Clear Sky Science · tr
Özellik çıkarımı yoluyla tabloları ve fotoğrafları sınıflandırmak için görsel algı temelli derin öğrenme transformerları
Günlük görüntüler için neden önemli
Birkaç tıkla gerçeğe yakın bir görüntü oluşturmanın mümkün olduğu bir çağda, bir görselin gerçek bir fotoğraf mı, geleneksel bir resim mi yoksa tamamen algoritmalarla mı oluşturulduğunu ayırt etmek giderek zorlaşıyor. Bu çalışma, modern yapay zekânın insan yapımı tabloları kamerayla çekilmiş fotoğraflardan ve hatta yapay zekâ tarafından üretilen görüntülerden otomatik olarak ayırt edebilmesini nasıl sağladığını araştırıyor; bu da sanat pazarlarını, arşivleri ve çevrimiçi kullanıcıları karışıklık ve sahtekârlıktan korumaya yardımcı oluyor.
Sanat, fotoğraflar ve makine yapımı görsellerin yükselişi
Tablolar ve fotoğraflar ekranda ilk bakışta benzer görünebilir, ancak çok farklı görsel izler taşırlar. Tablolar genellikle görünür fırça darbeleri, stilize renkler ve daha soyut kompozisyonlar gösterirken, fotoğraflar genellikle daha keskin detaylar ve doğal aydınlatma içerir. Aynı zamanda yeni görüntü üreteçleri her iki medyayı da taklit eden eserler üretme konusunda giderek daha yetkin hale geliyor. Müzeler, galeriler, koleksiyoncular ve dijital platformlar, hem sanat eserlerini doğrulamak hem de sentetik içerik akışını yönetmek için hangi tür görselle karşılaştıklarını hızlı ve güvenilir biçimde söyleyebilen araçlara gittikçe daha fazla ihtiyaç duyuyor.
Makinelere görmeyi öğretmek için yeni bir boru hattı
Araştırmacılar, dil işleme için geliştirilen ve şimdi görüntülere uyarlanmış olan Vision Transformer tabanlı eksiksiz bir görüntü analiz boru hattı kurdular. Bu sistemi, çeşitli sahneleri ve stilleri temsil eden 1.361 tablo ve 3.747 fotoğraf içeren halka açık bir Kaggle veri kümesi üzerinde eğittiler. Her görüntü önce standartlaştırılıyor: yeniden boyutlandırılıyor, hafifçe kırpılıyor ve modelin birçok gerçekçi varyasyonu deneyimlemesi için yatay-dikey çevirme, küçük döndürmeler, parlaklık değişiklikleri ve gürültü giderme gibi veri artırma işlemlerinden geçiriliyor. Bu hazırlıktan sonra Vision Transformer her görüntüyü küçük parçalara böler ve görüntünün farklı bölgelerinin tüm çerçeve boyunca birbirleriyle nasıl ilişkilendiğini öğrenir. 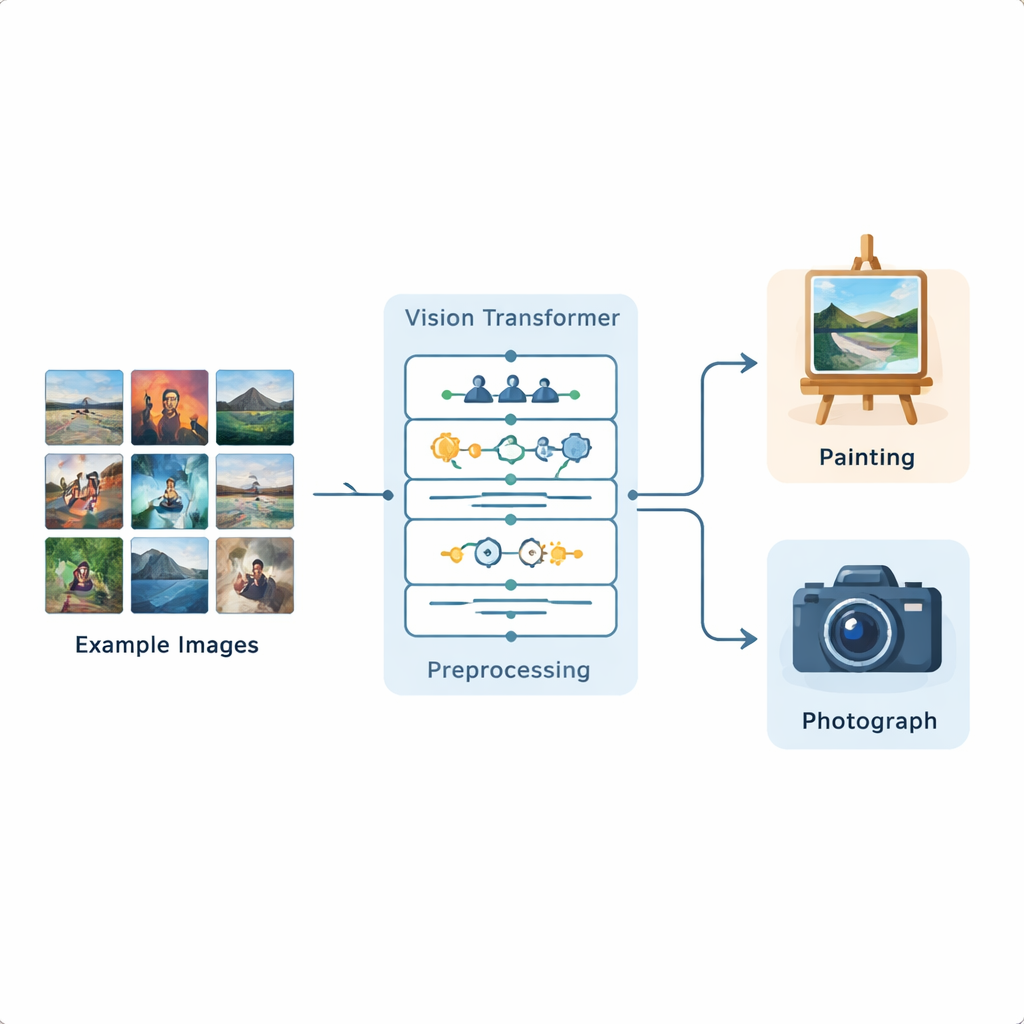
Modelin doğru ayrıntılara nasıl odaklandığı
Yerel desenlere ağırlık veren önceki sinir ağlarından farklı olarak Vision Transformer, hangi görüntü bölgelerinin görev için en önemli olduğuna karar vermek üzere bir "dikkat" mekanizması kullanır. Her yama için diğer her yamaya ne kadar dikkat etmesi gerektiğini etkili biçimde sorgular. Bu, renklerin bir tuval boyunca nasıl aktığı, ışığın bir sahneye nasıl düştüğü veya dokuların nasıl tekrarlandığı gibi küresel yapıları fark etmede daha başarılı olmasını sağlar. Modelin körü körüne tahmin yapmadığını kontrol etmek için yazarlar ayrıca Grad-CAM adlı bir görselleştirme yöntemi uygular; bu yöntem her kararı etkileyen belirli bölgeleri vurgular. Tablolar için bu vurgular genellikle fırça darbesi dokularına ve stilize edilmiş alanlara denk gelirken; fotoğraflarda ince kenarlar, gerçekçi yüzeyler ve aydınlatma geçişleri etrafında kümelenir. 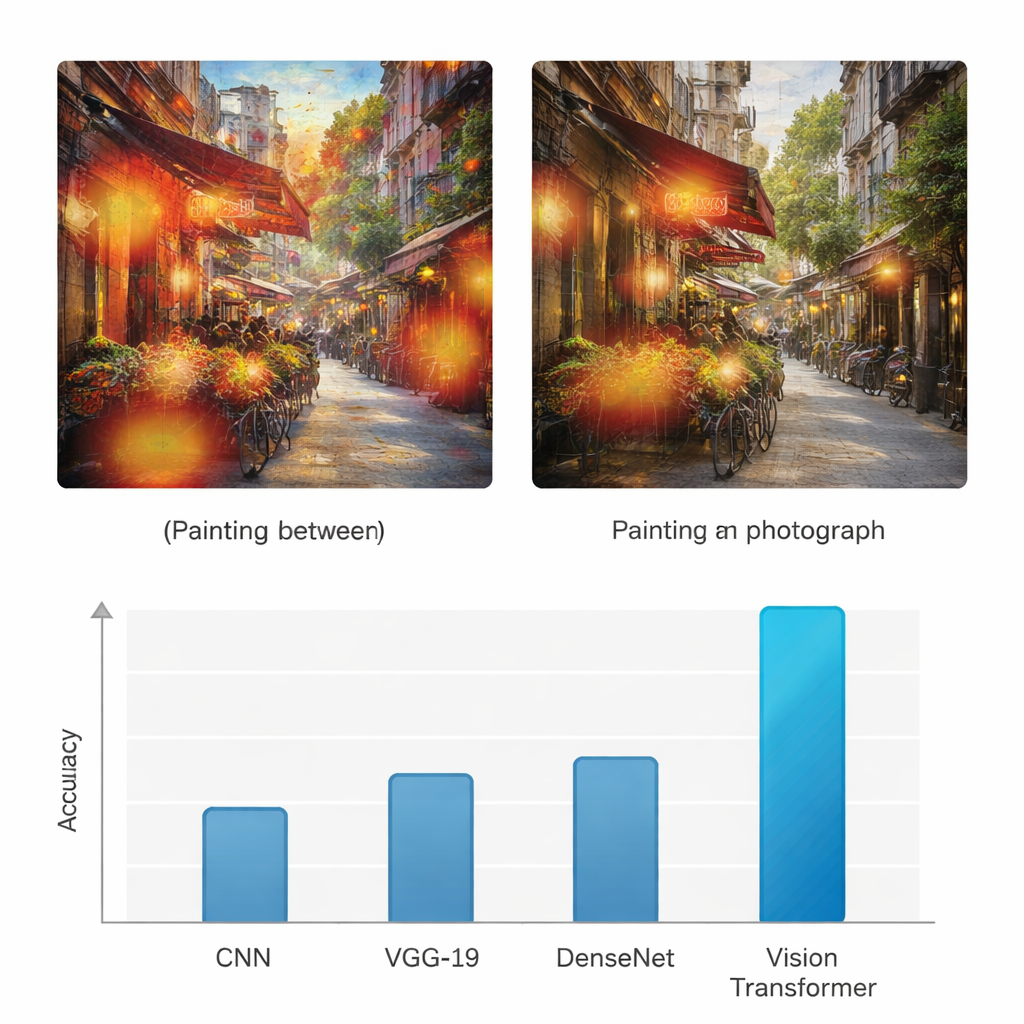
Önceki görüntü tanıma yöntemlerini geride bırakmak
Bu yaklaşımın gerçekten katma değer sağlayıp sağlamadığını görmek için çalışma Vision Transformer'ı üç yaygın derin öğrenme mimarisiyle karşılaştırıyor: standart bir konvolüsyonel sinir ağı (CNN), VGG-19 ağı ve DenseNet. Tüm modeller aynı veri kümesi üzerinde eğitiliyor ve test ediliyor; doğruluk, precision, recall ve F1-skoru gibi yaygın ölçütlerle değerlendiriliyor—bunlar her iki sınıf için doğru tespitleri ve hataları dengeliyor. Temel ağlar yüzde kırklardan seksenlerin ortalarına kadar değişen doğruluklara ulaşırken, Vision Transformer hem tablolar hem de fotoğraflar için %95 doğruluk elde ediyor; benzer şekilde yüksek precision ve recall değerleri gösteriyor. Yazarlar ayrıca bu gelişmenin şansa bağlı olmadığını doğrulamak için bir dizi istatistiksel test yürütüyor ve transformer tabanlı modelin tekrar eden denemeler ve farklı değerlendirme kriterleri boyunca güvenilir biçimde daha iyi olduğunu ortaya koyuyor.
Sanat, güven ve teknoloji açısından anlamı
Bulgular, modern transformer modellerinin tabloları fotoğraflardan ayırmak ve her iki medyayı taklit eden yapay zekâ üretimli görüntüleri işaretlemek için güçlü ve açıklanabilir araçlar olarak hizmet edebileceğini öne sürüyor. Uzman olmayanlar için çıkarım, bilgisayarların artık dikkatli insan gözlemcilerin bile kaçırabileceği fırça işi, pürüzsüzlük veya aydınlatma gradyanları gibi ince ipuçlarını tespit edebildiği ve bunu ölçekli biçimde yapabildiğidir. Bu tür sistemler galerilerin ve koleksiyoncuların eserleri doğrulamasına, küratörler ve arşivcilere büyük dijital koleksiyonları düzenlemede yardımcı olmaya ve çevrimiçi platformların sentetik içeriği etiketlemesine veya filtrelemesine destek verebilir. Görüntü üreteçleri gerçeklik ve kurgu arasındaki sınırı bulanıklaştırmaya devam ettikçe, burada sunulan yöntemler gördüklerimize olan güveni korumanın pratik bir yolunu sunar.
Atıf: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Anahtar kelimeler: Yapay zekâ tarafından üretilen görüntüler, sanat doğrulama, görüntü sınıflandırma, vision transformer, dijital sanat analizi