ve çevre kuruluşları, sel, orman yangını, kentsel genişleme ve altyapı hasarını izlemek için giderek daha fazla drone ve uydu görüntüsüne güveniyor. Yörüngedeki binlerce uydu ve hızla büyüyen bir havadan görüntü pazarıyla birlikte veri hacmi, insanların elle incelemesi için çok hızlı artıyor; bu da daha doğru ve verimli otomatik sınıflandırma ihtiyacını güçlendiriyor.
Makinelerin görmeyi öğrendiği iki yöntemin harmanlanması
Günümüzde en başarılı görüntü tanıma sistemlerinin çoğu derin öğrenmeye dayanıyor. Bir aile olan konvolüsyonel sinir ağları, kenarlar, dokular ve küçük şekiller gibi yerel desenleri yakalamada ustadır. Diğer ve daha yeni olan aile, görsel transformer’lar, görüntüyü yamalar dizisi gibi ele alır ve örneğin bir yolun, çatı kümesinin ve yakınlardaki açık bir tarlanın sahnede nasıl bir araya geldiği gibi uzun menzilli ilişkileri yakalamada özellikle etkilidir. Bu çalışma her ikisini birleştiriyor: iyi bilinen bir konvolüsyonel model olan ResNet-50 ve bir görsel transformer. Her ikisi aynı havadan görüntüyü işler ve ağın sahne hakkında öğrendiklerinin sayısal, sıkıştırılmış özetleri olan kendi özellik setlerini çıkarır. Bu iki bilgi akışı daha sonra birleştirilir ve hangi özelliklerin on hedef sınıf arasında karar vermede en önemli olduğunu öğrenen bir “dikkat” modülüne verilir.
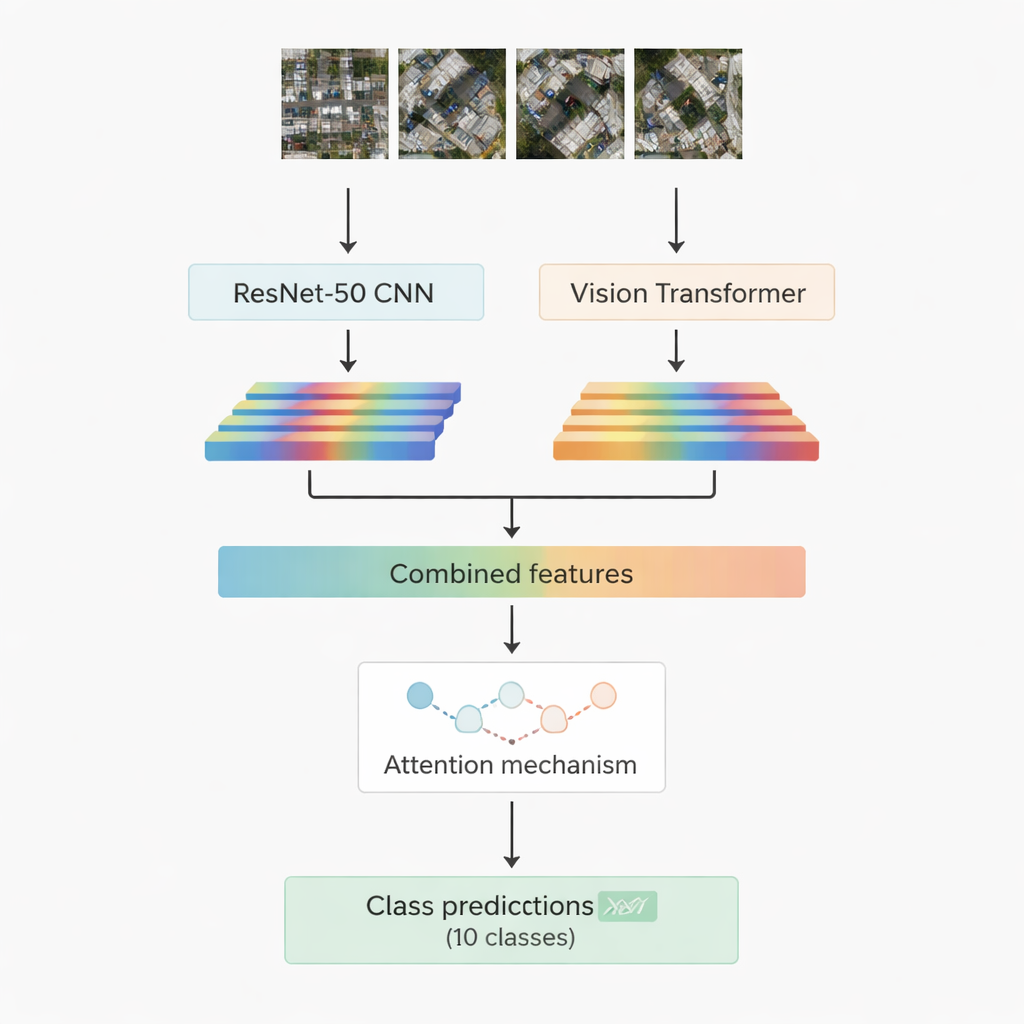
Önemli olana odaklanmak için iki dikkat stratejisi
Araştırmacılar hibrit sistemlerinin iki versiyonunu tasarlar ve test eder. Birinci versiyonda, ResNet-50 ve transformer’dan gelen özellikleri basitçe birleştirip çok başlı dikkat (multi-head attention) modülüne verirler. Bu mekanizma, her biri özelliklere biraz farklı bir açıdan bakan birçok küçük spot ışığı gibi düşünülebilir ve ardından bulgularını birleştirir. İkinci versiyonda ise çapraz-dikkat (cross-attention) kullanırlar: konvolüsyonel ağdan gelen özellikler, transformer özelliklerine nerelere bakılması gerektiğini soran bir sorgu (query) görevi görür ve böylece bir akış diğerine rehberlik eder. Her iki durumda da dikkat çıktısı, sonunda görüntü parçasını binalar, arabalar, moloz, patikalar, metal yollar, açık alanlar, gölgeler, tanklar, ağaçlar ve çatılar dahil on sınıftan birine atayan standart katmanlardan geçirilir.
Gerçek dünyadan drone görüntüleri üzerinde test
Modellerinin ne kadar iyi çalıştığını değerlendirmek için yazarlar Hindistan’ın Sikkim eyaletinden alınmış, yerden 60 ile 120 metre yükseklikte uçan bir drone tarafından toplanmış halka açık bir veri kümesini kullanır. Veriler nehirleri, ormanları, tepeleri ve yerleşim alanlarını kapsar ve her görüntünün on kategoriden birine düşmesi için küçük yamalara bölünmüştür. Veri kümesi dengelidir; her sınıf için eğitim ve test görüntülerinin sayısı eşittir, bu da adil bir test ortamı sağlar. Araştırmacılar her iki hibrit modeli de aynı koşullar altında eğitir ve ardından doğruluk, kesinlik (precision), duyarlılık (recall), F1-skoru, karışıklık matrisleri ve ROC eğrileri gibi yaygın kullanılan ölçütlerle performanslarını karşılaştırır. Ayrıca sonuçlarını literatürdeki birkaç tanınmış ağ ve daha yeni transformer tabanlı yöntemlerle kıyaslarlar.

Daha keskin sınıflandırma ve gerçek dünya potansiyeli
Her iki hibrit model de bu veri kümesinde önceki sistemlerden daha iyi performans gösterir ve çok başlı dikkat versiyonunun biraz önde olduğu sırasıyla %95,52 ve %95,80 genel doğruluklara ulaşır. Performansları on nesne türü arasında güçlü ve kararlı kalır ve ayrıntılı analizler zayıf görünen sınıfların bile yüksek oranlarda tanındığını gösterir. Bu, konvolüsyonel ağlar, görsel transformer’lar ve dikkat mekanizmalarını karıştırmanın karmaşık havadan sahneleri anlamada güçlü bir reçete olduğunu öne sürer. Gayri uzman bir okuyucu için çıkarılacak sonuç, bilgisayarların “Yollar nerede?” ya da “Hangi yamalar moloz veya bina gösteriyor?” gibi soruları büyük drone görüntü koleksiyonlarında yanıtlamada çok daha iyi hâle geldiğidir. Bu tür modeller geliştirilip yeni veri kümelerine genişletildikçe, hızlı ve güvenilir yukarıdan görüntü yorumuna dayanan daha akıllı afet müdahalesi, çevre izleme ve akıllı şehir hizmetlerinin temelini oluşturabilirler.
Atıf: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Anahtar kelimeler: havadan görüntü sınıflandırması, insansız hava aracı görüntüleri, derin öğrenme, görsel transformer, uzaktan algılama