Clear Sky Science · tr
Mel-Spektrogram ve sürekli dalgacık dönüşümü özellikleri kullanarak konuşmacı tanımlama için hibrit bir CNN ve pekiştirmeli öğrenme çerçevesi
Neden Sesiniz Dijital Bir Anahtar Olabilir
Sadece sesinizle banka hesabınızı, ön kapınızı veya telefonunuzu açtığınızı hayal edin. Bunun güvenli olması için bilgisayarların, arka plan gürültüsü, duygu ya da kötü bir mikrofon olsa bile bir kişiyi diğerinden güvenilir şekilde ayırt etmesi gerekir. Bu makale, modern derin öğrenme yöntemlerini robotikten ödünç alınmış deneme-yanılma tarzı bir öğrenme biçimiyle birleştirerek makinelerin yalnızca ne söylendiğini değil, kimin konuştuğunu da tanımayı öğrenmesine yönelik yeni bir yaklaşımı inceliyor.
Ses Dalgalardan Ses Parmak İzlerine
Her insanın sesi, ses yolu boyutu ve şekli, ses tellerinin nasıl titreştiği ve konuşma üslubu tarafından biçimlenen ince ipuçları taşır. Araştırmacılar önce şunu sordu: kaydedilmiş konuşmanın hangi ölçülebilir özellikleri aslında kişiden kişiye farklılaşıyor? LibriSpeech veri kümesindeki 40 İngiliz konuşmacıya ait 2.703 ses klibini kullanarak, şiddet değişimi, farklı frekans bantlarındaki enerji, ritim ve sesin ne kadar karmaşık ya da öngörülemez olduğunu yakalayan entropi gibi 22 basit akustik özelliği analiz ettiler. İstatistiksel testler bu 22 özellikten 21’inin güçlü konuşmacıya özgü bilgi taşıdığını gösterdi; entropi ve yüksek frekans enerjisi özellikle ayırt edici çıktı. Başka bir deyişle, bir kişinin “ses parmak izi” yalnızca perde ya da ses seviyesiyle sınırlı olmayıp sesin birçok yönüne yayılmış durumda.
Sesi Görüntüye Çevirmenin İki Yolu
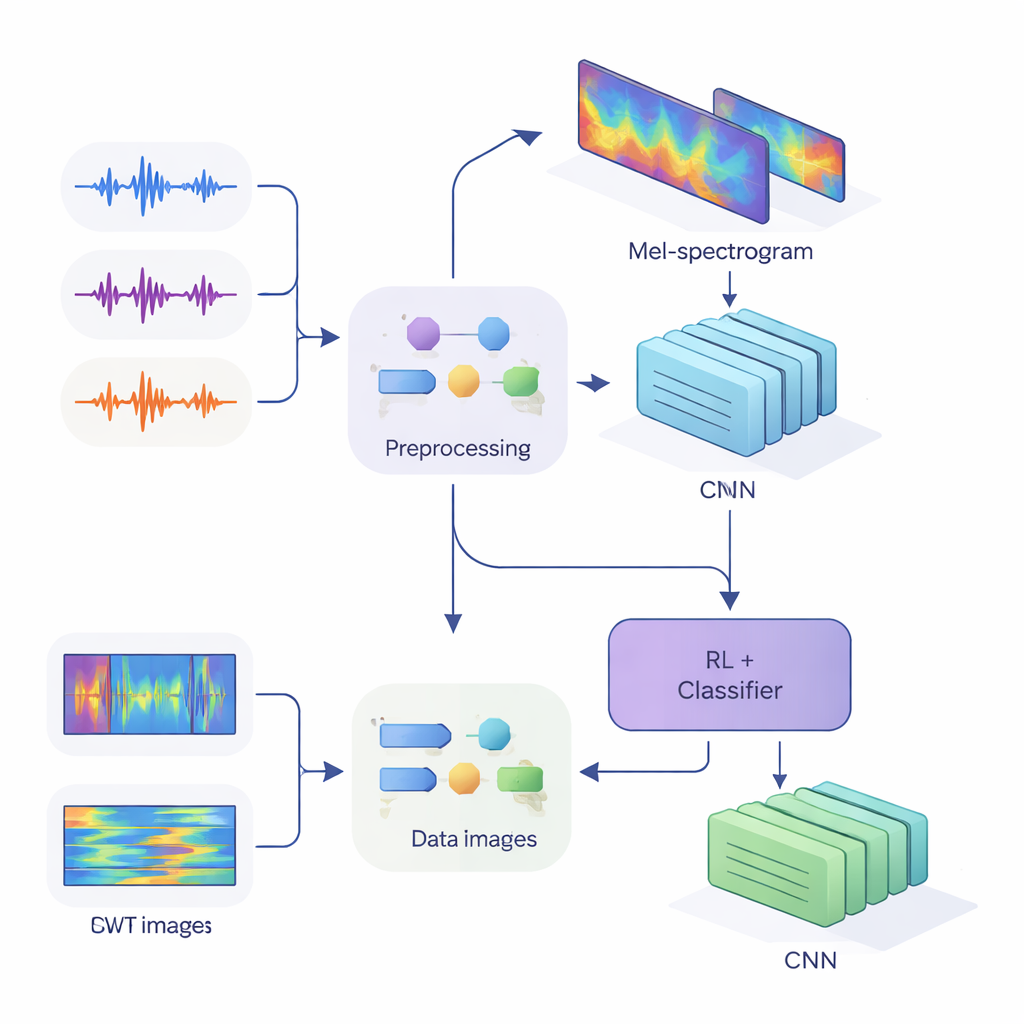
Bu ipuçlarını modern sinir ağlarına beslemek için ekip, tek boyutlu sesi zaman ve frekans boyunca enerjinin nasıl değiştiğini yakalayan iki boyutlu resimlere dönüştürdü. İlk yöntemde insan kulağının frekansları nasıl gruplayıp algıladığını taklit eden ve konuşma teknolojilerinde standart olan Mel-spektrogramları kullandılar. İkinci yöntemde ise kısa, keskin seslere ve daha uzun ünlülere aynı anda odaklanabilen daha esnek bir yaklaşım olan sürekli dalgacık dönüşümlerini kullandılar. Sesi dikkatle temizledikten—sessizlikleri kaldırma, ses seviyesini standartlaştırma ve sistemi daha dayanıklı kılmak için gürültü ve perde kaymaları gibi küçük bozulmalar ekleme—sonra CNN’ler tarafından işlenmeye hazır 80 x 313 boyutunda Mel “görüntüleri” ve 128 x 128 boyutunda dalgacık “görüntüleri” ürettiler.
Ağlara Dinlemeyi ve Şüphe Etmeyi Öğretmek
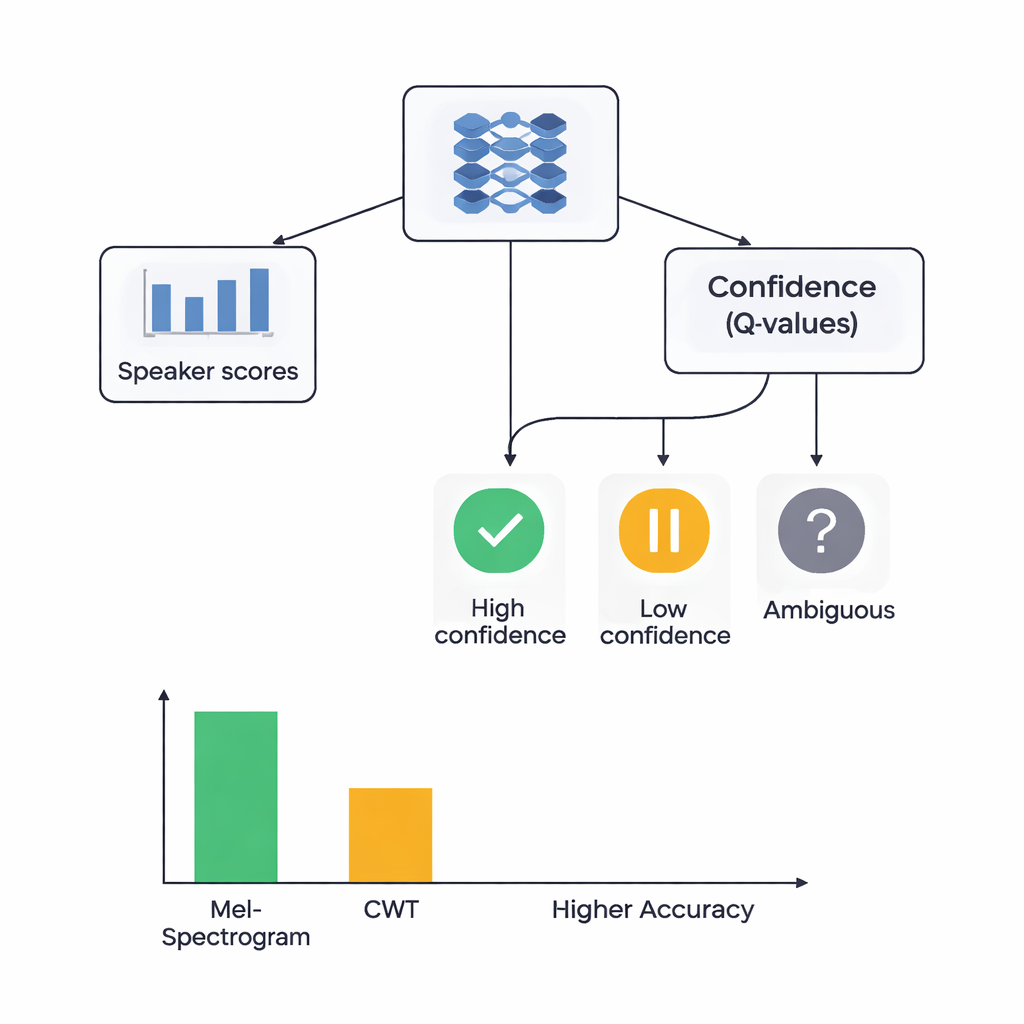
Çalışmanın merkezinde iki öğrenme tarzını birleştiren hibrit bir mimari yer alıyor. Önce CNN’ler Mel veya dalgacık görüntülerini tarayarak belirli konuşmacılara ait olma eğilimindeki desenleri çıkarıyor; bu, görüntü tanıma ağlarının göz ya da kenarları tanımayı öğrenmesine benziyor. Mel tabanlı sistem için yazarlar, ağın en bilgilendirici zaman dilimlerine odaklanmasına izin veren bir kendine dikkat (self-attention) modülü ekliyor. Bu özellik çıkarıcıların üzerine bir de pekiştirmeli öğrenme (RL) bileşeni yerleştiriliyor; bu bileşen sistemin her karar için ne kadar emin olması gerektiğini öğreniyor. Her zaman kesin bir seçim yapmak yerine RL kısmı “bunu yüksek güvenli bir tahmin olarak kabul et”, “bunu düşük güvenlikli say”, veya “kararsız olarak işaretle” gibi eylemlere değer atıyor. Çok sayıda eğitim turu boyunca, emin kararlar doğru olduğunda ödüllendiriliyor; bu da ağı daha iyi kalibre edilmiş yargılara doğru yönlendiriyor.
Hibrit Sistem Ne Kadar İyi Çalışıyor?
Araştırmacılar dört modeli karşılaştırdı: RL ile Mel tabanlı, RL olmadan Mel tabanlı, RL ile dalgacık tabanlı ve RL olmadan dalgacık tabanlı. Hepsi titiz bir beş katlı çapraz doğrulama ile test edildi; yani her ses klibi farklı turlarda hem eğitim hem test için kullanıldı. Mel + RL sistemi en iyi performansı gösterdi; konuşmacıyı yaklaşık %88 doğrulukla tanımladı ve ayrım gücünün standart bir ölçüsüne göre konuşmacılar arasında neredeyse mükemmel ayrım sergiledi. Dalgacık + RL sistemi yaklaşık %78 doğruluğa ulaştı. Önemli olarak, RL bileşeninin eklenmesi her iki özellik türünde de performansı yaklaşık 3 puan artırdı ve farklı veri bölmelerinde sonuçları daha tutarlı hale getirdi. RL eklendiğinde daha fazla konuşmacı sınıfı yüksek kaliteli tanıma elde etti; bu da özellikle karışması kolay, zor seslerde güvene-dayalı kararların yardımcı olduğunu gösteriyor.
Günlük Ses Güvenliği İçin Anlamı
Uzman olmayanlar için temel çıkarım, güvenilir ses tabanlı kimlik doğrulamanın hem sesin zengin temsillerini hem de makinenin sağlıklı bir şüphe duygusunu gerektirdiğidir. Bu çalışma, kulağı taklit eden Mel-spektrogramların, dikkat mekanizması ve “emin değilim” diyebilen bir pekiştirmeli öğreniciyle birleştirildiğinde, konuşmacıları ayırt etme görevinde daha egzotik dalgacık görüntülerinden daha iyi sonuç verdiğini gösteriyor. Çalışma görece küçük ve temiz bir veri kümesi kullanıyor ve henüz gürültülü, gerçek dünya koşullarına göre ayarlanmış değil; yine de derin sinir ağlarının üzerine güven-eğilimli bir katman eklemenin ses kimlik doğrulamayı hem daha doğru hem de daha güvenilir hale getirebileceğini gösteriyor—seslerimizin güvenli dijital anahtarlara dönüşmesi için önemli bir adım.
Atıf: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Anahtar kelimeler: konuşmacı tanımlama, ses biyometrisi, derin öğrenme, pekiştirmeli öğrenme, Mel-spektrogramlar