Clear Sky Science · tr
Büyük ölçekli eğlence tesisleri için uzman karışımı ve çoklu model füzyonu kullanarak risk faktörü tespiti
Neden tema park güvenliği daha akıllı okuma gerektirir
Her yıl yüz milyonlarca insan roller coasterlara, düşme kulelerine ve dönen oyunlara biniyor; karmaşık makinelerin ve yoğun çalışan operatörlerin onları güvende tutacağına güveniyor. Sahne arkasında düzenleyiciler ve mühendisler büyük hacimlerde rapor, kaza kaydı ve kamu şikayeti üretiyor—ancak bu bilgilerin çoğu metin biçiminde olduğundan hızla taramak zordur. Bu çalışma, gelişmiş yapay zekânın bu belgeleri ölçekli olarak “okuyup”, tehlike desenlerini daha erken tespit ederek düzenleyicilere eğlence araçlarının nerede başarısız olma olasılığının yüksek olduğu konusunda daha net bir tablo sunup sunamayacağını araştırıyor.
Dağınık raporlardan birleşik bir risk resmine
Çin’de artık 25.000’den fazla büyük eğlence aracı ve yılda 700 milyondan fazla ziyaretçi bulunuyor. Genel güvenlik iyileşmelerine rağmen, nadir ama ciddi kazalar hâlâ meydana geliyor; çoğu kez teknik açıklamalarda veya kullanıcı şikayetlerinde gömülü erken uyarı işaretleri denetimler tarafından fark edilmemiş oluyor. Yazarlar, dönemsel manuel kontroller, uzman değerlendirmesi ve bakım kayıtlarına dayanan geleneksel denetimin bu hızlı tempolu ortam için çok yavaş ve öznel olduğunu savunuyor. Kaza raporları, kanun ve standartlar, denetim ve bakım kayıtları ile eğlence tesisleriyle ilgili çevrimiçi şikayetleri içeren büyük, gerçek dünya metin koleksiyonunu bir araya getiriyorlar. Dikkatli temizleme ve filtrelemeden sonra bu çok kaynaklı derleme, otomatik, veri odaklı bir risk izleme sisteminin hammaddesi haline geliyor. 
Bilgisayarlara risk dilini öğretmek
Bu karmaşık metinleri anlamlandırmak için araştırmacılar cümleleri anlamını yakalayan sayısal vektörlere çeviren modern dil modellerine dayanıyor. Öncelikle her bir metin parçasını 1.024 boyutlu uzaydaki bir nokta olarak temsil eden Çin dil modeli BGE’yi kullanıyorlar; buna ek olarak “bakım”, “denetim” ve “iyileştirme” gibi terimlere odaklanan 30 anahtar kelime tabanlı kompakt özellik seti de sağlanıyor. Bu çift bakış—derin semantik bağlam ile el ile seçilmiş risk ifadeleri—sistemin örneğin rutin kontroller ile ciddi arızalar arasındaki ince farkları ayırt etmesine yardımcı oluyor. Ekip ayrıca dil omurgasını değiştirmenin performansı iyileştirip iyileştirmediğini test etmek için başka bir çağdaş embedding modeli olan Qwen3 ile de denemeler yapıyor; uygulamada BGE bu güvenlik görevi için biraz daha iyi sonuç veriyor.
Gizli desenleri ve kilit zayıf noktaları bulmak
Metinleri somut risk kategorilerine sınıflandırmadan önce, yazarlar doğal gruplaşmaları ortaya çıkarmak için denetimsiz yöntemler kullanıyor. Gömütlemelere k-means kümeleme uyguluyor ve raporların birkaç açık konu kümesine ayrıldığını göstermek için UMAP adlı görselleştirme yöntemini kullanıyorlar. Ardından her düğümün bir güvenlikle ilişkili anahtar kelime olduğu ve bağlantıların güçlü eşzamanlılık ve semantik benzerliği gösterdiği bir anlamsal grafik kuruyorlar. Bir topluluk tespit algoritması bu düğümleri ekipman ve yapısal güvenlik, günlük işletme ve bakım, acil müdahale ile yönetim ve denetim gibi geniş temalara karşılık gelen kümelere ayırıyor. Bu ağ içinde “bakım”, “denetim” ve “sorumluluk” gibi bazı kelimeler kümeler arasında köprü görevi görerek birden çok şekilde kazaya yol açabilecek kesişen zayıflıkları vurguluyor. Bu yapıdan ekipmanların gerçek zamanlı izlenmesinden iş sorumluluklarının açıklığına kadar uzanan dört ana boyuta yayılan 31 temel risk faktörü çıkarılıyor. 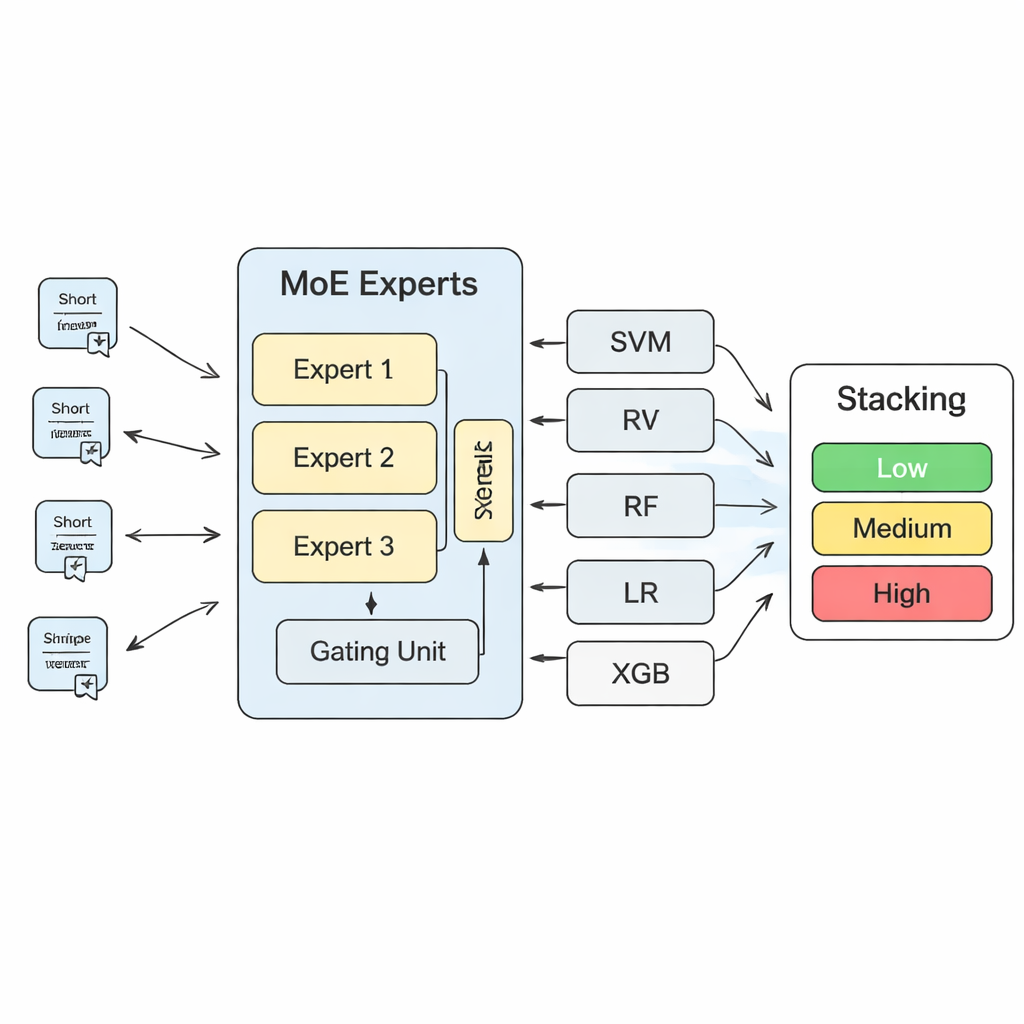
Birçok modeli tek, daha güçlü bir güvenlik hakemine karıştırmak
Bu içgörüleri somut risk tahminlerine dönüştürmek için çalışma katmanlı bir makine öğrenmesi sistemi kuruyor. Bunun merkezinde bir “uzman karışımı” (MoE) modeli yer alıyor: birkaç sinir ağı ya da uzman, her biri farklı risk desenlerine uzmanlaşmayı öğrenirken bir kapı bileşeni her yeni metin için hangi uzmanlara daha çok güvenileceğine karar veriyor. Bu MoE modelinin çıktıları daha sonra destek vektör makineleri, rastgele ormanlar, lojistik regresyon ve gradyan artırılmış ağaçlar gibi daha geleneksel algoritmaların tahminleriyle birleştiriliyor. Son bir “Stacking” katmanı—başka bir makine öğrenmesi modeli—tüm bu görüşlere nasıl ağırlık verileceğini öğrenerek nihai karara varıyor. Kapsamlı çapraz doğrulama yoluyla yazarlar, MoE katmanında üç uzmanın model kapasitesi ile kararlılık arasında en iyi dengeyi sağladığını buluyor.
Gerçek dünya denetimi için kazanımların anlamı
Tek bir modele kıyasla, MoE artı Stacking sistemi doğruluk, kesinlik, çağırma ve LogLoss adı verilen bir güvenilirlik ölçüsünde önemli iyileşmeler sağlıyor. Pratikte bu, büyük hacimli güvenlik metinlerini tararken daha az kaçırılan uyarı ve daha az yanlış alarm anlamına geliyor. Model sıradan bir iş istasyonunda çalıştırılabilir ve yeni denetim raporları veya şikayetler için hızlı risk değerlendirmeleri sunarak insan yargısının yerine değil, karar destek aracı olarak kullanılmaya uygundur. Yazarlar yaklaşımlarının eğlence araçlarının ötesinde asansörler veya teleferikler gibi diğer özel ekipmanlara da uyarlanabileceğini vurguluyor. Genel okuyucu için ana çıkarım şu: bilgisayarlara teknik belgeler, düzenlemeler ve günlük şikayetler arasındaki güvenlik dilini okumayı öğreterek düzenleyiciler tehlike desenlerini daha erken tespit edebilir, denetimleri daha zekice hedefleyebilir ve parkta geçirilen bir günü herkes için biraz daha güvenli hâle getirebilir.
Atıf: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Anahtar kelimeler: eğlence aracı güvenliği, risk metin analizi, makine öğrenmesi, uzman karışımı, kamu güvenliği izleme