Clear Sky Science · tr
Yüksek boyutlu genomik verilerin doğru sınıflandırılması için hibrit derin öğrenme çerçevesi
Genom Verisi Akışını Anlamak
Günümüz DNA teknolojileri tek bir deneyde on binlerce geni ölçebiliyor; bu da hastalıkların daha erken tespiti ve daha hedefe yönelik tedaviler vaat ediyor. Ancak bu veri bolluğu o kadar büyük, gürültülü ve karmaşık ki, güçlü bilgisayar modelleri bile açık ve güvenilir desenleri bulmakta zorlanıyor. Bu makale, özellikle bu tür aşırı büyük genomik verilerle başa çıkmak üzere tasarlanmış yeni bir yapay zeka (YZ) sistemi tanıtıyor; amaç, tahminlerin doğruluğunu artırırken aynı zamanda bu tahminlerin nasıl yapıldığını da açıklamak.
Genomik Veriyi Kullanmayı Zorlaştıran Nedir?
Genomik çalışmalar rutin olarak hasta veya örnek sayısından çok daha fazla ölçüm üretir. Bu ölçümlerin birçoğu alakasız, tekrarlı veya teknik gürültü tarafından bozulmuş olabilir. Geleneksel makine öğrenmesi yöntemleri ya hangi genlerin önemli olabileceğini insan uzmanların elle seçmesini gerektirir ya da her şeyi kullanmaya çalışıp aşırı uyum riskini alır—yani eğitim verisinde iyi performans gösterirken yeni vakalarda başarısız olur. Görüntü tanıma gibi alanları dönüştüren derin öğrenme, ham veriden otomatik olarak desenler öğrenebilir. Ancak genomikte genellikle bir kara kutu gibi davranır: doğru yanıtlar verebilir, ama nedenini pek açıklamaz; bu da şeffaflığın hayati olduğu tıpta kabulünü sınırlar.
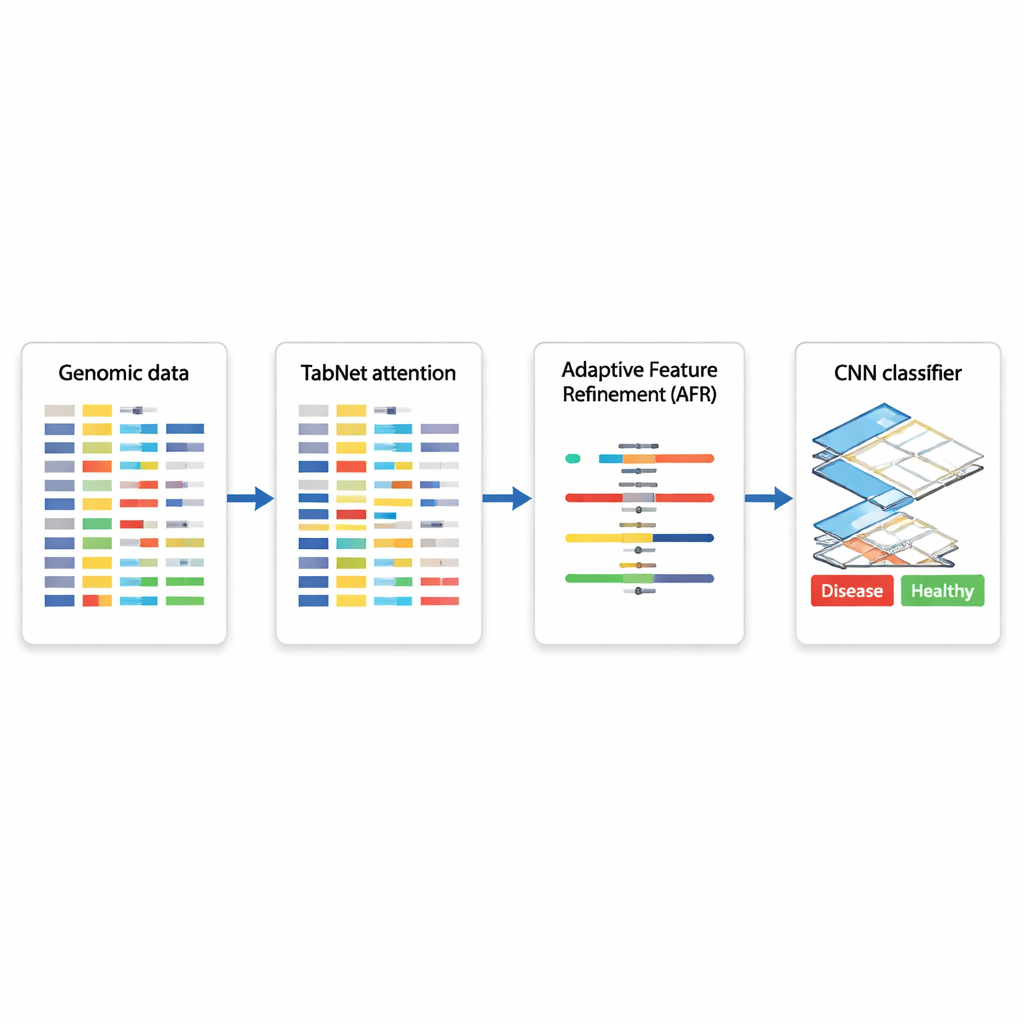
Gen Tabanlı Kararlar İçin Hibrit YZ Taslağı
Yazarlar, üç uzmanlaşmış modülü zincirleyen hibrit bir derin öğrenme mimarisi öneriyor. İlk olarak, TabNet adlı bir bileşen bir spot ışığı gibi hareket ederek mevcut tüm genomik ölçümleri tarar ve belirli bir görev için hangi özelliklerin en bilgilendirici olduğunu öğrenir—örneğin kanserli dokuyu sağlıklı dokudan ayırt etmek gibi. Her geni eşit şekilde ele almak yerine, TabNet en alakalı görünen seyrek bir alt kümeye odaklanır. Ardından Adaptif Özellik İyileştirme (AFR) katmanı bu seçilmiş sinyalleri alıp yeniden ağırlıklandırır; tutarlı ve anlamlı desenleri güçlendirirken gürültüyü daha da bastırır. Son olarak, genellikle görüntü analizinde kullanılan bir konvolüsyonel sinir ağı (CNN), iyileştirilmiş özelliklerin yerel etkileşimlerini inceler ve belirli bir hastalık alt tipi veya biyolojik durumla ilişkili olabilecek gen kümeleri arasındaki ince ilişkileri yakalar.
Modeli Test Etmek
Çerçeve, üç büyük halka açık kaynaktaki veriler üzerinde değerlendirilmiştir: The Cancer Genome Atlas’tan bir meme kanseri veri seti, Gene Expression Omnibus’tan bir tek hücreli melanom veri seti ve ENCODE projesinden bir epigenomik veri seti. Bu koleksiyonlar birlikte binlerce örnek ve örnek başına on binlerce özelliği içeriyor; gen aktivitesi ve DNA üzerindeki kimyasal işaretleri kapsıyor. Tüm veri setlerinde hibrit model, birkaç son teknoloji yaklaşımını geride bırakarak doğruluk ve alıcı işletim karakteristiği eğrisi altında kalan alan (AUC) ve F1-skoru gibi sınıflandırma ölçülerinde yaklaşık %5–8 puanlık iyileşme sağladı. Önemli olarak, bu kazanımlar şeffaflıktan ödün verilerek elde edilmedi: model, hangi genlerin ve bölgelerin her tahminde en etkili olduğunu vurgulayan TabNet’ten dikkat (attention) haritaları ve CNN’den aktivasyon haritaları üretiyor.
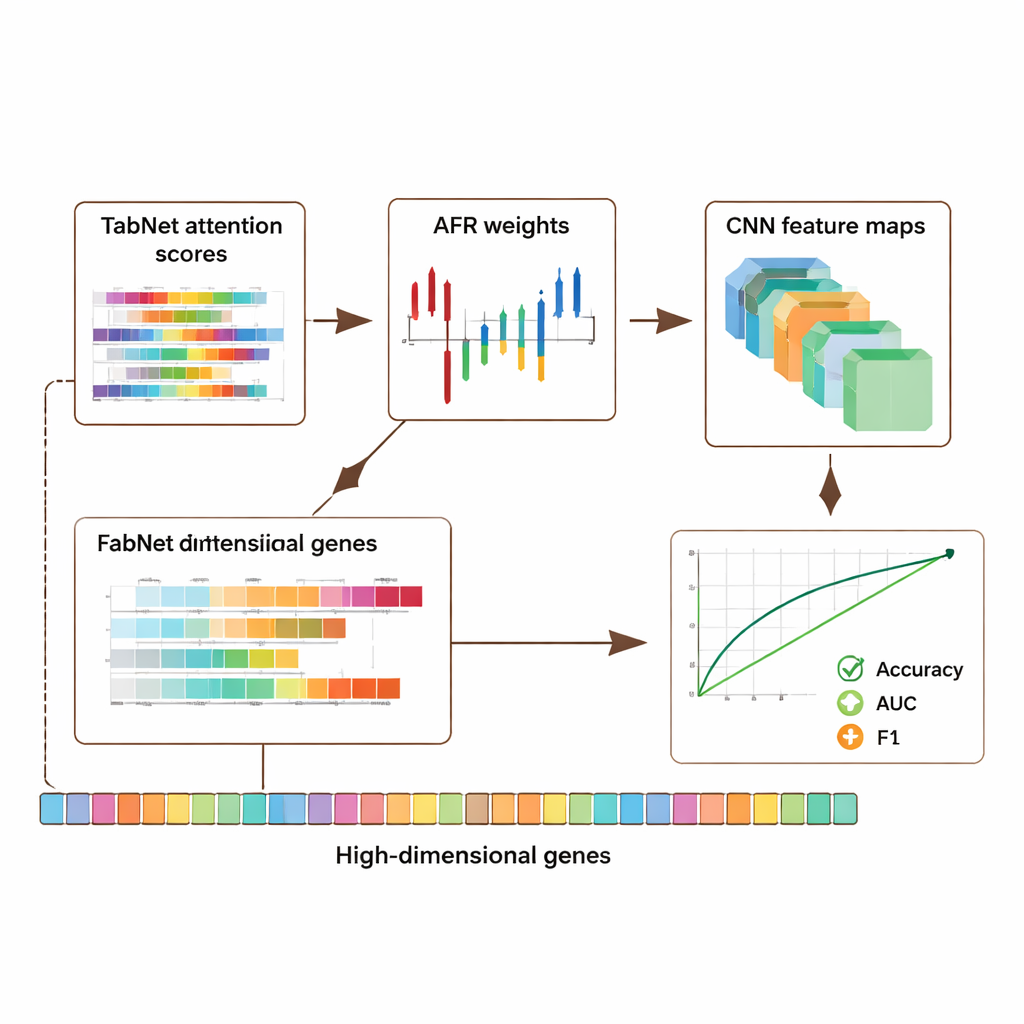
Doğruluk, Gizlilik ve Güven Arasında Denge
Genomik veriler son derece kişisel olduğundan yazarlar, faydalı sinyali korurken gizliliği nasıl sağlanacağını da incelediler. Son derece hassas özelliklere daha fazla, diğerlerine daha az gürültü ekleyen uyarlanabilir bir gizlilik mekanizması ve seçilmiş girdilerin maskelenmesini tanıttılar. Testler, orta düzeyde gürültü eklendiğinde bile modelin güçlü doğruluk ve ayırt edicilik sağladığını, koruma sıkılaştırıldıkça performansın kademeli olarak bozulduğunu gösterdi. Aynı zamanda, yorumlanabilir dikkat ve aktivasyon desenleri genellikle kanser ve bağışıklık düzenlemede rol oynadığı bilinen genlere işaret etti; bu da sistemin sadece verileri ezberlemediğini, biyolojik olarak anlamlı sinyalleri yakaladığını düşündürüyor. Mimarinin parçalarını sistematik olarak çıkarmayı içeren bir yoklama (ablation) çalışması, özellikle AFR katmanının her modülün performansa ölçülebilir katkıda bulunduğunu doğruladı.
Geleceğin Tıbbı İçin Anlamı
Sade bir ifadeyle, bu çalışma, hastalıkla ilişkili desenleri bulmak için devasa genomik tabloları daha akıllıca eleyebilen ve tablodaki hangi girdilerin en önemli olduğunu gösteren bir yöntem sunuyor. Hedefe yönelik özellik seçimi, özenli iyileştirme ve desen tanımayı birleştirerek hibrit model tahmin doğruluğunu iyileştirir, hesaplama açısından yönetilebilir kalır ve klinisyenler ile biyologların yorumlayabileceği görsel ipuçları sağlar. Daha geniş ve çeşitli hasta grupları üzerinde daha fazla test yapılması gerekse de, bu tür çerçeveler yeni biyobelirteçlerin belirlenmesine, hastalık alt tiplerinin incelenmesine ve hassas tıpta klinik karar destek araçlarının geliştirilmesine yardımcı olabilir—DNA analizinde YZ’yi gerçek dünyaya bir adım daha yaklaştırabilir.
Atıf: Swain, M.K., Kamila, N.K., Jena, L. et al. Hybrid deep learning framework for accurate classification of high dimensional genomic data. Sci Rep 16, 5919 (2026). https://doi.org/10.1038/s41598-026-36128-7
Anahtar kelimeler: genomik derin öğrenme, kanser biyobelirteç keşfi, yorumlanabilir YZ, precision medicine, gizliliği koruyan genomik