Clear Sky Science · tr
Demografik, antropometrik ve kişilik özellikleri kullanılarak üniversite öğrencilerinde gıda bağımlılığının makine öğrenmesi ile tahmini
Yiyecekle ilişkimizi kontrolümüz dışında hissetmemizin nedenleri
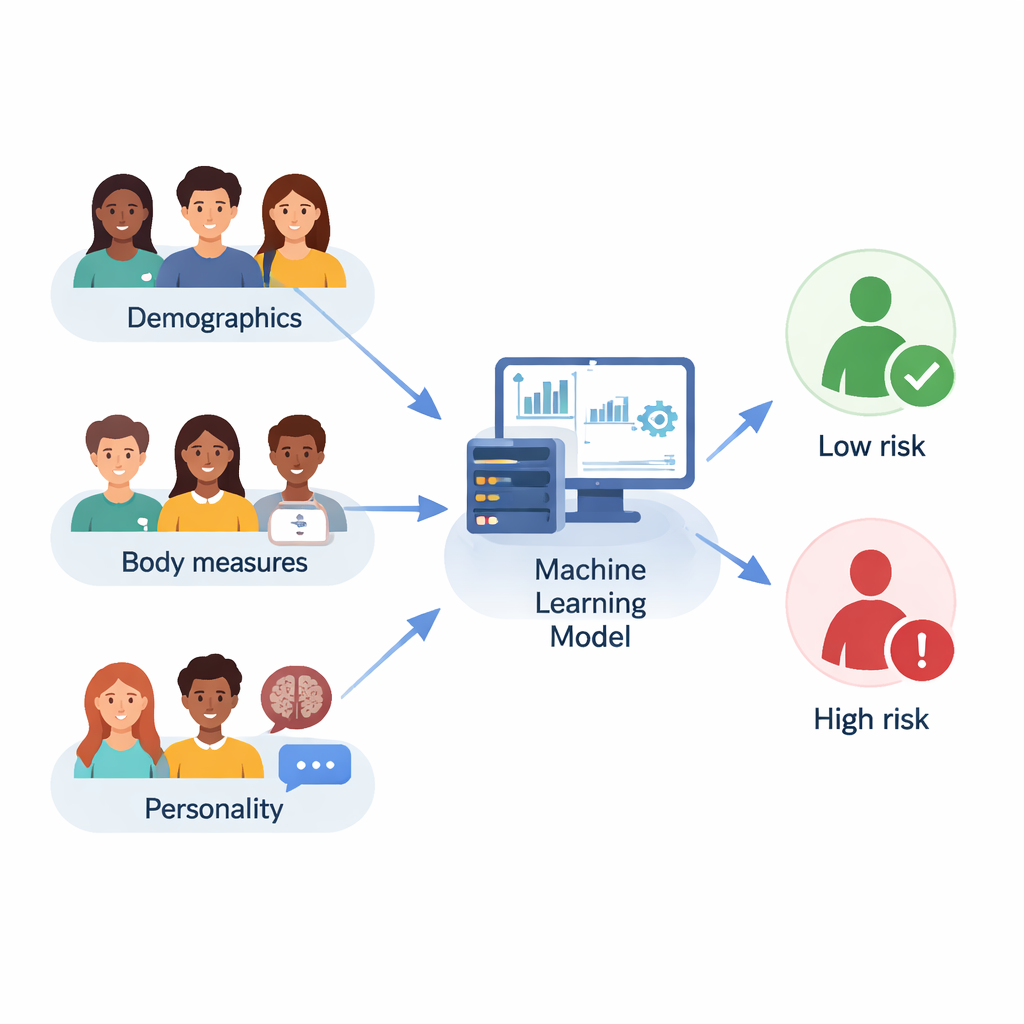
Birçok kişi çikolataya veya fast‑fooda “bağımlıyım” diye şaka yapar, ancak bazıları için yemekle ilgili dürtüler ve kontrol kaybı ciddi ve sıkıntı vericidir. Üniversite öğrencileri; stres, yeni özgürlükler ve değişen bedenlerle başa çıkarken özellikle savunmasızdır. Bu çalışma güncel bir soruyu gündeme getiriyor: bilgisayar programları, öğrencilerin geçmiş bilgileri, beden ölçümleri ve kişilik özellikleri gibi basit bilgilerden yola çıkarak hangi öğrencilerin gıda bağımlılığı açısından daha yüksek risk taşıdığını öğrenebilir mi? Eğer evet ise, ileride sorunları daha erken yakalayıp yeme alışkanlıkları uzun vadeli sağlık sorunlarına dönüşmeden önce desteği kişiselleştirebiliriz.
Öğrencileri birçok açıdan incelemek
Araştırmacılar, İran’ın Ahvaz kentindeki 18–35 yaş arası 210 üniversite öğrencisiyle çalıştı. Her öğrenci yaş ve eğitim düzeyi gibi temel bilgileri verdi, vücut kitle indeksi (VKİ) hesaplanabilmesi için boy ve kilolarını bildirdi ve standart bir kişilik anketini doldurdu. Ayrıca Yale Gıda Bağımlılığı Ölçeği’nin kısa bir versiyonuyla tarandılar; bu ölçek yoğun isteklere, azaltma girişimlerinde başarısızlığa veya olumsuz sonuçlara rağmen yemeye devam etme gibi yüksek lezzetli yiyeceklere yönelik bağımlılık benzeri davranışları sınıflandırır. Sadece 30 öğrenci gıda bağımlılığı kriterlerini karşılarken, 180’i karşılamadı; bu da bu tür sorunların popülasyonun daha küçük bir kısmını etkilediğini yansıtıyor.
Dengesiz veriyi dengelemek ve akıllı makineler eğitmek
Daha az öğrencinin gıda bağımlısı olarak sınıflandırılması nedeniyle veri kümesi dengesizdi. Bu dengesizlik, bilgisayar modellerini çoğunluk grubunu tahmin etmeye itip yüksek riskli azınlığı görmezden gelmeye zorlayabilir. Bunu önlemek için ekip iki veri işleme yöntemi kullandı. İlk olarak, azınlık vakalarına çok yakın duran kafa karıştırıcı çoğunluk vakalarını dikkatlice kaldırmak için Tomek Links adlı bir yöntem uyguladılar. Sonra sayıları eşitlemek için azınlık grubunun gerçekçi sentetik örneklerini oluşturan SMOTE’u kullandılar. Bu değişiklikler yalnızca eğitim verisine uygulandı; modellerin yeni, görülmemiş öğrenciler üzerindeki performansını kontrol etmek için ayrı ve dokunulmamış bir test grubu ayrıldı.
Birçok algoritmayı teste sokmak
Araştırmacılar tek bir matematiksel reçeteye güvenmedi. Bunun yerine lojistik regresyon ve k‑en yakın komşu gibi basit yöntemlerden Random Forest, Gradient Boosting, LightGBM ve CatBoost gibi daha gelişmiş “ensemble” yöntemlere kadar on farklı makine öğrenmesi modelini karşılaştırdılar. Hangi soru ve ölçümlerin en bilgilendirici olduğunu belirlemek için on iki özellik seçimi stratejisi denediler ve her modelin ayarlarını ince ayarlamak için çapraz doğrulama ve otomatik aramalar kullandılar. Genel performans, modelin ne sıklıkla doğru olduğunu gösteren doğruluk, gerçek vakaları yakalarken çok fazla yanlış alarma düşmemeyi dengeleyen F1‑skoru ve yüksek risklileri düşük risklilerden ne kadar iyi ayırdığını yakalayan ROC eğrisi altındaki alan gibi çeşitli ölçütlerle değerlendirildi.
Tahminlerin perde arkası: hangi etkenler etkili
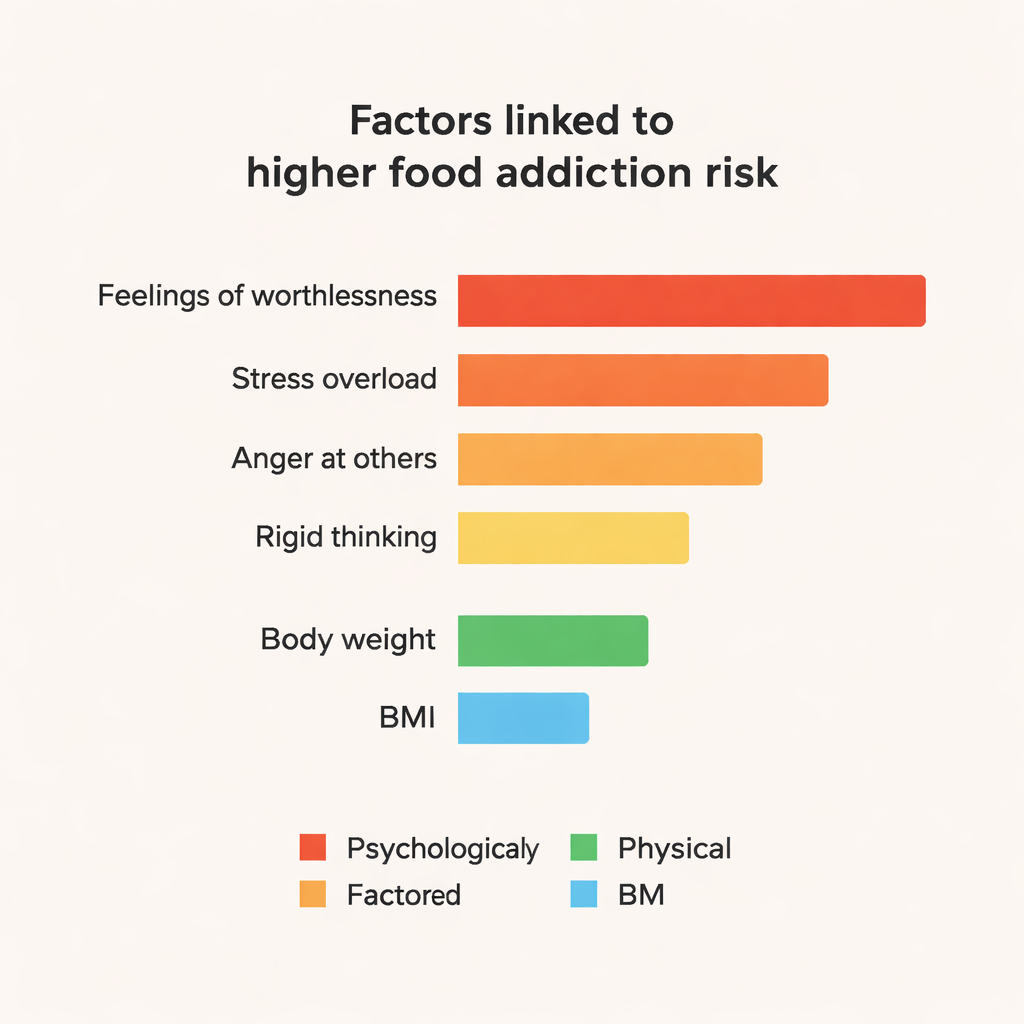
Özellikle CatBoost ve Random Forest gibi ensemble modeller, daha basit yaklaşımları tutarlı şekilde geride bırakarak bu küçük veri kümesinde yaklaşık %84 doğruluk ve yaklaşık 0,84 F1‑skoruna ulaştı. “Kara kutu” tahminlerin ötesine geçmek için ekip, modelin bir kişiyi gıda bağımlısı olarak etiketlemesine hangi özelliklerin daha çok itici güç verdiğini incelemek üzere SHAP adlı bir araç kullandı. Öne çıkan etkenler psikolojik nitelikliydi: “Bazen kendimi tamamen değersiz hissediyorum” gibi güçlü ifadeler, stres altında “parçalanıyormuş” gibi hissetme, başkalarının davranışlarına karşı sık sık öfke, duygusal gerginlik ve katı, esnek olmayan düşünme. Vücut ağırlığı ve VKİ de önemliydi, ancak bu duygu ve kişilikle ilgili işaretler kadar merkezi değildi. Olumlu ruh hali ve iyi organizasyonla ilişkili özellikler ise hafifçe koruyucu bir etki gösterdi.
Günlük yaşam için çıkarımlar
Ortalama okur için ana mesaj, gıda bağımlılığının sadece irade meselesi ya da lezzetli atıştırmalıkları sevmek olmadığıdır. Bu öğrenci pilot grubunda, düşük benlik saygısı, stresle başa çıkma güçlüğü ve zor ilişkiler gibi daha derin duygusal mücadeleler, sorunlu yeme ile sıkı şekilde iç içe geçmişti. Basit anketler ve beden ölçümleriyle beslenen makine öğrenmesi araçlarının erken sürümleri, bu desenleri cesaret verici bir doğrulukla yakalayabildi. Ancak yazarlar, örneklemlerinin küçük, öz‑bildirimlere dayalı ve tek bir üniversiteden geldiğini vurgulayarak sonuçların öncü nitelikte olduğunu belirtiyor. Daha büyük ve çeşitli çalışmalarla, benzer modeller nihayetinde standart klinik değerlendirmelerle birlikte kullanılarak duygularını ve yeme alışkanlıklarını yönetmede desteğe ihtiyaç duyan gençleri tespit etmekte yardımcı olabilir.
Atıf: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Anahtar kelimeler: gıda bağımlılığı, üniversite öğrencileri, kişilik özellikleri, makine öğrenmesi, duygusal yeme