Clear Sky Science · tr
Çok kollu bandit yaklaşımı kullanan bilgisayarlı uyarlanabilir testler için pekiştirmeli öğrenme çerçevesi
Dijital sınıf için daha akıllı sınavlar
Uzun, herkese aynı uygulanan bir sınava girmiş olan herkes bunun ne kadar sıkıcı ve haksız hissettirebileceğini bilir. Bazı sorular aşırı kolaydır, bazıları imkansızca zordur ve nihai puan gerçekten ne bildiğinizi yansıtmayabilir. Bu makale, kişilerin cevaplarına gerçek zamanlı olarak uyum sağlayan bilgisayar tabanlı sınavlar oluşturmanın yeni bir yolunu sunuyor. Modern yapay zekâdan ödünç alınan fikirlerle yazarlar, sınavları daha kısa, daha doğru ve her sınava girenin gerçek yeteneğine daha iyi uyumlu hale getirmeyi amaçlıyor.
Sabit sınavların yetersiz kalmasının nedeni
Geleneksel sınavlar her öğrenciye aynı soru setini verir. Bu, sınav hazırlamayı basit kılar ama bilgi israfına neden olur: güçlü öğrenciler birçok kolay maddeden geçmek zorunda kalır, mücadele eden öğrenciler ise hızla zorlanır. Bilgisayarlı uyarlanabilir test bunu, bir sonraki soruyu önceki yanıtlara göre seçerek düzeltmeye çalışır, ancak mevcut sistemlerin çoğu hâlâ onlarca yıllık istatistiksel modellere ve el yapımı kurallara dayanır. Bu eski yaklaşımlar karmaşık cevap desenlerini yakalamakta zorlanır ve genellikle modern, büyük ölçekli çevrimiçi ortamlardaki öğrenenler arasındaki geniş farklılıkları tam olarak hesaba katamaz.
Testlere modern yapay zekâyı getirmek
Yazarlar, uyarlanabilir sınavları baştan sona yönlendirmek için derin öğrenme ile pekiştirmeli öğrenmeyi birleştiren yeni bir çerçeve öneriyor. Sistem tekrarlanan döngüler halinde çalışır. Önce, tek boyutlu bir evrişimli sinir ağı (1D‑CNN) kişinin son cevaplarını, soruların zorluk seviyelerini ve diğer özet istatistikleri analiz eder. Bu veri akışından, geleneksel test teorilerinin yeteneği tanımladığına benzer şekilde ama doğrudan veriden öğrenilen normalleştirilmiş bir ölçekte kişinin mevcut beceri düzeyini temsil eden tek bir sayı üretir. Bu ağ, daha zor sorularda tutarlı başarılar veya daha kolay sorularda beklenmedik hatalar gibi ince desenleri tanımak üzere eğitilir. 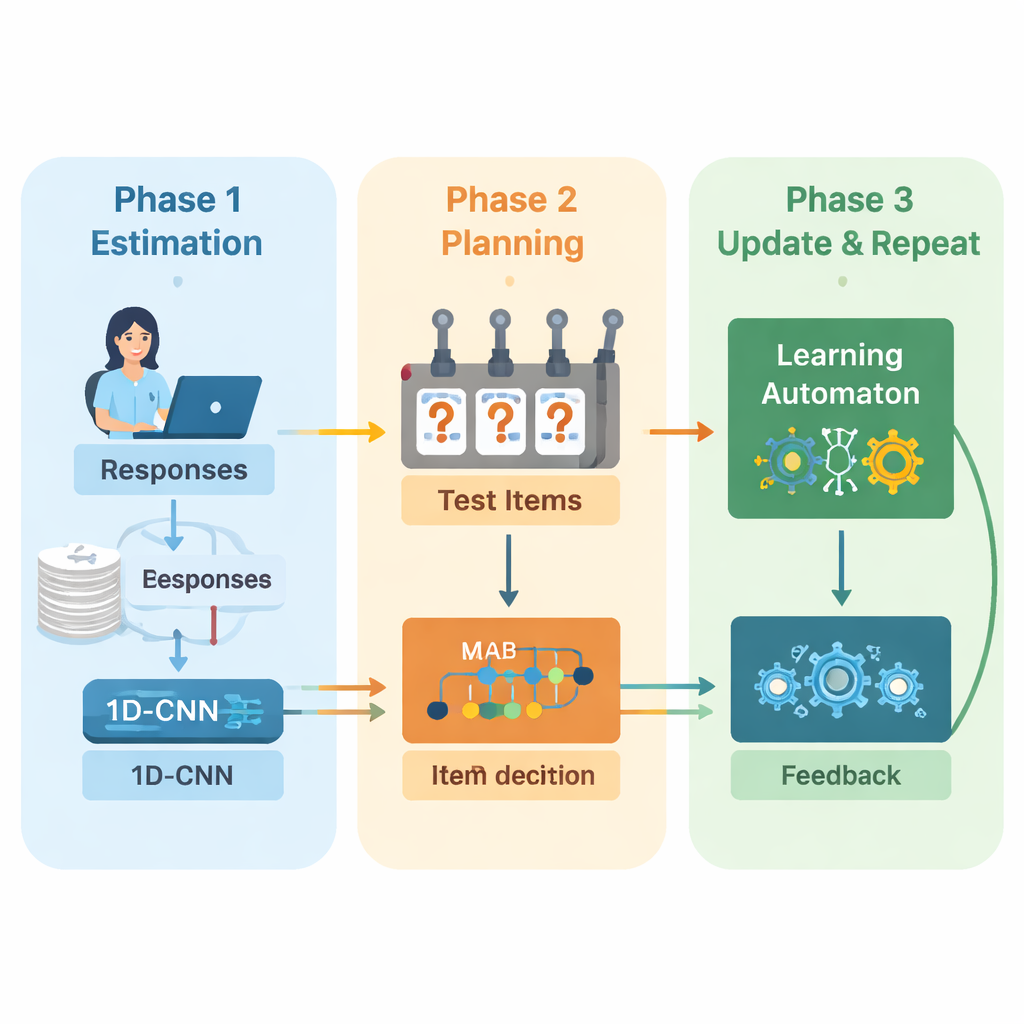
Doğru bir sonraki soruyu seçmek
Sistemin güncellenmiş bir yetenek tahmini olduğunda, bir sonraki ne sorulacağına karar vermesi gerekir. Burada yazarlar, her olası eylemin bir slot makinesindeki kolu çekmek gibi ele alındığı karar teorisinin klasik bir aracı olan "çok kollu bandit" stratejisini kullanır. Bu bağlamda, soru bankasındaki her soru bir kol olarak görülür. Algoritma, zorluk bakımından mevcut yetenek tahminiyle yaklaşık olarak eşleşen sorulara bakar ve ardından en bilgilendirici olması beklenenleri seçer. İki hedef arasında denge kurar: cevapların ne çok kolay ne de çok zor olmasını sağlamaya yönelik iyi bir zorluk eşleşmesi elde etmek ve testin önemli konuları göz ardı etmemesi için mümkün olduğunca farklı içerik alanlarını kapsamak. Bu iki hedefi harmanlayan bir ödül puanı seçim sürecini yönlendirir.
Kendi kararlarından öğrenmek
Sınav ilerledikçe gelişmeye devam etmek için sistem, öğrenme otomatonu adı verilen başka bir öğrenme bileşeni ekler. Bu modül, tahmin edilen yeteneğin turlar boyunca nasıl değiştiğini ve kişinin doğruluğunun iyileşip iyileşmediğini veya düşüp düşmediğini izler. Modelin yeteneğin artmasını, aynı kalmasını veya düşmesini bekleyip beklemediğini özetleyen küçük bir olasılık kümesini ayarlar. Bu olasılıklar daha sonra sonraki turda sinir ağına ekstra girdi olarak geri beslenir. Bu şekilde test motoru yalnızca öğrenciyi öğrenmekle kalmaz, aynı zamanda kendi geçmiş kararlarından da öğrenir—doğru tahminlere yol açan eğilimleri ödüllendirir ve işe yaramayan eğilimleri cezalandırır. 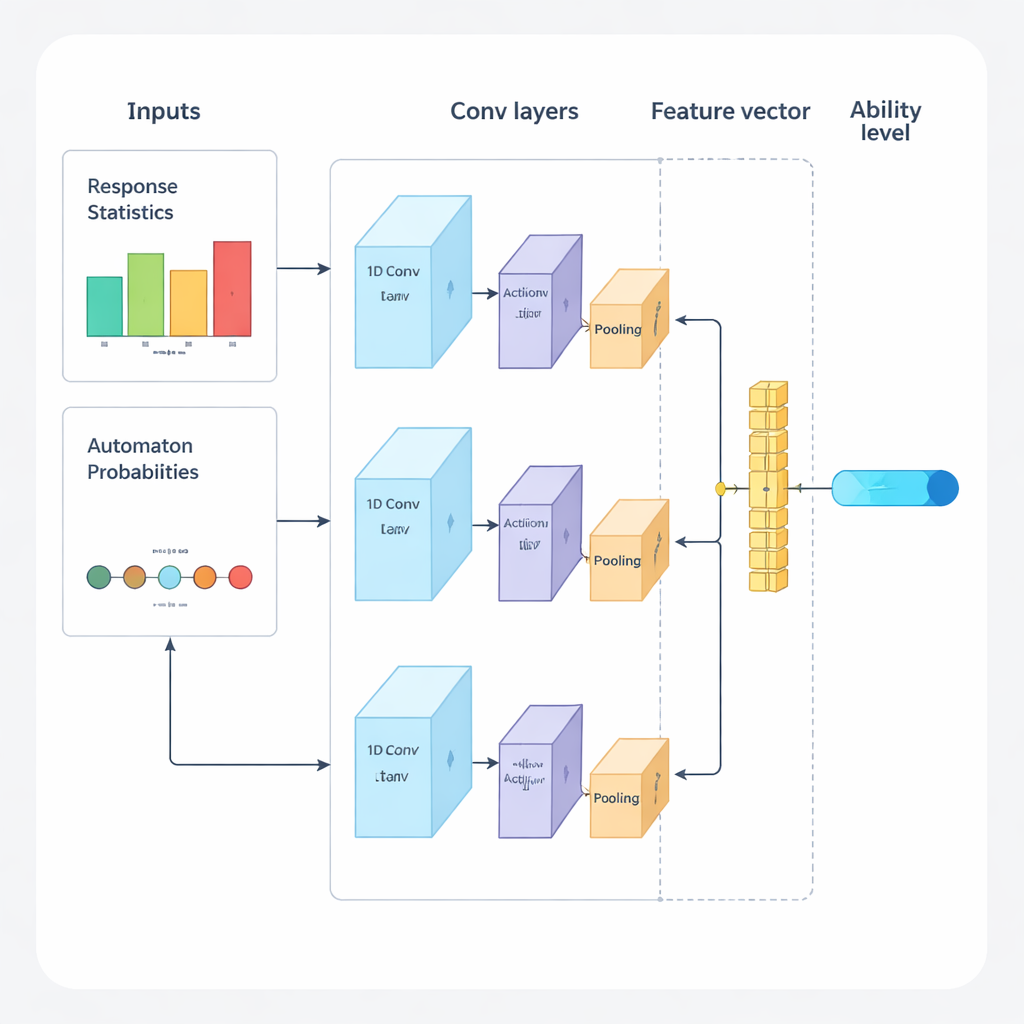
Pratikte ne kadar iyi çalışıyor?
Araştırmacılar çerçevelerini büyük, çokdilli bir sınav veri kümesi ve gerçek yetenek seviyeleri bilinen binlerce simüle edilmiş sınava giren üzerinde değerlendirdiler. Yaklaşımlarını birkaç önde gelen uyarlanabilir test yöntemiyle karşılaştırdılar. Bir dizi hata ve korelasyon ölçütü boyunca yeni sistem, daha az soru gerektirirken yetenek tahminlerinde daha doğru sonuçlar üretti. Hataları—karekök ortalama kare hata ve ortalama mutlak hata gibi yaygın istatistiklerle ölçülen—rakip yöntemlere göre belirgin şekilde daha düşüktü. Aynı zamanda soru kullanımını soru bankası genelinde daha eşit dağıttı ve belirli soruların aşırı maruz kalma ve sızma riskini azalttı.
Gelecekteki sınavlar için bunun anlamı
Günlük terimlerle bu çalışma, geleceğin bilgisayar tabanlı sınavlarının katı bir sınavdan çok kişiye özel bir öğretim oturumuna daha çok benzeyebileceğini öne sürüyor. Sorular her kişi için doğru zorluğa hızla odaklanır, önemli olan konuların tüm yelpazesini keşfeder ve sistem seviyeniz konusunda emin olduğunda—çoğu zaman bugünkü testlerden daha az maddeyle—sona erer. Yöntem hâlâ iyi eğitim verisine ve hesaplama gücüne bağlıdır ve şimdiye kadar tek bir veri kümesi üzerinde denenmiştir, ancak bireysel öğrenenlere doğal şekilde uyum sağlayan daha akıllı, daha adil ve daha verimli değerlendirmelere yönelik yeni bir nesle işaret ediyor.
Atıf: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Anahtar kelimeler: bilgisayarlı uyarlanabilir test, eğitsel değerlendirme, derin öğrenme, pekiştirmeli öğrenme, çok kollu bandit