Clear Sky Science · tr
HEViTPose: kademeli grup mekansal indirgeme dikkat mekanizması ile yüksek doğruluklu ve verimli 2B insan poz tahminine doğru
Bilgisayarlara Beden Dilini Okutmak
Fitness uygulamalarından sürücü destek sistemlerine kadar birçok teknoloji artık insanların nasıl hareket ettiğini bilgisayarların anlamasına dayanıyor. İnsan poz tahmini adı verilen bu yetenek, bir görüntü veya videoda omuz, diz ve bilek gibi vücut eklemlerinin konumlarını bulmayı kapsıyor. Zorluk, bunu hem yüksek doğrulukla hem de günlük donanımda gerçek zamanlı kullanım için yeterince hızlı yapabilmek. Bu makale, mevcut birçok sistemden daha az hesaplama gücü kullanırken yüksek doğruluğu korumayı hedefleyen yeni bir yöntem olan HEViTPose’u tanıtıyor.
Resimlerde Eklem Bulmayı Zorlaştıran Nedir?
İlk bakışta vücut eklemlerini bulmak basit görünebilir: kol ve bacakları aramak yeterli gibi. Uygulamada ise insanlar farklı boyutlarda, alışılmadık pozlarda, kalabalık sahnelerde ve sıklıkla mobilya ya da araç gibi nesnelerin arkasında görünürler. Modern poz tahmin sistemleri genellikle her eklem için parlak noktaların olası pozisyonları gösterdiği ayrıntılı “ısı haritaları” oluşturur. Isı haritaları çok hassastır ama hesaplama maliyeti yüksektir. Geleneksel sistemler ağırlıklı olarak yerel örüntüleri tespit etmekte iyi olan konvolüsyonel sinir ağlarına dayanır, ancak tüm vücut boyunca uzun menzilli ilişkileri yakalamak için daha derin ve ağır hale gelmeleri gerekir. Daha yeni dönüştürücü (transformer) tabanlı modeller bu uzun menzilli bağlantıları yakalamada üstün olsa da genellikle büyük veri setleri ve yoğun hesaplama gerektirir; bu da gerçek zamanlı veya düşük güçlü cihazlarda kullanımını zorlaştırır.
Daha Akıcı Görüş İçin Örtüşen Parçalar
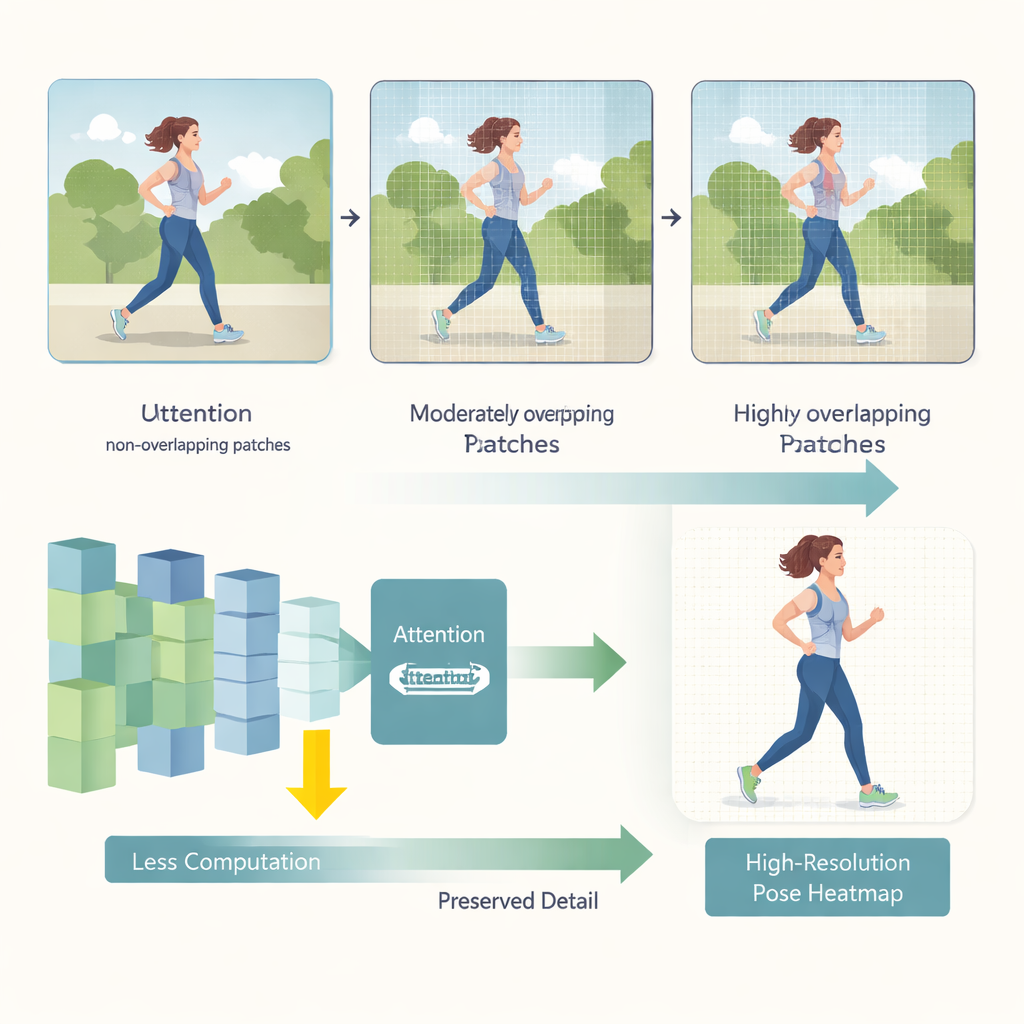
HEViTPose, bir görüntünün analiz için nasıl parçalara ayrıldığı konusunu yeniden düşünerek başlar. Önceki dönüştürücü modeller genellikle görüntüleri örtüşmeyen yama (patch) lar halinde keser; bu da bitişik bölgeler arasındaki görsel sürekliliği—örneğin bir kişinin kolunun bir yamanın kenarında kesilmesi gibi—bozabilir. HEViTPose, örtüşen yama gömme (overlapping patch embedding) fikrini temel alır ve Yama Gömme Örtüşme Genişliği (Patch Embedding Overlap Width, PEOW) adını verdikleri daha açık ve ayarlanabilir bir ölçüm sunar. PEOW, bitişik yamaların sınırları boyunca kaç piksel paylaştığını basitçe sayar. Bu örtüşmeyi sistematik olarak değiştirerek, yazarlar orta düzeyde bir örtüşmenin ağın bir yamanın diğerine göre renk ve şekil değişimini daha iyi “hissetmesine” olanak verdiğini gösteriyor. Bu zengin yerel süreklilik, model boyutunu veya hesaplamayı büyütmeden daha doğru eklem konumlarına yol açıyor.
Daha Az İşleyle Daha Akıllı Dikkat
İkinci temel yenilik, Kademeli Grup Mekansal İndirgeme Çok Başlıklı Dikkat (Cascaded Group Spatial Reduction Multi-Head Attention, CGSR-MHA) adlı yeni bir dikkat modülüdür. Dikkat mekanizmaları ağa hangi görüntü parçalarının her tahmini etkilemesi gerektiğini söyler, ancak görüntüler büyüdükçe genellikle verimsiz ölçeklenirler. CGSR-MHA bunu üç şekilde ele alır. İlk olarak, özellikleri gruplara böler; böylece her grup tüm bilgiyi aynı anda işlemek yerine yalnızca bir kısmıyla ilgilenir. İkinci olarak, dikkat hesaplamadan önce her grup içinde mekansal çözünürlüğü küçültür, bu da işlem sayısını büyük ölçüde azaltır. Üçüncü olarak, birkaç büyük başlık yerine birçok küçük dikkat başlığı kullanır; bu, modelin “dikkatini” nereye verebileceği konusunda çeşitliliği korurken maliyeti düşük tutar. Kaç grup kullanılacağı, ne kadar küçültme yapılacağı ve kaç başlık dahil edileceği gibi dikkatle seçilen ayarlar hız ile doğruluk arasında bir denge kurar.
Yine de Zirvede Yarışan Hafif Modeller
HEViTPose’u test etmek için yazarlar onu iki yaygın benchmark üzerinde değerlendirir: günlük insan etkinliklerini içeren MPII veri seti ve çeşitli sahnelerde insanları barındıran daha büyük COCO veri seti. Birkaç model boyutu boyunca HEViTPose, önde gelen poz tahmini sistemlerinin doğruluğuna eşit veya neredeyse eşit performans gösterirken çok daha az parametre ve hesaplama kullanır. Örneğin, bir versiyon popüler bir yüksek çözünürlüklü ağ (HRNet) ile benzer doğruluğa ulaşırken öğrenilen parametre sayısını %60’tan fazla azaltır ve hesaplama miktarını %40’tan fazla düşürür. Konvolüsyonları ve dönüştürücüleri harmanlayan başka bir modern hibrit modele kıyasla HEViTPose benzer performans sunar fakat bir grafik işlemci üzerinde yaklaşık 2,6 kat daha hızlı çalışır. Bu tasarruflar doğrudan daha pürüzsüz gerçek zamanlı performans ve daha düşük donanım gereksinimleri anlamına gelir.
Günlük Uygulamalar İçin Anlamı Nedir?
Basitçe söylemek gerekirse, HEViTPose bilgisayarlara insan beden dilini okuturken doğruluk ile verimlilik arasında seçim yapmak zorunda olmadığımızı gösteriyor. İncelediği görüntü parçalarının örtüşmesini dikkatle ayarlayarak ve ağ içinde dikkat hesaplamasının nasıl yapıldığını yeniden tasarlayarak, sistem kompakt ve hızlı kalırken eklemleri yüksek hassasiyetle belirleyebiliyor. Bu, hem hızın hem de güç tüketiminin önemli olduğu spor takibi, video gözetimi, insan-robot etkileşimi ve araç içi izleme gibi gerçek dünya uygulamaları için çekici kılıyor. HEViTPose’un arkasındaki fikirler—daha akıllı örtüşme ve verimli dikkat—aynı zamanda hayvan poz takibi veya yüz dönüm noktası tespiti gibi ilişkili görevlere de uyarlanabilir ve birçok cihazda süper bilgisayar düzeyinde donanım gerektirmeden daha keskin “dijital gözler” sağlayabilir.
Atıf: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Anahtar kelimeler: insan poz tahmini, bilgisayarlı görü, görüş dönüştürücüsü, verimli derin öğrenme, dikkat mekanizması