Clear Sky Science · tr
Sıfır atış hedef tanıma için nesne yönlendirmeli kontrastif dil-görüntü ön eğitimi
Kalabalık Gökyüzü ve Denizler için Daha Akıllı Gözler
Modern güvenlik ve afet müdahale sistemleri, uçakları, gemileri ve diğer kritik nesneleri tespit etmek için gökte ve denizdeki kameralara dayanır. Ancak bir savaş uçağını bir yolcu uçağından veya bir savaş gemisini bir yük gemisinden ayırt etmeyi bilgisayarlara öğretmek, sahneler karmaşık olduğunda, veri kıt olduğunda ve yeni ekipman modelleri sürekli ortaya çıktığında şaşırtıcı derecede zordur. Bu makale, OG‑CLIP adlı yeni bir yapay zeka sistemi tanıtıyor; bu sistem, geniş ölçekli ön bilgiyi önemli nesnelere daha keskin görsel odakla birleştirerek açıkça eğitilmediği askeri ve sivil hedefleri tanımayı amaçlıyor.
Neden Geleneksel Yapay Zeka Hedefi Kaçırıyor
Çoğu görüntü tanıma sistemi büyük etiketli resim koleksiyonlarından öğrenir: her görüntü “kedi” veya “araba” gibi sabit bir kategori listesiyle ilişkilendirilir. Bu yaklaşım, verilerin hassas olduğu, etiketlemenin uzmanlık gerektirdiği ve ekipman çeşitliliğinin çok yüksek olduğu savunma ve uzaktan algılama gibi özel alanlarda çöker. CLIP gibi daha yeni görsel‑dil modelleri, görüntüleri webden toplanmış kısa metin altyazılarıyla eşleştirerek kelimelerle tanımlanan yeni kavramları tanımalarına olanak tanır. Buna rağmen askeri görüntülemede bu modeller hâlâ zorlanır: altyazılar genellikle belirsizdir, bulutlar ve dalgalar gibi arka planlar piksellerin çoğunu kaplar ve içsel özellikler küçük dronlardan güçlü sunuculara kadar her donanımda verimli çalışacak kadar esnek değildir. OG‑CLIP bu üç sorunu doğrudan ele alır.
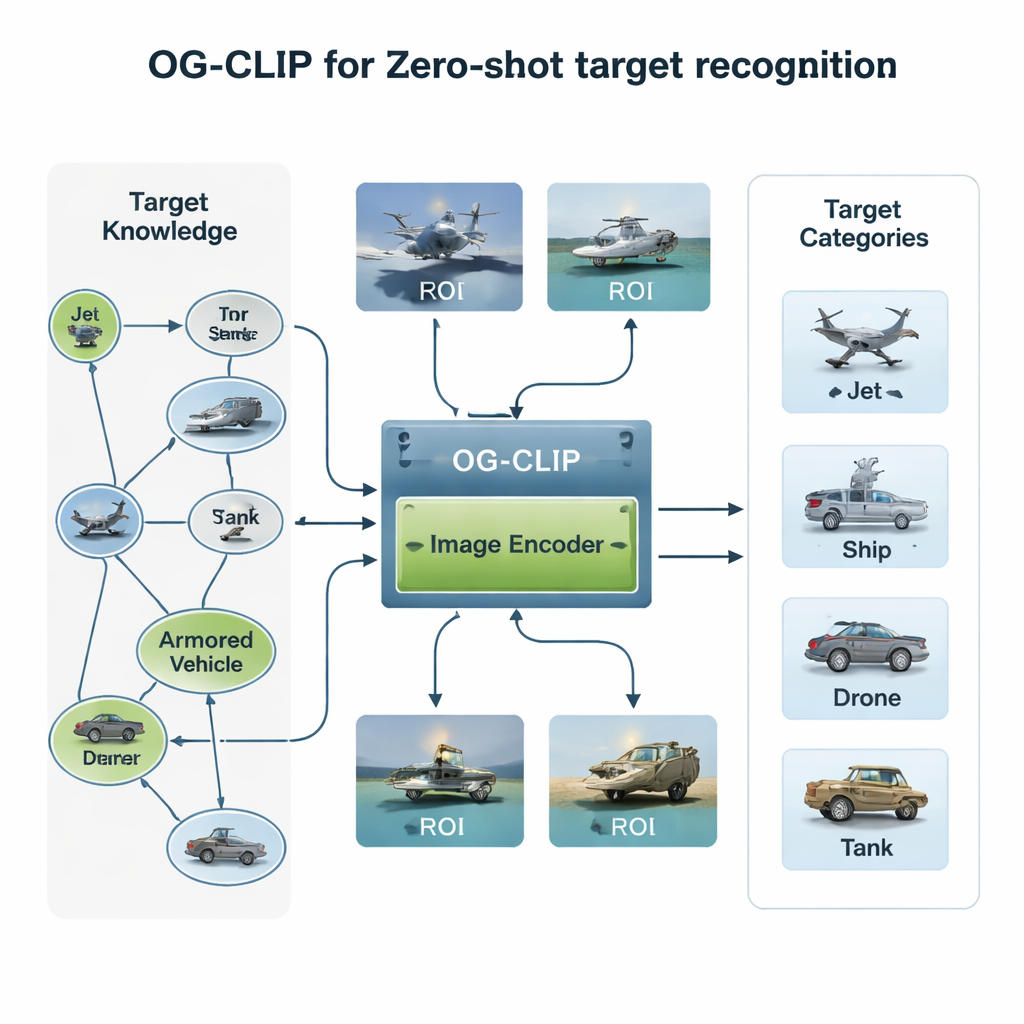
Bilgi Zengini Bir Eğitim Dünyası Kurmak
OG‑CLIP’in ilk bileşeni özenle tasarlanmış bir eğitim evrenidir. Yazarlar, avcı ve bombardıman uçaklarından savaş gemilerine ve sivil uçaklara kadar uzanan 5.000 tür hedeften oluşan bir veritabanı derlediler ve bunları ayrıntılı bir bilgi grafiğinde düzenlediler. Her giriş, menzil, ağırlık ve silah konfigürasyonu gibi yapılandırılmış gerçekleri içerir; bu bilgiler kamuya açık savunma referansları, ansiklopediler ve teknik dokümanlardan alınmıştır. Ardından yaklaşık bir milyon görüntü topladılar; kaynaklar arasında kamu veri kümeleri, web aramaları, eski kurum içi arşivler ve oyun motorlarından üretilmiş simüle sahneler bile vardı. Verilerin güvenilirliğini sağlamak için mevcut bir model kullanılarak görüntüler kümelendi, aykırı örnekler tespit edildi, uzman incelemesi yapıldı ve hatalı etiketler filtrelendi. Son olarak, bilgi grafiğini her görüntü için zengin, doğal dil betimlemelerine dönüştürmek üzere gelişmiş dil‑görsel araçlar kullandılar; böylece sistem sadece “bu bir jet” öğrenmiyor, aynı zamanda “kanat uçları yukarı doğru kıvrımlı tek koridorlu bir uçak” ya da “uçan kanat biçimli bir gölge bombardımanı” gibi daha ayrıntılı tanımlar öğreniyor.
Modele Gürültüyü Görmezden Gelmeyi Öğretmek
İkinci yenilik modelin nereye baktığıyla ilgilidir. Birçok uydu veya hava fotoğrafında gerçek gemi ya da uçak yalnızca küçük bir yama kaplar; etrafı dikkat dağıtan gökyüzü, deniz veya arazi ile çevrilidir. OG‑CLIP, insanın tüm kare yerine kilit nesneye bakma alışkanlığını taklit eden bir ilgi bölgesi (ROI) modülü ekler. En son teknoloji bir segmentasyon aracı görüntüde muhtemel nesnelerin hatlarını otomatik olarak çıkarır ve hedefi vurgulayan, arka planı söndüren yumuşak maskeler üretir. Bu maskeler, orijinal görüntüyle birlikte modelin görsel omurgasına beslenir, böylece dikkat kanat şekli, güverte düzeni veya gövde silueti gibi ayırt edici özelliklere doğal olarak yoğunlaşır. Bu eklenti tasarım, çekirdek mimariyi yeniden yazmadan mevcut sistemlere eklenebilir ve onlara daha “nesne‑yönlendirmeli” bir bakış kazandırır.

Detayı Donanıma Göre Uyarlamak
Üçüncü unsur, pratik ama kritik bir konuya değinir: tüm cihazlar aynı ayrıntı düzeyini kaldıramaz. Bir uydu yer istasyonu zengin, yüksek boyutlu özellikleri işleyebilirken, küçük bir drone daha hızlı, daha hafif hesaplamalara ihtiyaç duyar. Geleneksel yöntemler tek bir özellik boyutunu sabitler veya farklı boyutlar için birkaç ayrı model eğitir. OG‑CLIP bunun yerine bir “Matryoshka” tarzı temsil kullanır; bilgiyi iç içe geçmiş bebekler gibi çok seviyeli ayrıntılarda tek bir vektöre paketler. Sistem, yeniden eğitim gerektirmeden bu vektörün daha kısa veya daha uzun bölümlerini—görüntüdeki içeriğin daha kaba veya daha ince betimlemelerini—ayırabilir. Bir ağırlıklandırma mekanizması her seviyenin sınıflandırma için en faydalı bilgileri korumasını teşvik eder ve ek bir kayıp terimi seviyelerin birbirleriyle anlamsal tutarlılığı korumasını sağlar.
Pratikte Ne Kadar İyi Çalışıyor?
OG‑CLIP'i test etmek için araştırmacılar 51 tür askeri uçak, 29 tür savaş gemisi ve 19 sivil veya karma hedef dahil olmak üzere 99 hedef kategorisinden oluşan zor bir değerlendirme seti oluşturdu. Kritik olarak, bu kategorilerin hiçbiri eğitim verilerinde yer almıyor; bu nedenle sistem, kelime ve görsel desenlerden öğrendiği anlayışa dayanmak zorunda — bir “sıfır‑atış” testi. Birkaç güçlü CLIP tabanlı temel yöntemle karşılaştırıldığında OG‑CLIP ortalama doğrulukta 11 puandan fazla iyileşme gösterdi ve genel olarak %84,28’e ulaştı. Özellikle kalabalık, karmaşık sahnelerde ve farklı avcı uçakları gibi benzer modeller arasındaki ince ayrımlarda iyi performans gösterdi; burada ROI modülü ve bilgi açısından zengin betimlemeler ona belirgin bir avantaj sağladı. Ablasyon çalışmaları bilgi grafiği verilerinin, ROI odağının ve uyarlanabilir temsillerin her birinin ölçülebilir katkılar sağladığını gösterdi.
Gerçek Dünya İzleme İçin Anlamı Nedir?
Uzman olmayanlar için ana çıkarım şudur: OG‑CLIP, etiketli örneklerin nadir olduğu durumlarda bile gerçek dünya görüntülerinden tanınmamış uçakları ve gemileri daha güvenilir biçimde tanıyabilen güvenlik ve izleme sistemlerine doğru bir adım niteliğindedir. Yapılandırılmış uzman bilgisi, ilgi nesnesine otomatik odaklanma ve ayarlanabilir ayrıntı seviyelerini birleştirerek yaklaşıma hem daha akıllı hem de daha pratik bir yapay görme‑dil çözümü kazandırır. Savunmanın ötesinde benzer fikirler çevresel izleme, afet müdahalesi ve endüstriyel denetim sistemlerinin karmaşık sahneleri anlamasına ve geniş bir donanım yelpazesinde çalışmasına yardımcı olabilir.
Atıf: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Anahtar kelimeler: sıfır-atış tanıma, görsel-dil modelleri, nesne tespiti, uzaktan algılama, bilgi grafikleri