Clear Sky Science · tr
Arapça NLP sağlamlığını değerlendirmek için düşmanca bir yaklaşım olarak diyalektik ikame
Neden günlük Arapça akıllı bilgisayarları şaşırtıyor
Birçok uygulama artık duygu değerlendirmesi yapmak, haberleri sınıflandırmak veya soruları yanıtlamak için Arapça metinleri okuyor. Ancak bu sistemlerin çoğu Modern Standart Arapça (MSA) üzerinden öğreniyor; oysa gerçek insanlar günlük konuşmalarda bölgesel diyalektleri karıştırıyor. Bu makale, sadece bir kelimenin Mısır veya Körfez Arapçası ile değiştirilmesinin nasıl en son dil modellerini kandırabileceğini gösteriyor; bu da müşteri hizmetleri, medya izlemesi veya çevrimiçi güvenlik gibi alanlarda Arapça yapay zekâya güvenen herkes için endişe uyandırıyor.
Tek dil, birçok ses
Arapça tek, tek tip bir konuşma biçimi değildir. MSA okullarda, haberlerde ve resmî yazışmalarda kullanılırken, günlük konuşmalar Mısır ve Körfez Arapçası gibi diyalektlere dayanır. Bu çeşitler söz varlığı, kelime biçimleri ve hatta cümle yapısı bakımından farklılık gösterir. Örneğin “şimdi” gibi basit bir kelime bölgelere göre çok farklı formlara sahiptir. İnsan okuyucular için bu varyasyonlar doğal ve kolay anlaşılırken, neredeyse tamamen MSA üzerinde eğitilmiş bilgisayar modelleri için diyalekt kelimeleri yabancı görünebilir ve net bir cümleyi kafa karıştırıcı hâle getirebilir.
Diyalektleri yapay zekâ için bir dayanıklılık testi haline getirmek
Arapça dil modellerinin ne kadar kırılgan olduğunu ölçmek için yazar basit iki aşamalı bir test tasarlar. Önce bir model, bir cümlede kararında en çok etkili olan tek kelimeyi bulmak için defalarca sorgulanır—çoğunlukla güçlü bir sıfat, kritik bir fiil veya konu belirten bir isim. İkinci adımda, o tek kelime, büyük ve özenle ince ayarlanmış bir “diyalektleştirici” model kullanılarak Mısır veya Körfez Arapçası karşılığıyla değiştirilir. Cümlenin geri kalanı değişmeden bırakılır ve insan okuyucular için anlam aynı kalır. Bu, değiştirilen cümleyi gerçekçi bir düşmanca örnek yapar: niyeti bozmadan sistemi yanıltmak üzere yapılmış küçük, doğal görünen bir müdahale.
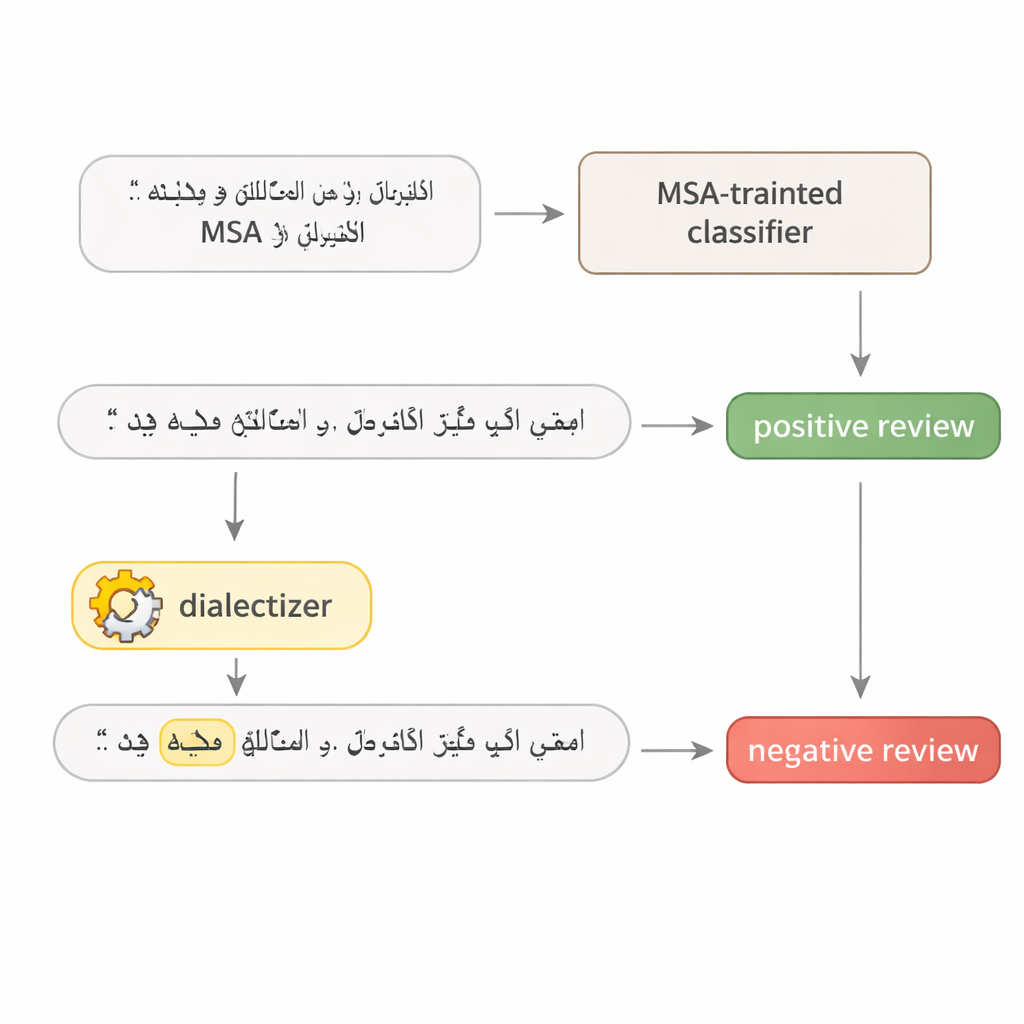
Otel yorumları ve haberleri teste tabi tutmak
Çalışma, dört tanınmış derin öğrenme modeline saldırır: iki büyük dönüştürücü model (AraBERT ve CAMeLBERT) ve iki daha küçük ağ (bir konvolüsyonel model ve iki yönlü bir LSTM). Bu modeller iki büyük MSA veri kümesi üzerinde eğitilmiştir: duygu analizi için otel yorumları ve konu sınıflandırması için haber makaleleri. Her test kümesinden yazar 1.280 örnek seçer ve diyalektik ikame prosedürünü uygular. Her cümlede yalnızca bir kelime değiştirilmiş olmasına rağmen etkisi çarpıcıdır. Otel yorumlarında AraBERT’in doğruluğu temiz metinde yüzde 94’ten Körfez ikameleriyle yaklaşık yüzde 72’ye, Mısır ikameleriyle yüzde 65’e düşer. CAMeLBERT daha da fazla düşer; yaklaşık yüzde 63 ve 55 düzeylerine geriler. Haber sınıflandırıcıları da zarar görür: konvolüsyonel model yaklaşık 18–22 puan kaybederken, LSTM benzer düşüşler gösterir.
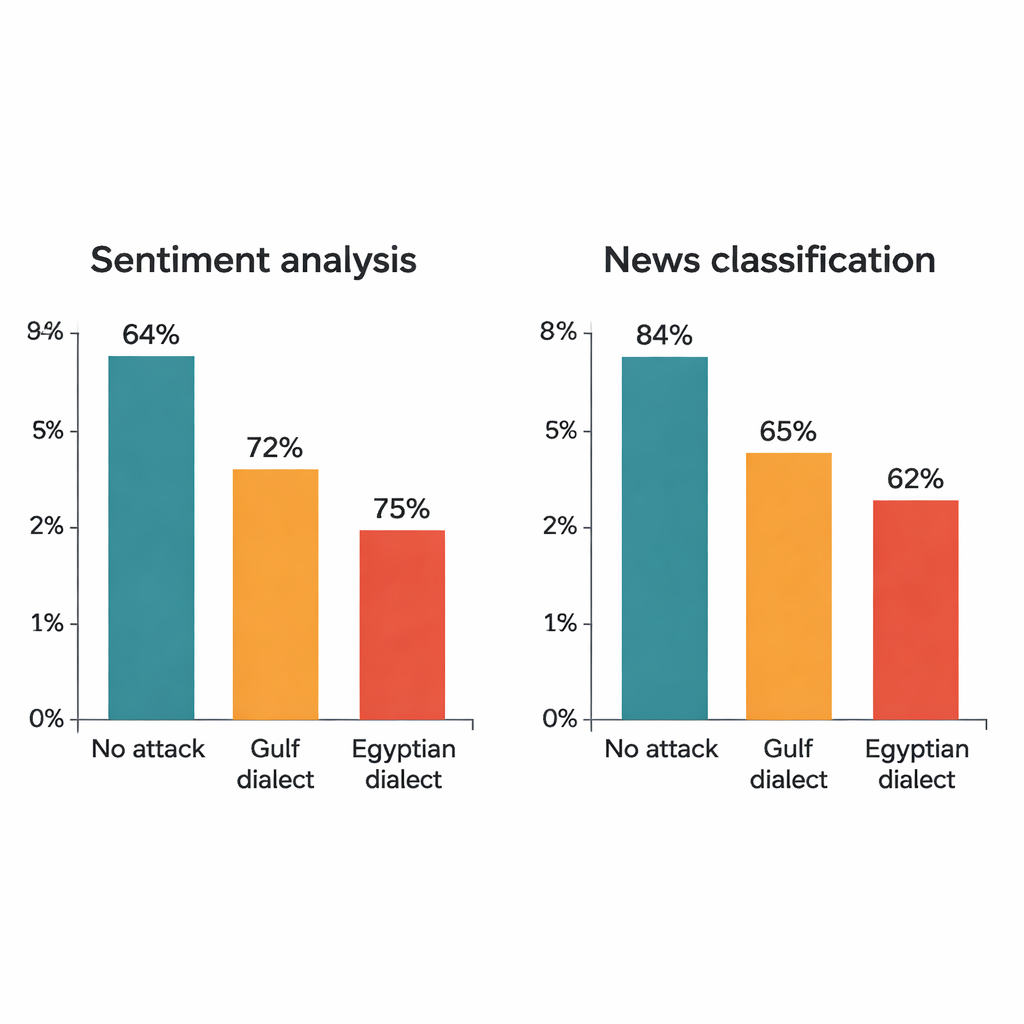
Modellerin içinde ne ters gidiyor
Daha yakından bakıldığında en savunmasız kelimelerin insanların metni nasıl okuduğuyla örtüştüğü görülür. Otel yorumlarında hedef alınan kelimelerin neredeyse yarısı “iyi” veya “korkunç” gibi açık duygusal ağırlığı olan sıfatlardır. Haber makalelerinde ise seçilen kelimelerin çoğu politika, spor veya finans gibi konuları işaret eden isimler ve adlardır. Bu tetikleyici kelimeler diyalekt formlarına çevrildiğinde, yalnızca MSA üzerinde eğitilmiş modeller genellikle bunları tanıyamaz. Dönüştürücü modeller özellikle kırılgan çıkar: alt-kelime parçalarına bağımlılıkları ve birkaç yüksek ağırlıklı token’a verdikleri dikkat, tek bir diyalekt kelimesinin tahmini tersine çevirmesi için yeterli olabilir. Dikkati cümleye daha eşit yayma eğilimindeki daha küçük modeller de kandırılır fakat biraz daha dayanıklıdırlar.
Mısır mı yoksa Körfez mi: tüm diyalektler eşit değil
Saldırılar ayrıca Mısır Arapçasının modelleri Körfez Arapçasından daha fazla şaşırttığını gösterir. Dilbilimsel çalışmalar bunu destekler: Körfez çeşitleri genellikle söz varlığı ve yapı bakımından MSA’ya daha yakın kalma eğilimindeyken, Mısır Arapçası tarihsel ve diğer dillerle temas sonucu daha ayırt edici formlar benimsemiştir. Sonuç olarak, Körfez ikameleri bazen MSA özgününe yeterince benzer ki model hâlâ başa çıkabilirken, Mısır ikameleri modelin daha önce gördüğü şeylerin dışına düşme olasılığı daha yüksektir. İstatistiksel testler gözlemlenen performans düşüşlerinin rastgele olmadığını; mevcut sistemlerin Arapça diglossia’sını ele alışındaki sistematik kör noktaları yansıttığını doğrular.
Bu Arapça yapay zekâ için ne anlama geliyor
Günlük kullanıcılar için çıkarılacak sonuç basittir: bugünün Arapça yapay zekâları, insanlar metni tamamen açık bulsa bile sıradan diyalekt kelimeleri tarafından kolayca şaşırtılabilir. Bir otel yorumundaki tek bir diyalekt terimi bir modelin değerlendirmesini olumlu’dan olumsuz’a çevirebilir veya bir haberin konusunu yanlış etiketleyebilir. Araştırmacılar ve geliştiriciler için mesaj, hem MSA hem de bölgesel diyalektler üzerinde eğitilmiş “diglossia-dikkatli” sistemler inşa etmek ve dayanıklılığı değerlendirirken diyalektik ikame gibi gerçekçi stres testleri kullanmaktır. O zamana kadar, “Arapça sadece MSA’dır” varsayımında bulunan herhangi bir uygulama vahşi doğada ciddi yanlış anlamalara açık olacaktır.
Atıf: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Anahtar kelimeler: Arapça NLP, diyalektal çeşitlilik, düşmanca örnekler, duygu analizi, metin sınıflandırma