Hükümetler, bilim insanları veya anketçiler bir nüfus hakkında—örneğin ortalama gelir, ürün verimi veya kirlilik düzeyi—bir şeyler öğrenmeye çalıştıklarında nadiren herkesi ölçebilirler. Bunun yerine bir örnek seçer ve ölçeklendirirler. Bu ancak veriler düzgün davrandığında iyi çalışır. Gerçekte ise anketler ve ölçümler hatalar ve sonuçları ciddi şekilde çarpabilecek uç değerlerle doludur. Bu makale, veriler karışıksa bile güvenilir kalan nüfus ortalamalarını hesaplamanın yeni bir yolunu tanıtıyor; bu da anket tabanlı kararları daha güvenilir kılıyor.
Basit ortalamalar ne zaman yanlış yapar
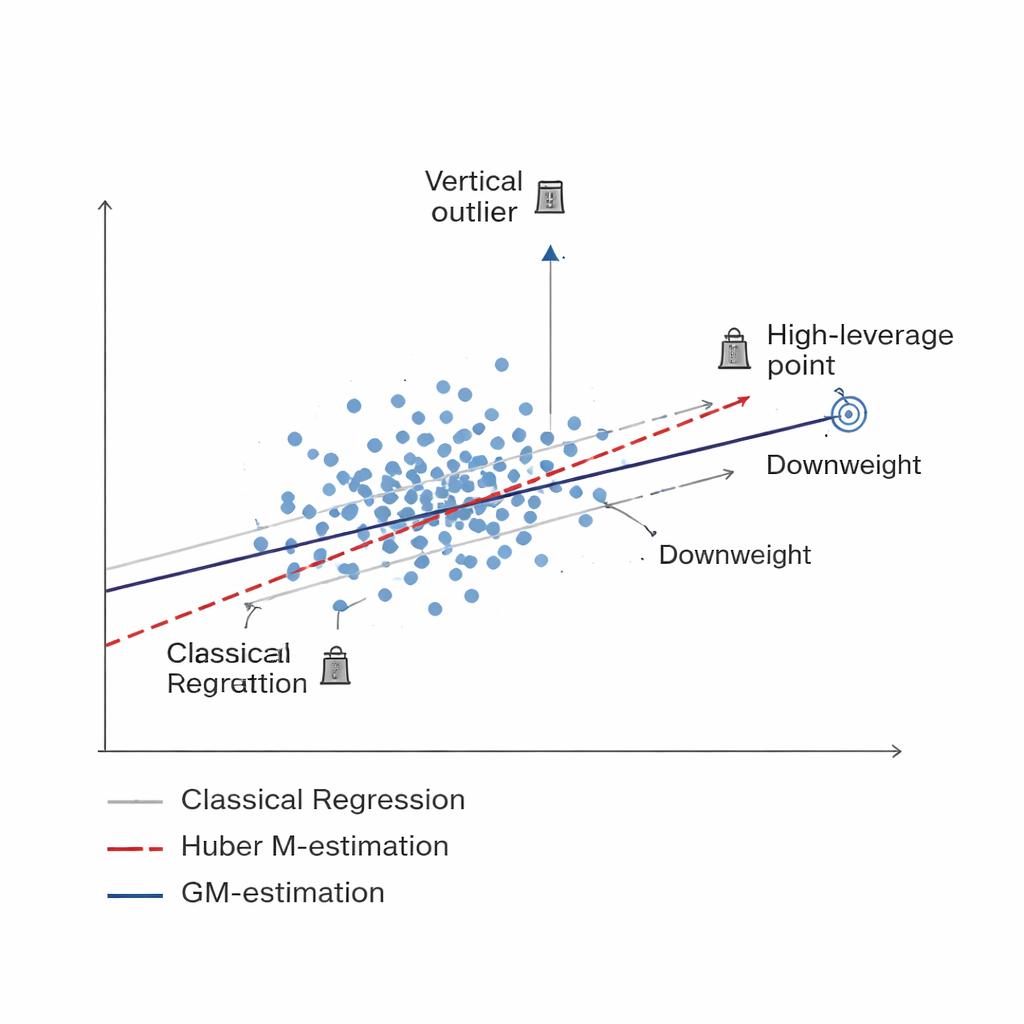
Nüfus ortalaması tahmininde kullanılan standart araçlar—örnek ortalaması veya sıradan regresyon gibi—çoğu veri noktasının uç aykırı değerler veya sıra dışı vakalar olmadan düzgün desenler izlediğini varsayar. Sosyal ve ekonomik anketlerde, çevresel izlemede ve tarımsal istatistiklerde bu beklenti sıklıkla karşılanmaz. Birkaç hatalı ölçüm, nadir ama aşırı olaylar veya yanlış bildirilmiş yanıtlar tahminleri gerçeğinden uzaklaştırarak hem yanlılığı hem de belirsizliği artırabilir. Önceki çalışmalar, Huber M-tahmini gibi popüler sağlam yöntemler de dahil olmak üzere bu tür aykırıların etkisini azaltmaya çalıştı. Bu yöntemler yararlı olmakla birlikte, esas olarak ölçülen sonucun aşırı değerlerine karşı koruma sağlar ve eşlik eden açıklayıcı bilgideki sıra dışı desenlere karşı hâlâ savunmasız kalır.
Kötü verileri daha akıllıca ağırlıklandırmak Figure 1.
Çalışma, Genelleştirilmiş M-tahminine (GM-tahmini) dayanan yeni bir türevci oluşturuyor. Her örnek birimini eşit görmek yerine, GM yöntemleri iki şeye bağlı olarak uyarlanabilir ağırlıklar atar: bir birimin yanıtının ne kadar uç olduğu (dikey aykırı) ve onunla ilişkili bilgilerin ne kadar sıra dışı olduğu (yüksek kaldıraç noktası). Mallows-GM, Schweppes-GM ve SIS-GM olarak adlandırılan üç özel versiyon, yerine koyma olmadan basit rastgele örneklemeden nüfusun nispeten homojen gruplara bölündüğü daha karmaşık tabakalı tasarımlara kadar yaygın anket düzenleri için tasarlanmıştır. Her iki tür sorunlu gözlemi birlikte kontrol ederek bu tahminciler, veriler ciddi biçimde kirlenmiş olsa bile nüfus ortalaması tahminini istikrarlı tutmayı amaçlar.
Yeni tahmincileri teste sokmak
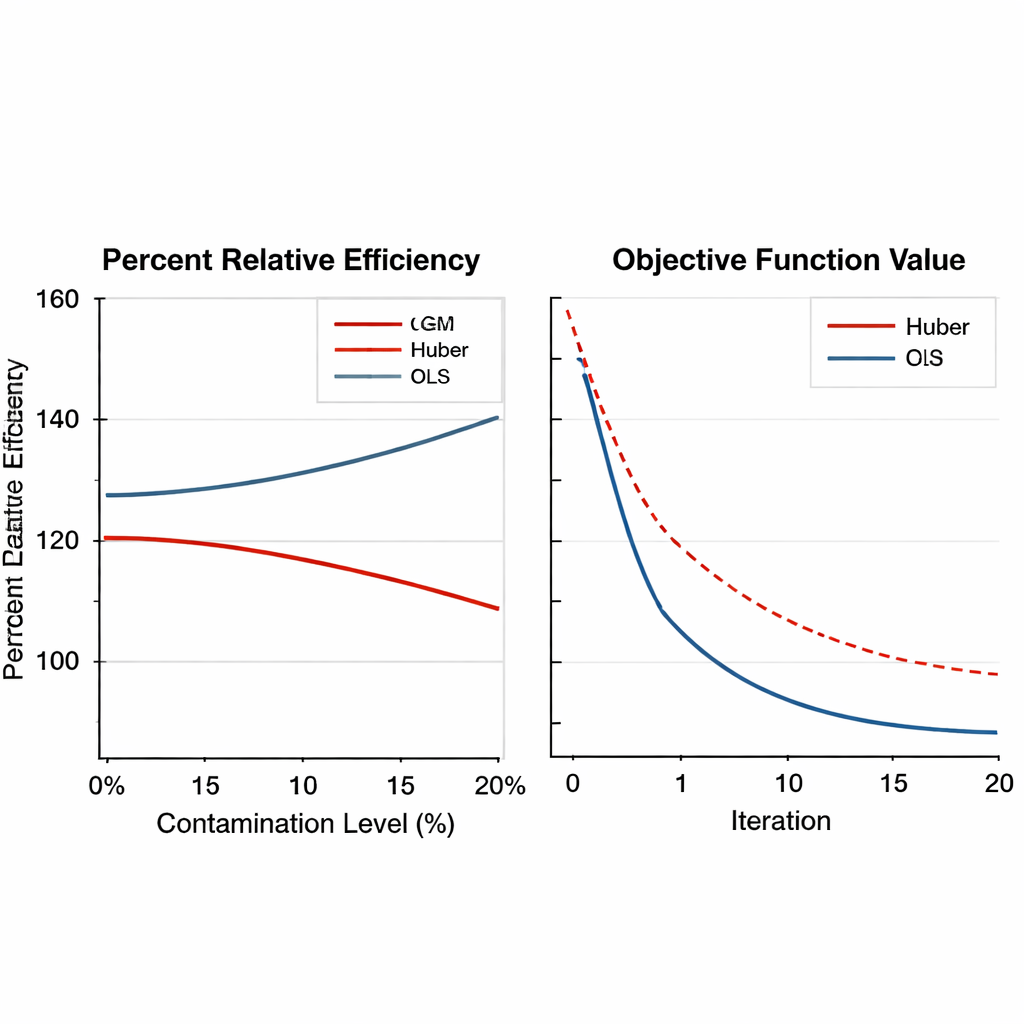
GM tabanlı tahmincilerin ne kadar iyi çalıştığını görmek için yazar kapsamlı sayısal deneyler yapar. Önce gerçek tütün tarımı verileri iki biçimde analiz edilir: temiz bir versiyon ve bir birimin aşırı değerlerle değiştirildiği kasıtlı olarak kirletilmiş bir versiyon. Yeni tahminciler, geleneksel regresyon ve Huber tabanlı sağlam yöntemlerle karşılaştırılır; karşılaştırmada tahmin hatasının ne kadar küçüldüğünü yansıtan yüzde göreli verimlilk ölçütü kullanılır. Geniş bir örneklem boyutu aralığında GM tahminciler, özellikle veriler aşırı değerler içerdiğinde eski yöntemleri tutarlı biçimde geride bırakır. Bazı senaryolarda en iyi performans gösteren GM tahminci, Huber yaklaşımına kıyasla hatayı %50’den fazla azaltır.
Tasarımlar, ortamlar ve ayar seçimleri arasında sağlamlık Figure 2.
Makale daha sonra testleri büyük ölçekli bilgisayar simülasyonlarıyla genişletir. Yapay popülasyonlar birkaç dağılım biçimi—normal, çarpık ve kuyrukları ağır—altında oluşturulur ve aykırıların değişen oranlarıyla, sıfırdan %20’ye kadar kirletilir. Hem basit hem de tabakalı örnekleme planları göz önüne alınır ve ana değişken ile yardımcıları arasındaki ilişkinin gücü zayıftan güçlüye değiştirtilir. GM tahminciler ağır kirlenme altında bile üstünlüklerini korur; sıklıkla %150’nin üzerinde verimlilik kazanımları elde ederler ve sayısal yakınsama açısından da düzgün ve güvenilir performans gösterirler. Önemli olarak, dahili ayarların makul aralıklar içinde değiştirilmesi performanslarını çok az etkiler; bu da uygulayıcıların her yeni anket için bunları hassas şekilde ince ayar yapmaları gerekmediği anlamına gelir.
Gerçek dünya anketleri için bunun anlamı nedir
Düz anlatımla, makale önerilen GM tabanlı tahmincilerin kusurlu örnekleri nüfus geneli ortalamalarına çevirmenin daha güvenli bir yolunu sunduğunu gösterir. İdeal, temiz veri koşullarında klasik yöntemler kadar doğrudurlar. Ancak veriler ölçüm hataları, yanlış bildirilen değerler veya nadir aşırı olaylar içerdiğinde—ulusal anketlerde, çevresel izlemede ve finansal istatistiklerde olduğu gibi—çok daha güvenilir sonuçlar verirler. Hesaplama açısından uygulanabilir olduklarından ve farklı tasarımlar ve ortamlarda iyi çalıştıklarından, bu tahminciler anket uygulayıcılarına gerçek dünya verilerinin kaçınılmaz dağınıklığına karşı kanıta dayalı kararların daha dayanıklı olmasını sağlayacak pratik bir yükseltme sunar.
Atıf: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5