Clear Sky Science · tr
Bağlam açısından ilgili biyomedikal varlıkların yerleşik büyük dil modelleriyle otomatik tanımlanması
Tıbbi makalelerin daha akıllıca etiketlenmesi neden önemli
Her yıl, genler, hücre tipleri, hastalıklar ve tedaviler hakkında ayrıntılarla dolu binlerce biyomedikal çalışma yayımlanıyor. Ancak bu bilgilerin çoğu uzun PDF’lerde kilitli kalıyor ve diğer araştırmacıların ihtiyaç duydukları kesin verileri bulmasını zorlaştırıyor. Bu makale, modern yapay zekânın — büyük dil modellerinin (LLM’ler) — araştırma makalelerinden bu temel biyomedikal terimleri otomatik olarak nasıl çıkarabileceğini ve dağınık yayınları iyi düzenlenmiş, aranabilir kaynaklara dönüştürmeye nasıl yardımcı olabileceğini inceliyor.
Dağınık makalelerden aranabilir yapı taşlarına
Almanya’daki Collaborative Research Centers gibi biyomedikal araştırma merkezleri, çalışmaların yıllarca yeniden kullanılabilir olması için açık, yapılandırılmış verilere bağımlıdır. Geleneksel olarak araştırmacılar, organizmalar, hücre hatları ve genler gibi önemli varlıkları veri setlerine elle etiketlemek zorundaydı; bu zahmetli ve zaman alıcı bir işti. LLM’ler tam metinleri okuyup bağlamı anlayabildikleri için bu etiketlemeyi otomatikleştirmek adına umut verici araçlardır. Ancak bir uyarı var: hangi terimlerin gerçekten ilgili sayılacağı, bilimsel soruya ve verinin nasıl yeniden kullanılacağına bağlıdır. Yazarlar, AI’ya hangi tür varlıkların aranacağını ve nasıl düzenleneceğini söyleyen, nefroloji odaklı CRC “NephGen” için özenle tasarlanmış bir meta veri şeması içinde çalışıyorlar.
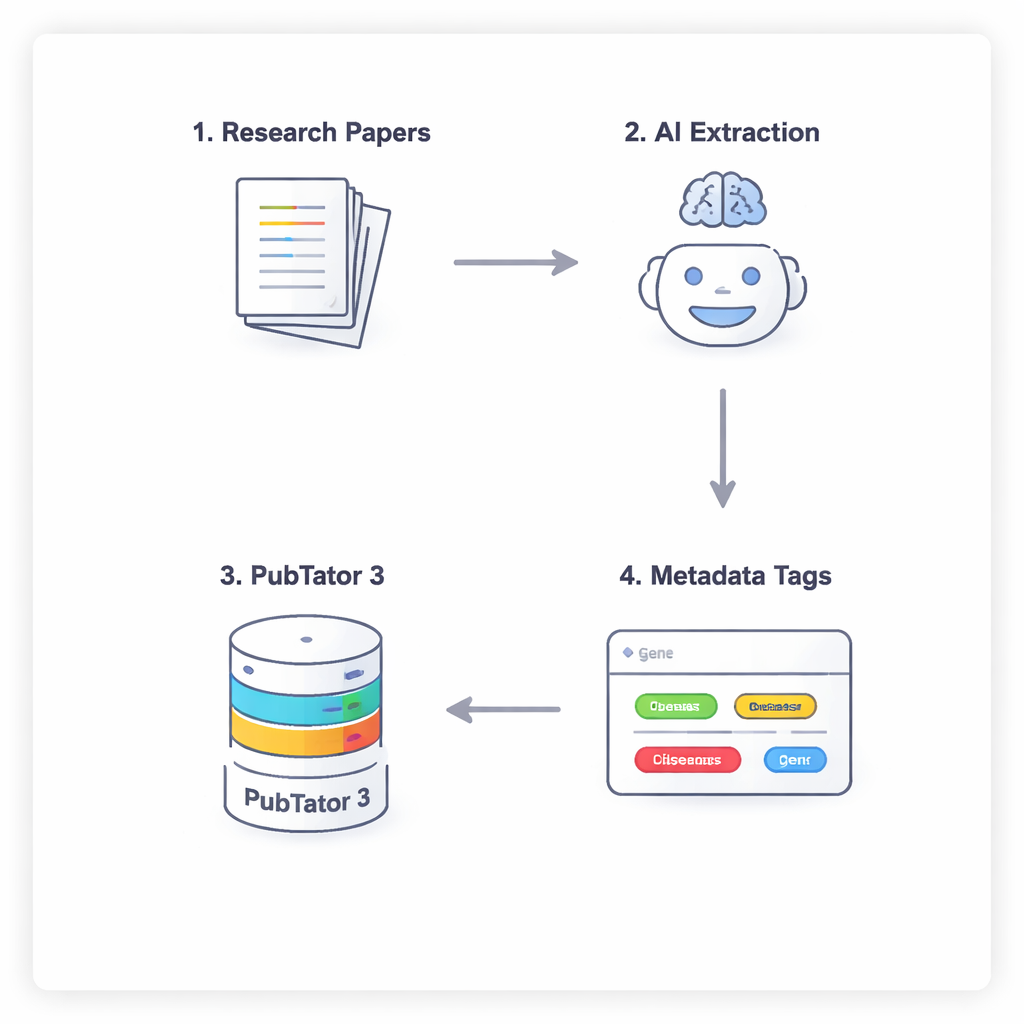
Yapay zeka ile biyoloji veri tabanı arasında dört adımlı bir konuşma
AI’nın biyomedikal gerçekleri basitçe tahmin etmesini ya da “halüsinasyon” yaratmasını engellemek için araştırmacılar, modelleri dikkatli düşünmeye ve kendilerini çift kontrol etmeye zorlayan dört adımlı bir süreç kullanıyorlar. İlk olarak, model bir makalenin tam metnini (tartışma ve kaynakları görmezden gelerek) tarayıp potansiyel olarak ilgili varlıkları öneriyor. İkinci olarak, önerilen her terimin gerçekten var olup tanınmış bir tanımlayıcıya sahip olduğunu doğrulamak için PubTator 3 gibi dış bir aracı, büyük bir biyomedikal veri tabanını kullanması gerekiyor. Üçüncü olarak, AI doğrulanmış her bir varlığı NephGen meta veri şemasındaki bir yuvaya atıyor; bu şema varlıkları hiyerarşik, insan tarafından tasarlanmış bir yapıda gruplayan bir düzen sunuyor. Son olarak model, tüm bunları yapılandırılmış bir JSON çıktısında birleştiriyor; temel biyomedikal varlıkların makale içindeki düzenli, makine tarafından okunabilir bir özeti ortaya çıkıyor.
Gerçek böbrek araştırmalarıyla sekiz AI modelini test etmek
Ekip, bu iş akışını 14 farklı LLM için API’ler kullanarak uyguladı ve yalnızca sekizinin geçerli JSON döndürme ve araçları doğru kullanma gibi katı gereksinimleri güvenilir şekilde izleyebildiğini buldu. Ardından bu sekiz modeli altı nefroloji araştırma makalesine uyguladılar ve her makalenin yazarıyla kısa yüz yüze görüşmelerde AI’nın nihai varlık listelerini gözden geçirmelerini istediler. Çıkarılması gereken “doğru” varlık sayısı sabit olmadığından, yazarlar duyarlılığa (precision) odaklandı: önerilen varlıkların hangi oranının bilim insanları tarafından doğru kabul edildiği. Yüzde 100’e yakın oranlar için uyarlanmış istatistiksel meta-analiz yöntemleri kullanarak, makaleler arasındaki değişimi hesaba katarak her model için duyarlılığı tahmin ettiler.
Yüksek doğruluk, ancak emek, maliyet ve hız konusunda ödünler
Tüm modeller boyunca AI sistemleri, önerilen varlıkların büyük çoğunluğunun doğru olduğunu gösteren yaklaşık %91 genel duyarlılık elde etti. GPT-4.1, GPT-4o Mini ve Gemini 2.0 Flash en yüksek duyarlılığa sahipti — yaklaşık %94 ila %98 aralığında — ancak aralarındaki farklar istatistiksel olarak net değildi. Gemini modelleri genellikle daha fazla varlık önerme eğilimindeydi; bu da daha fazla doğru etiket sağlarken insanlara daha fazla kontrol bırakıyordu. GPT-4.1 Nano gibi daha küçük veya daha ucuz bazı modeller daha hızlı ve ekonomik olsa da belirgin şekilde daha az doğruluydu. Yazarlar, bu gerilimleri Pareto sınırları kullanarak görselleştirdiler ve doğruluk, doğru varlık sayısı, maliyet ve işlem süresi arasında dengeler sunan model kombinasyonlarını belirlediler: örneğin, hem doğruluk hem de düşük maliyet öncelikliyse GPT-4o Mini özellikle cazip çıktı.
İnsanların hâlâ iş akışında olmasının nedeni
Güçlü performansa rağmen, çalışma önemli sınırlamalara dikkat çekiyor. Modeller bazen yayımlanan makaleye ilişkin bilgileri, gelecekteki kullanıcıların yeniden kullanmak isteyebileceği temel veri setiyle gerçekten ilgili olmayan ayrıntılarla karıştırdı. Bu karışıklık, otomatik metin madenciliğinde daha geniş bir sorunu yansıtıyor: bilimsel makaleler paylaşılan bir veri setinde yer almayan çok daha fazla şey tartışır. Bu nedenle yazarlar, AI tarafından üretilen açıklamaların yayımlanmadan önce insan uzmanlarca gözden geçirilmesine devam edilmesini öneriyor. Ayrıca değerlendirmelerinin yalnızca altı nefroloji makalesini kapsadığını ve alanlar arası daha geniş testlerin gerektiğini belirtiyorlar. Zamanla, rutin bir “insan-döngüde” iş akışı bir fikir birliği referans seti oluşturabilir ve sadece duyarlılığı değil AI’nın kaçırdığı varlık sayısını da ölçmeyi mümkün kılabilir.
Gelecekte biyomedikal veri paylaşımı için ne anlama geliyor
Çalışma gösteriyor ki, dikkatle yönlendirildiğinde ve güvenilir veri tabanlarına dayandırıldığında modern LLM’ler biyomedikal makalelerin açıklanmasında güvenilir biçimde yardımcı olabilir ve araştırmacıların elle yaptığı iş yükünü büyük ölçüde azaltabilir. En iyi modeller uzman düzeyine yaklaşan duyarlılık sunarken titizlik, maliyet ve hız arasında çeşitli ödünler sunuyor. Şimdilik açıklamaların gerçekten veri setleri ve araştırma bağlamıyla eşleşmesini sağlamak için insan denetimi zorunlu olmaya devam ediyor. Ancak araçlar ve açık kaynak modeller geliştikçe, bu tür iş akışları bugünün tıbbi makale selini yarının iyi düzenlenmiş, yeniden kullanılabilir veri ortak varlıklarına dönüştürmenin standart omurgası haline gelebilir.
Atıf: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Anahtar kelimeler: biyomedikal metin madenciliği, büyük dil modelleri, meta veri açıklama, yerleşik yapay zeka, nefroloji araştırması