Clear Sky Science · tr
Tamil el yazısı karakter tanıma için artık bağlantılara sahip derin inception sinir ağı
El yazısını dijital çağda korumak
Eski palmiye yaprağı el yazmalarından günlük notlara kadar Tamil’in yazılı mirasının büyük bir bölümü hâlâ kağıt üzerinde yaşıyor. Bu zengin el yazısı sayfalarını aranabilir dijital metne dönüştürmek, kültürü korumak, eğitimi desteklemek ve daha iyi dil teknolojileri geliştirmek için hayati öneme sahip. Bu makale, harflerin birbirine şaşırtıcı derecede benzer göründüğü durumlarda bile Tamil el yazısını neredeyse kusursuz doğrulukla okuyan TamHNet adlı yeni bir bilgisayarlı görme sistemini tanıtıyor.
Neden Tamil harfleri bilgisayarlar için zor
Tamil, 80 milyondan fazla kişi tarafından konuşuluyor ve ünlüler, ünsüzler ve ikisinin birçok kombinasyonunu içeren 247 karakterlik bir yazı sistemine sahiptir. Birçok harf yalnızca küçük kıvrımlar veya ek çizgilerle ayrılır ve yazıcılar her karakteri oluşturma konusunda büyük farklılıklar gösterir. எ/ஏ veya ஒ/ஓ gibi çiftler ilk bakışta neredeyse aynı görünebilir ve ல ile வ gibi karakterler kolayca karıştırılabilir. Önceki bilgisayar programları ve hatta modern makine öğrenimi sistemleri bu inceliklerle sık sık zorlanarak kelimelerin yanlış okunmasına ve belgelerin güvenilmez dijitalleştirilmesine yol açtı.
Gerçek dünya el yazısı veri seti oluşturmak
Sistemlerini gerçekçi koşullarda eğitmek ve test etmek için araştırmacılar, 1.000 üniversite öğrencisinden alınan el yazısı örneklerini kullanarak yeni bir Tamil İzole Karakter Veri Seti oluşturdular. Yapay veya bilgisayar tarafından üretilmiş görüntülere güvenmek yerine, 12 ünlü, 18 ünsüz ve 214 yaygın kombinasyonu kapsayan gerçek kalem-kağıt karakterleri topladılar. Ekip bu örnekleri dikkatle etiketledi ve veri setini diğer grupların yöntemleri karşılaştırabilmesi ve bu çalışmayı geliştirebilmesi için herkese açık hale getirdi. Yazıyı 247 karakterin tamamını yakalayan 104 temel sembole düzenleyerek, gerçek el yazısında görülen şekil çeşitliliğini korurken yinelenebilirliği azalttılar.
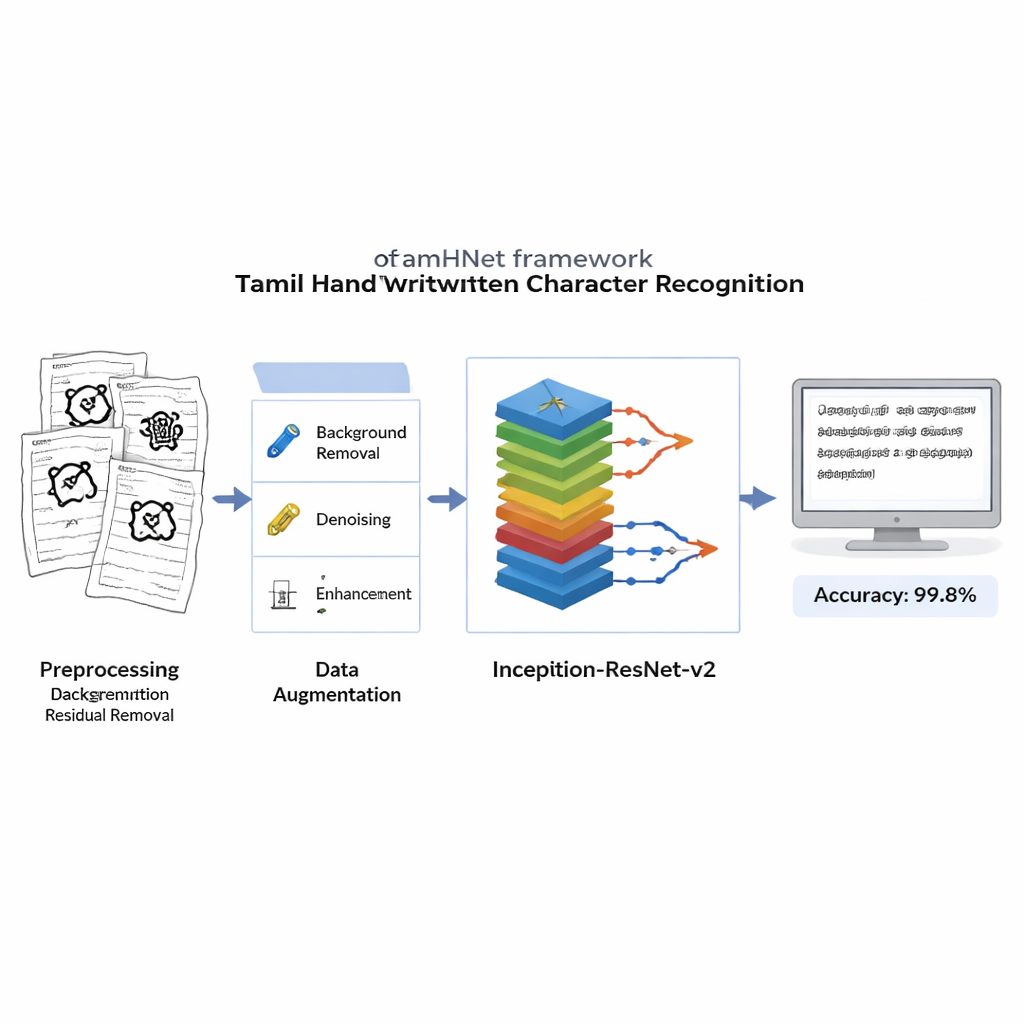
Görüntüleri temizlemek, genişletmek ve öğretmek
Herhangi bir öğrenme gerçekleşmeden önce, her taranmış görüntü gürültülü arka planları, lekeleri ve düzensiz aydınlatmayı kaldırmak için temizlenir; aynı zamanda her harfi tanımlayan ince çizgiler korunur. Görüntüler keskin siyah-beyaz hallere dönüştürülür ve bilgisayarın her örneği aynı şekilde görmesi için standart bir boyuta yeniden boyutlandırılır. Sistemi farklı yazı alışkanlıklarına karşı dayanıklı kılmak için yazarlar kontrollü bozulmalar kullanır: görüntüdeki önemli noktaları hafifçe kaydırır ve yumuşak deformasyon uygular, böylece insan gözü için hâlâ aynı harf gibi görünen yeni versiyonlar üretilir. Bu genişletilmiş eğitim seti, modelin harfleri eğik, sıkıştırılmış veya alışılmadık oranlarla yazılmış olsa bile tanımasına yardımcı olur.
İnce farkları öğrenen derin bir ağ
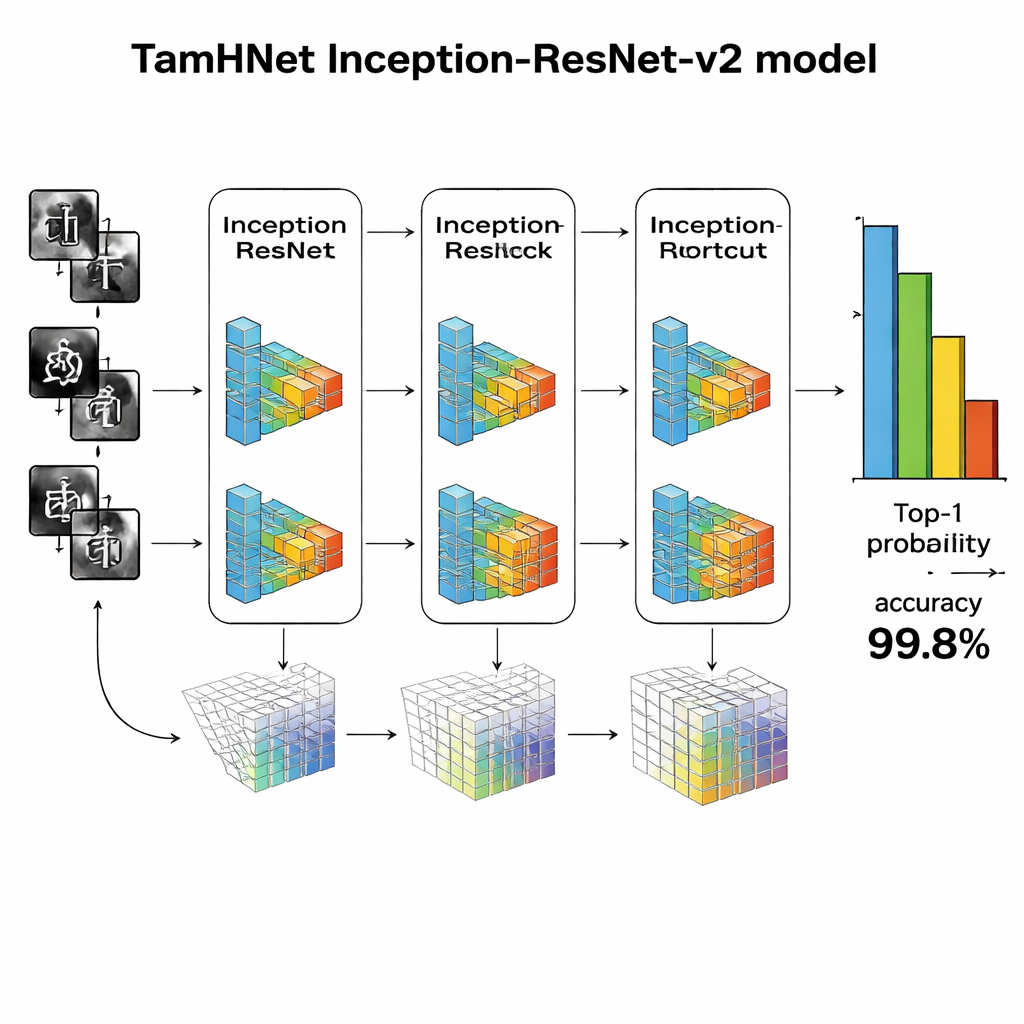
TamHNet’in kalbinde, başlangıçta genel nesne tanıma için tasarlanmış güçlü bir derin öğrenme mimarisi olan Inception-ResNet-v2 bulunur. Yazarlar bu ağı özellikle Tamil el yazısı için uyarlayıp ince ayar yaparlar. Model, her görüntüyü ham pikselleri kenarlar, eğriler ve karakter parçaları gibi daha yüksek düzey desenlere kademeli olarak dönüştüren birçok katmandan geçirir. Artık bağlantılar olarak bilinen özel kısayol bağlantılar, eğitimi dengeleyip ağın benzer harfler arasındaki küçük ama kritik farklara odaklanmasına yardımcı olur. Tüm iç ayarları aynı anda değiştirmek yerine ekip en faydalı katmanların kilidini seçici olarak açar ve bunları bu görev için ayarlar. Her parametrenin ne kadar hızlı değiştiğini otomatik olarak uyarlayan Adam adlı bir optimizasyon tekniği kullanırlar; bu sayede ağ karmaşık ve bazen dağınık el yazısından verimli şekilde öğrenir.
Sistem el yazısını ne kadar iyi okuyor
Araştırmacılar TamHNet’i yeni veri seti üzerinde tanıma kalitesinin standart ölçümlerini kullanarak değerlendirir. Sistem 104 karakter sınıfı genelinde yaklaşık %99.8 doğruluk elde ederek destek vektör makineleri, geleneksel konvolüsyonel ağlar ve diğer gelişmiş derin öğrenme tasarımlarına dayanan çok sayıda önceki yöntemi geride bırakır. Ayrıntılı testler, son derece benzer şekillere sahip harflerin bile çoğu durumda doğru şekilde ayırt edildiğini gösterir ve istatistiksel eğriler modelin nadiren bir karakteri başka bir karakterle karıştırdığını doğrular. Önceki çalışmalarla karşılaştırıldığında, bu Tamil el yazısı karakter tanıma için güvenilirlikte açık bir ilerlemeyi temsil eder.
Okuyucular ve arşivler için bunun anlamı
Uzman olmayanlar için ana çıkarım, bilgisayarların Tamil el yazısını okumada çarpıcı şekilde daha iyi hale geldiğidir. TamHNet gibi bir sistem, defter yığınlarını, tarihsel el yazmalarını ve el yazısı formları aranabilir dijital metne dönüştüren araçları insan düzeltmesi gereksinimini en aza indirerek güçlendirebilir. Mevcut model henüz bazı nokta tabanlı sembolleri ve eski yazı varyantlarını işlemezken, yazarlar onu antik yazı stillerine de genişletme planlarını özetliyor. Pratik açıdan bu araştırma, Tamil belgelerinin büyük ölçekli, doğru dijitalleştirilmesine bizi yaklaştırıyor; kültürel mirası korumaya yardımcı oluyor ve yazılı bilgiyi gelecek nesiller için daha erişilebilir kılıyor.
Atıf: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Anahtar kelimeler: Tamil el yazısı karakter tanıma, optik karakter tanıma, derin öğrenme, Inception-ResNet, dijital koruma