Clear Sky Science · tr
MISO aşağı bağlantı sistemlerinde ortak ışın biçimlendirme ve RIS faz optimizasyonu için değiştirilmiş öncelikli DDPG algoritması
Geleceğin Kablosuzu İçin Akıllı Yüzeyler
Telefonlarımız, otomobillerimiz ve sensörlerimiz giderek daha hızlı ve güvenilir bağlantılar talep ettikçe, bugünün kablosuz ağları sınırlarına zorlanıyor. Bu çalışma, binalardaki "akıllı" yansıtıcı yüzeyleri, radyo sinyallerini daha az enerji harcayarak nasıl yönlendireceğini kendi başına öğrenen bir yapay zeka tekniğiyle birleştirerek geleceğin 6G ağlarını hem daha çevreci hem de daha güvenilir kılmanın yeni bir yolunu araştırıyor.
Duvardan Yararlı Birer Sinyal Ayna Yapmak
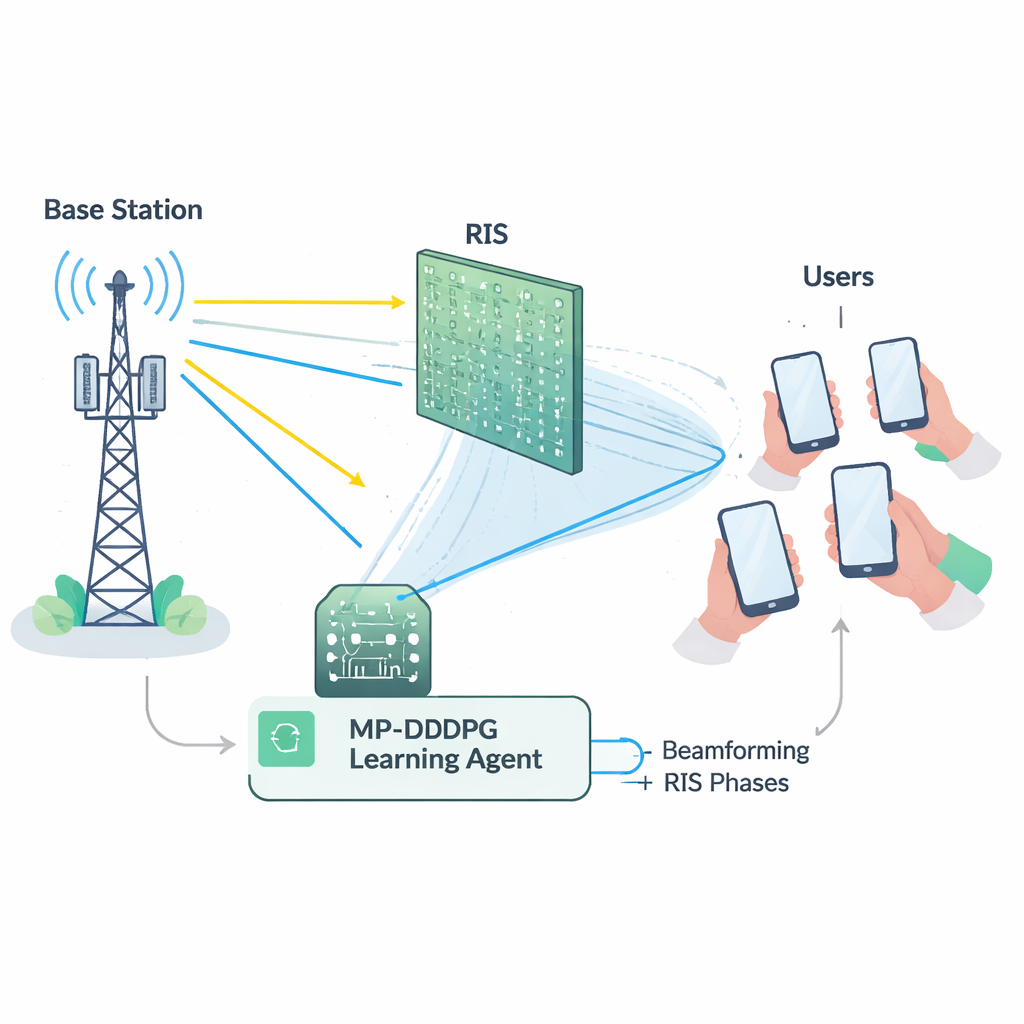
Geleceğin 6G sistemleri, çok sayıda cihaza yüksek veri hızları, sağlam güvenilirlik ve çok düşük gecikme ile hizmet vermek zorunda. Tüm bu talepleri yalnızca geleneksel baz istasyonlarıyla karşılamak, büyük ölçüde ekstra donanım ve enerji gerektirir. Yeniden yapılandırılabilir akıllı yüzeyler (RIS) farklı bir yaklaşım sunuyor: çok sayıda küçük, düşük güçlü elemanla kaplı paneller, gelen radyo dalgalarını programlanabilir bir ayna gibi kontrollü yönlere yansıtabilir. Bu yansımaların fazlarını dikkatle seçerek RIS, sinyalleri engellerin etrafından yönlendirebilir, zayıf bağlantıları güçlendirebilir ve paraziti azaltabilir; üstelik kendi başına aktif olarak iletim yapmadan. Bu, kapsama alanını genişletmeye ve verimliliği artırmaya çalışırken ağ tasarımcılarına güçlü yeni bir ayar düğmesi sağlar.
Ağ İçin Zor Bir Denge Oyunu
RIS'ten iyi yararlanmak kolay değildir. Baz istasyonunun antenlerini nasıl yönlendireceğine (ışın biçimlendirme) karar vermesi gerekirken, RIS her bir yansıtıcı elemanın fazını ayarlamalıdır. Bu seçimler sıkı şekilde bağlıdır ve bir arada birkaç kısıtı karşılamaları gerekir: toplam iletim gücünü maksimumun altında tutmak, her kullanıcıya asgari bir sinyal kalitesi garantisi vermek ve RIS donanımının fiziksel sınırlarına saygı göstermek. Matematiksel olarak bu ortak ayar problemi son derece doğrusal olmayan ve "konveks olmayan" bir yapıdadır; bu da geleneksel optimizasyon araçlarının özellikle ağlar büyüdükçe yavaş, hassas veya alt‑optimal çözümlerde takılıp kalma eğiliminde olduğu anlamına gelir. Buna ek olarak, her radyo bağlantısının ayrıntılı durumunu (sözde kanal durum bilgisi) doğru şekilde ölçmek de gerçek dağıtımlarda maliyetli ve hata eğilimlidir.
Bir Yapay Zeka Ajanının Işınlamayı Öğrenmesine İzin Vermek
Bu zorlukları aşmak için yazarlar, bir ortamla deney‑yanılma yoluyla iyi stratejiler keşfeden bir AI dalı olan derin pekiştirmeli öğrenme kullanan bir öğrenme ajanı inşa ediyorlar. MP‑DDPG (Değiştirilmiş Öncelikli Derin Deterministik Politika Gradyanı) adını verdikleri yöntem, mevcut ağ durumunu—önceki ışın yönleri, RIS ayarları, alınan güç ve sinyal kalitesi—gözlemler ve sonra yeni ışın biçimlendirme ve RIS faz değerlerini seçer. Her seçimden sonra ajan, üç hedefi aynı anda teşvik eden bir ödül alır: daha düşük iletim gücü, kullanıcılar için hizmet kalitesi hedeflerinin karşılanması ve baz istasyonunun güç sınırına uyum. Birçok simüle edilmiş etkileşim boyunca ajan, radyo kanalına ilişkin herhangi bir formül açıkça verilmeden bu hedefleri dengeleyen bir kontrol politikası kademeli olarak öğrenir.
Önemli Olanlara Odaklanarak Daha Hızlı Öğrenme
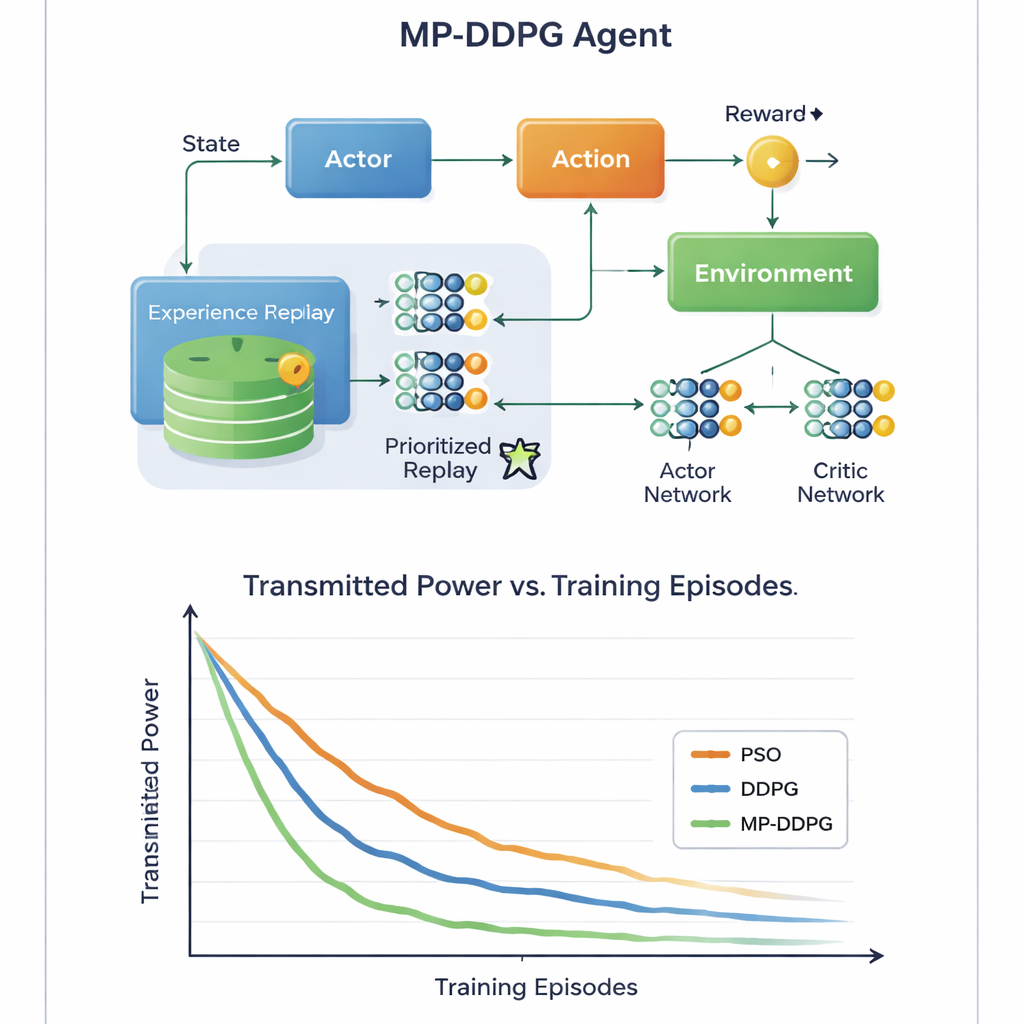
Yöntemin kilit yeniliği, algoritmanın geçmiş deneyimlerinden nasıl öğrendiğinde yatıyor. Standart yaklaşımlar geçmişteki birçok durumu depolar ve eğitim sırasında bunları rastgele örnekler, bu da israflı ve yavaş olabilir. MP‑DDPG bunun yerine depolanan her deneyime hem ödülüne hem de durumunun en yakın komşularından ne kadar farklı olduğuna dayanan bir öncelik atar. Hem bilgilendirici hem de çeşitli olan deneyimler daha sık örneklenir, tekrarlı olanlar ise göz ardı edilir. Bu "değiştirilmiş öncelikli tekrar oynatma" her öğrenme adımını daha faydalı kılar, yakınsamayı hızlandırır ve ajanın kötü yerel çözümlerden kaçınmasına yardımcı olur. Yazarlar ayrıca bunun ek hesaplamasını da analiz eder; defter‑kaydı temel yönteme göre daha karmaşık olsa da daha hızlı öğrenmenin uygulamada bunun fazlasıyla telafi ettiğini gösterirler.
Daha Az Donanımla Daha Yeşil Sinyaller
Aşağı bağlantı hücresel bir senaryonun ayrıntılı bilgisayar simülasyonlarıyla çalışma, MP‑DDPG'yi iki alternatifle karşılaştırıyor: geleneksel parçacık sürü optimizasyonu ve orijinal DDPG öğrenme algoritması. Yeni yöntem, daha az eğitim bölümünde tutarlı şekilde daha düşük iletim gücüne ulaşıyor ve aynı performans düzeyi için daha az RIS elemanı ve daha az baz istasyonu anteni kullanıyor. Basitçe söylemek gerekirse, ağ her yansıtıcı karodan ve her antenten daha fazla fayda çıkarmayı öğreniyor. Bir uzman olmayan okuyucu için mesaj şu: bir AI denetleyicisine hem baz istasyonunun ışınlarını hem de yakın duvarlardaki akıllı yüzeyleri akıllıca ayarlama yetkisi vererek, geleceğin 6G ağları daha az enerji ve daha az donanımla güçlü, güvenilir sinyaller sunabilir; bu da giderek daha bağlı hale gelen dünyamızı daha sürdürülebilir kılmaya yardımcı olur.
Atıf: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Anahtar kelimeler: yeniden yapılandırılabilir akıllı yüzey, 6G kablosuz, derin pekiştirmeli öğrenme, ışın biçimlendirme optimizasyonu, enerji verimli ağlar