Clear Sky Science · tr
Uyarlanabilir parametrik olmayan boyut indirgeme için genel bir çerçeve
Neden büyük veriyi küçültmek önemli
Modern yaşam veriyle dönüyor: tıbbi taramalar, çevrimiçi alışveriş geçmişleri, fotoğraflar, haber akışları ve daha fazlası. Her kayıt yüzlerce veya binlerce ölçüm içerebilir; bu da depolamayı, analiz etmeyi ya da görselleştirmeyi zorlaştırır. Bilim insanları, önemli desenleri korurken bu karmaşıklığı daha basit görüntülere ve modellere sıkıştırmak için “boyut indirgeme” kullanır. Ancak günün popüler araçları genellikle birçok elle yapılan seçim ve deneme‑yanılma ayarı gerektirir. Bu makale, verinin kendisinin en iyi şekilde nasıl küçültüleceğine karar vermesine izin veren bir yol sunar; amaç daha net görseller, daha doğru öğrenme ve kullanıcı için daha az tahmin gerektiren bir süreçtir.
Basit doğrulardan kıvrımlı gerçekliklere
Verileri basitleştirmek için klasik bir araç olan Temel Bileşen Analizi (PCA), bir nesneye ışık tutup gölgesine bakmak gibi çalışır: verideki varyansın çoğunu açıklayan en iyi düz yönleri bulur. Veri yapısı kabaca düz veya doğrusal olduğunda bu güçlüdür. Ancak görüntüler, metinler veya sensör okumaları gibi gerçek dünya verileri genellikle yüksek boyutlu uzay içinde gizlenmiş kıvrımlı yüzeyler üzerinde yatar. Son yirmi yılda Isomap, Locally Linear Embedding (LLE), spektral gömme ve UMAP gibi yeni “doğrusal olmayan” yöntemler bu dolaşık şekilleri açığa çıkarmak üzere geliştirildi. Bu yöntemler yerel komşuluklara dayanır: her nokta için en yakın komşularına bakar ve daha düşük boyutlu bir görüntü çizilirken bu küçük ölçekli ilişkileri korumaya çalışır. Ancak bu yöntemler kullanıcıdan iki temel parametreyi seçmesini ister: kaç komşu kullanılacağı ve kaç boyuta projeksiyon yapılacağı. Yanlış seçim, yanıltıcı sonuçlara veya yüksek hesaplama maliyetine yol açabilir.
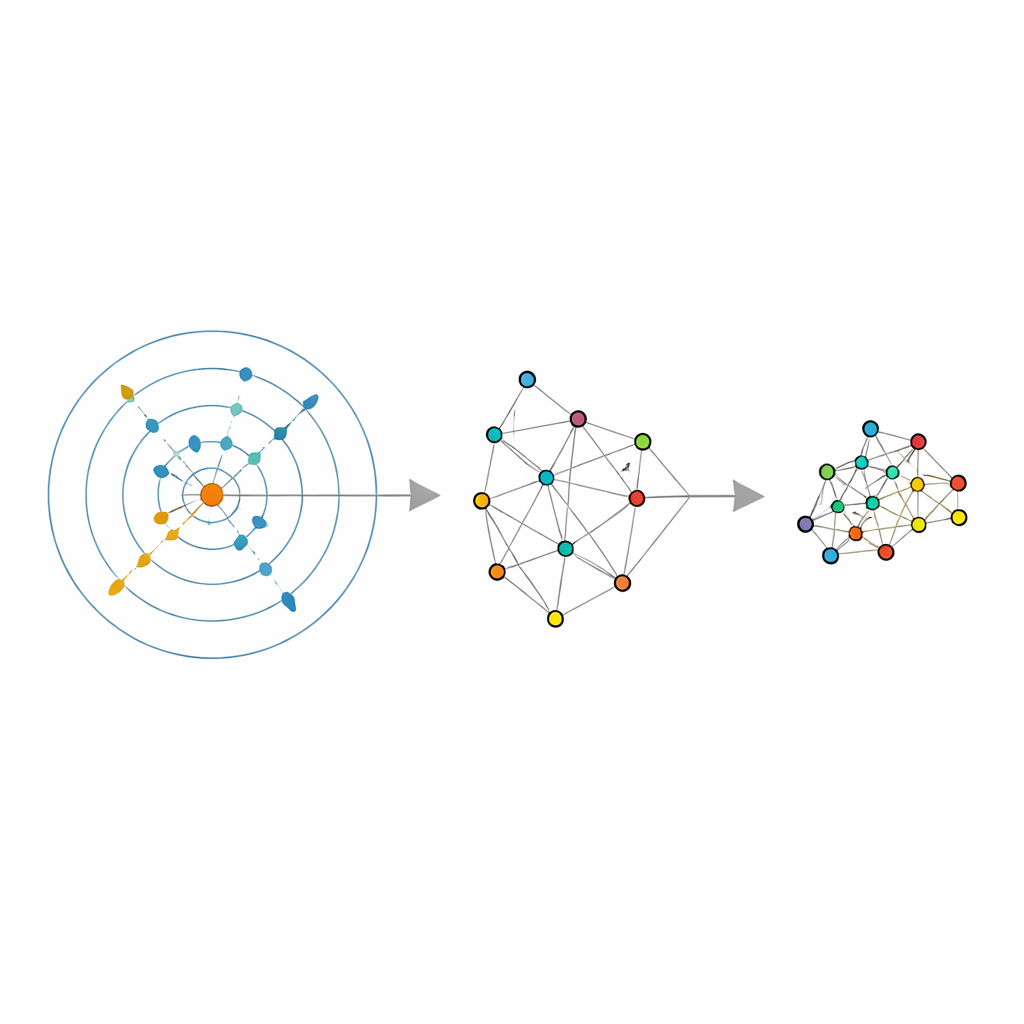
Verinin kendi komşuluğunu seçmesine izin vermek
Yazarlar, gürültü temizlendiğinde verinin gerçekten kaç bağımsız yönde değiştiğini yanıtlamaya çalışan bir özgün boyut kestiricisi adlı son istatistiksel araca dayanıyor. ABIDE adını verdikleri kestirici daha ileri gider. Her nokta etrafında ne çok küçük ve gürültülü ne de çok büyük ve bozulmuş olacak şekilde makul ölçüde tekdüze görünen bir komşuluğu otomatik olarak arar. Bunu yaparken iki bilgi döndürür: verinin gerçek boyutuna dair küresel bir kestirim ve her nokta için özel bir komşuluk boyutu. Bu, sabit “komşu sayısı” kavramını, seyrek bölgelerde büyüyebilen ve yoğun bölgelerde daralabilen, verinin gerçek yoğunluğuna uyum sağlayan yerel olarak uyarlanabilir bir büyüklüğe dönüştürür.
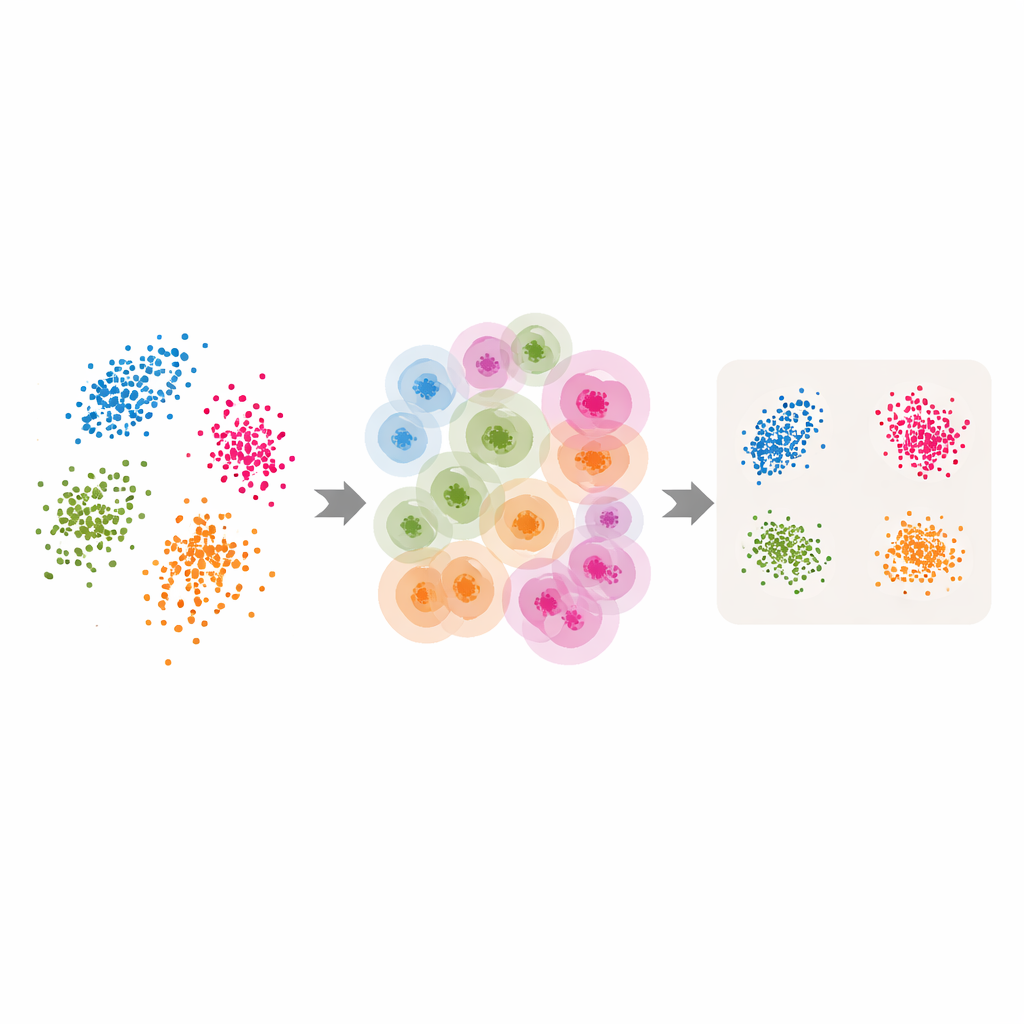
Klasik araçları uyarlanabilir hale getirmek
Bu uyarlanabilir komşuluklar ve tahmin edilen özgün boyutla donanan yazarlar, birkaç popüler boyut indirgeme ve kümeleme yöntemini yeniden düzenler. LLE için tek bir kullanıcı tarafından seçilen komşu sayısını ABIDE tarafından döndürülen nokta başına değerlerle değiştirirler ve hedef boyutu tahmin edilen özgün boyuta eşitlerler. Algoritma, her noktayı dikkatle seçilmiş yerel bir gruptan nasıl yeniden oluşturacağını öğrenir; ardından bu yerel yeniden oluşturma ilişkilerini en iyi koruyan küresel düşük boyutlu düzeni bulur. Benzer fikirler spektral kümelemede—noktalar arasındaki benzerlikler grafiği kullanılarak gruplaştırma yapılan yerde—ve noktaların nasıl bağlandığına dair bulanık bir harita oluşturan UMAP’ta uygulanır. Her durumda katı komşuluk boyutu, verinin doğal geometrisini takip eden esnek, veri odaklı bir yapıyla değiştirilir.
Çiçekler, rakamlar, metin ve sentetik şekiller üzerinde test
Bu uyarlanabilir yaklaşımın işe yarayıp yaramadığını görmek için yazarlar birkaç kıyas setinde deneyler yürütür: klasik Iris çiçeği ölçümleri, el yazısı rakam görüntüleri (MNIST), dil modeli gömme vektörleriyle temsil edilen haber makaleleri ve gürültü eklenmiş sentetik üç boyutlu şekiller. Uyarlanabilir versiyonları standart yazılım ayarları ve özenle ayarlanmış hiper‑parametre ızgaralarıyla karşılaştırırlar. Kümeleme ve görselleştirme gibi denetimsiz görevlerde, uyarlanabilir yöntemler tipik olarak daha net kümelemeler, daha sıkı gruplamalar ve standart kalite ölçümlerinde daha iyi skorlar verir. Örneğin, nokta yoğunluğunun düzensiz olduğu karmaşık manifoldlarda uyarlanabilir yöntemler gerçekteki yapıyı sabit komşulu versiyonlardan çok daha iyi kurtarır. Denetimli testlerde, indirgenmiş veriler bir sınıflandırıcıya verildiğinde, uyarlanabilir yaklaşım yine en iyi sabit‑ayar seçimleriyle eşleşir veya onları geride bırakır; üstelik yoğun ayar yapma gerektirmeden.
Günlük veri analizine etkisi
Uzman olmayanlar ve uygulayıcılar için ana mesaj şudur: veriyi küçültmek tahminlere dayanmak zorunda değildir. “Kaç komşu” ve “kaç boyut” sorularını verinin kendi geometrisine bırakarak, bu çerçeve LLE, spektral kümeleme ve UMAP gibi yaygın araçları daha akıllı, daha sağlam versiyonlara çevirir. Sonuç, verinin gerçek şekline daha iyi yansıyan—güvenilir düşük boyutlu görünümler; grafikler ve öznitelikler—aynı zamanda manuel hiper‑parametre aramalarında harcanan zamanı azaltır. Pratik anlamda bu, büyük görüntü koleksiyonlarını görselleştirmek, belgeleri gruplaymak veya tahmine dayalı modeller için girişleri hazırlamak gibi görevlerin, verinin nasıl sıkıştırılacağını verinin kendisinin uyarlanabilir biçimde yönlendirmesine izin vererek hem daha kolay hem de daha güvenilir hale gelebileceği anlamına gelir.
Atıf: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Anahtar kelimeler: boyut indirgeme, manifold öğrenimi, en yakın komşular, özgün boyut, veri görselleştirme