Clear Sky Science · tr
Hassas taburculuk özeti üretimi: kendi kendini değerlendiren ince ayarlı büyük dil modelleri kullanımı
Hastanedeki evrak işinin gerçekten neden önemli olduğu
Bir hasta hastaneden ayrıldığında, hastalığın öyküsü çıkış kapısında bitmez. Diğer kliniklerdeki doktorlar, aile hekimleri ve hastanın kendisi, hastanede neler olduğunu ve sonraki adımda ne yapılması gerektiğini anlamak için taburculuk özeti adı verilen kritik bir belgeye güvenir. Ancak bu özetleri yazmak yavaş ve tekrarlayıcı bir iştir; yoğun hekimler için hasta başına yarım saat veya daha fazla sürebilir. Bu çalışma, modern yapay zeka dil araçlarının taburculuk özetlerini daha hızlı ve daha doğru taslak hâline getirmeye nasıl yardımcı olabileceğini, aynı zamanda hasta verilerini gizli ve hastane kontrolünde tutmayı nasıl sağlayabileceğini araştırıyor.
Dağınık kayıtları net bir öyküye dönüştürmek
Hastane bilgileri birçok elektronik sistemde dağılmıştır: laboratuvar sonuçları bir tabloda, ameliyat notları başka bir yerde, hemşire gözlemleri üçüncü bir yerde vb. Her hastanın yatışı binlerce küçük metin parçası üretir. Araştırmacılar önce bu dağınık, dağınık bilgiyi bir yapay zeka modelinin anlayabileceği temiz girdiye dönüştüren bir iş akışı kurdular. Örtüşen kayıtları birleştirme ve yinelenenleri eleme, isimler ve kimlikler gibi özel ayrıntıları filtreleme, yazım hatalarını düzeltme ve tıbbi terimleri standartlaştırma yöntemleri kullanarak her yatış için yapılandırılmış giriş oluşturuldu. Bu süreç, büyük bir Çin hastanesinde tiroid cerrahisi geçirmiş 6.000'den fazla hastanın verilerine uygulandı ve gerçek taburculuk özetleri ile bunların yazıldığı ham verilerin eşleştirilmiş örnekleri üretildi. 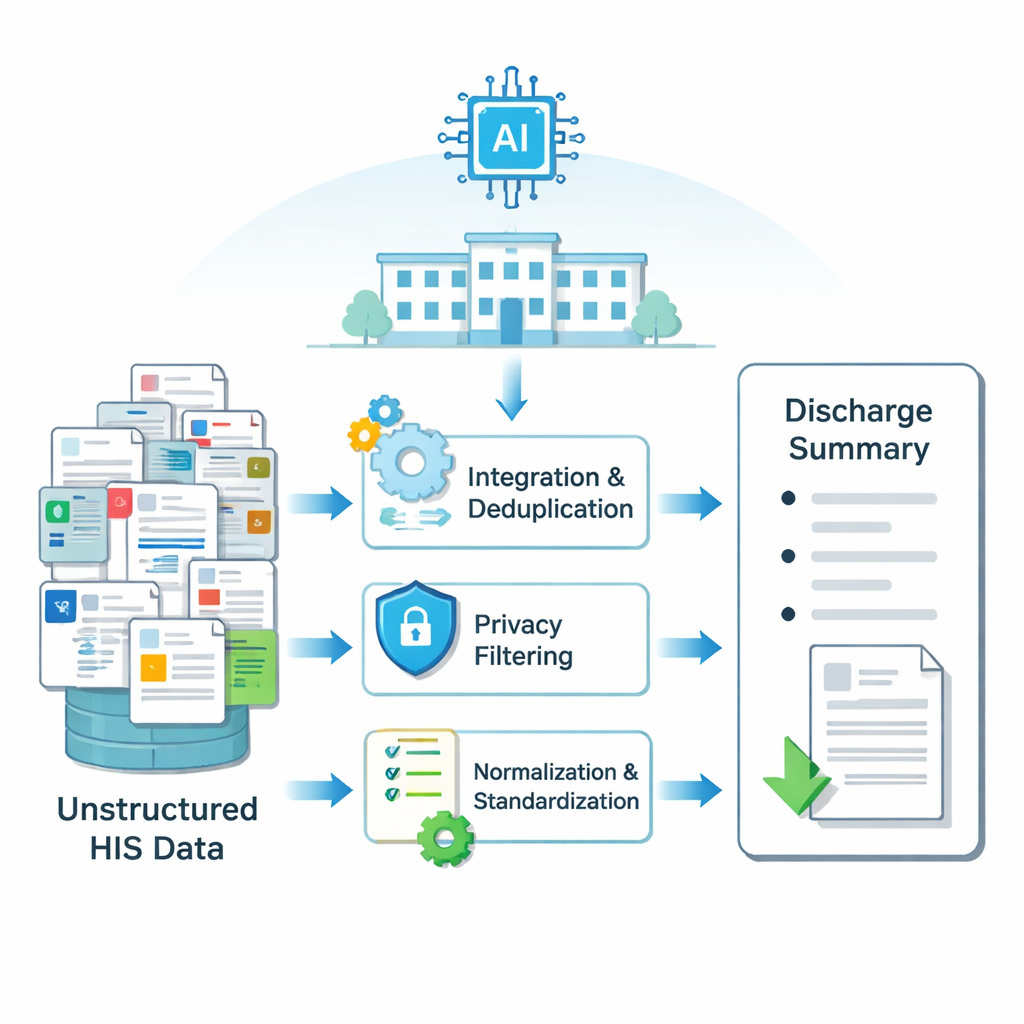
Yapay zekayı tıbbın dilini konuşacak şekilde ince ayarlama
Hazır büyük dil modelleri internet ve kitaplardan gelen genel metinlerle eğitildiği için sık sık uzmanlaşmış tıbbi dil ve yerel dokümantasyon stilleriyle zorlanır. Ekip, mevcut modelleri Çince tıbbi kayıtları daha iyi anlaması için "ince ayarlamanın" birkaç yolunu karşılaştırdı. Ağırlık ayrıştırmalı düşük rang uyarlaması olarak adlandırılan yeni bir yöntem (DoRA), LoRA ve QLoRA gibi eski tekniklere kıyasla modelin iç ağırlıklarını daha hedefli bir şekilde ayarlar. Qwen2, Mistral ve Llama 3 dahil çeşitli modellerde DoRA, daha akıcı, insan yazımı özetlere anlamca daha yakın ve daha az karışıklık gösteren (standart bir ölçüt olan perplexity ile ölçüldüğünde) özetler üretti. Özetle, DoRA modeli tıbbi ifade ve terminoloji öğrenmesi için yardımcı oldu; bunun için büyük donanımlarda tam bir yeniden eğitime ihtiyaç yoktu.
Yapay zekaya kendi işini çift kontrol etmeyi öğretmek
İyi eğitilmiş bir model bile uzun bir özeti tek seferde yazarken önemli ayrıntıları unutabilir veya küçük hatalar yapabilir. Hızlı "Sistem 1" düşüncesi ile daha yavaş, dikkatli "Sistem 2" muhakemesine dair psikolojik fikirlerden esinlenerek yazarlar bir kendi-kendini değerlendirme döngüsü tasarladı. Önce model işlenmiş hastane verilerinden bir ilk taburculuk özetini yazar. Ardından orijinal veriler patoloji bulguları, hekim yazıları veya laboratuvar panelleri gibi segmentlere bölünür ve her segment taslak özetle yeniden eşleştirilir. Modele, etkili olarak "Bu segmentteki her şey özetle yansıtılmış mı?" sorusu yöneltilir. Değilse, eksik veya tutarsız bilgileri eklemek için metni düzeltir. Bu döngü üç defaya kadar veya model özeti tamam olarak değerlendirene kadar tekrarlanır ve hastanın kaydıyla daha sadık bir şekilde eşleşen rafine edilmiş bir versiyon üretilir. 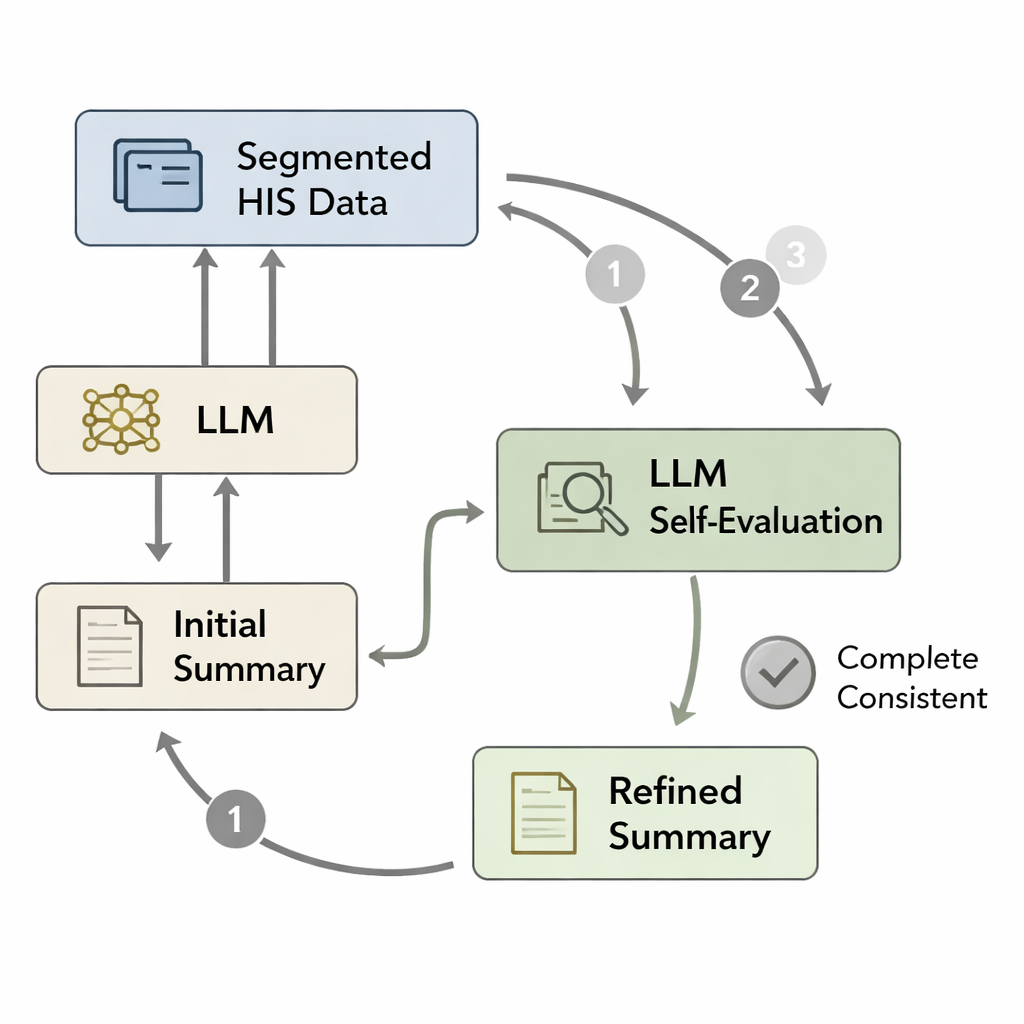
Yapay zeka insanlar ile karşılaştırıldığında ne kadar iyi performans gösterdi?
Kaliteyi değerlendirmek için ekip hem otomatik puanlar hem de insan değerlendiriciler kullandı. Doktorlar ve tıbbi araştırmacılar özetleri doğruluk, bütünlük, açıklık, tutarlılık ve devam eden bakım için faydalılık açısından puanladılar. DoRA ince ayarı ile kendi-kendini değerlendirme döngüsünü birleştiren en iyi sistem, tüm ölçütlerde insan yazımı özetlere en yakın sonuçları verdi. Özellikle bütünlükte iyileşme sağladı; yani kaçırılan tanı, tedavi veya önemli laboratuvar değerleri daha azdı. Ayrıntılı bir örnekte, yapay zeka başlangıçta küçük bir tiroid kanserinden ve belirli bir hormon hapından bahsetmeyi unutmuştu; iki kendi-değerlendirme geçişinden sonra her iki ayrıntı da doğru şekilde eklendi. Ortalama olarak sistem, bir hastane sunucusunda yaklaşık 80 saniyede bir taburculuk özeti üretti; oysa bir hekimin sıfırdan taslak oluşturması 30–50 dakika sürüyordu, fakat metin resmi kayda girmeden önce insan incelemesi hâlâ gerekliydi.
Bu hastalar ve klinisyenler için ne anlama gelebilir?
Çalışma, dikkatli eğitim ve yerleşik kendi-kendini kontrol mekanizmalarıyla yapay zeka sistemlerinin, hızlı bir insan incelemesinden sonra klinik olarak kabul edilebilir düzeyde doğru taburculuk özetleri üretebileceğini gösteriyor. Bu doktorların yerini almaz, ancak onların zamanını tekrar eden yazmaktan alıp daha üst düzey gözden geçirme ve karar vermeye kaydırabilir. Tüm hesaplamayı hastane ağı içinde tutarak ve tanımlayıcı ayrıntıları çıkararak bu yaklaşım hasta gizliliğine de saygı gösterir. Şimdiye kadar elde edilen sonuçlar tek bir hastanenin tek bir bölümünden gelirken, çerçeve yapay zekanın karmaşık tıbbi verileri birçok uzmanlık alanında net, güvenilir anlatılara dönüştürmesine; bakım devirlerinde güvenliği artırmaya ve hastalar ile ailelerinin daha iyi anlamasına katkıda bulunmaya işaret ediyor.
Atıf: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Anahtar kelimeler: taburculuk özetleri, tıbbi yapay zeka, büyük dil modelleri, klinik dokümantasyon, kendi kendini değerlendirme